

A Simple LLM Primer and Book launch
Seven months in the making


This week’s newsletter is brought to you by an active community of 3,000+ members that learn together and help each other grow. The Small Bets community is the place to be if you’re looking to grow your creative endeavors and be inspired by some of the best builders on the internet. No recurring fees. Pay once, and you'll get lifetime access to everything.
Today, I'm excited to announce my book AI for the Rest of Us has launched
I originally imagined this as a shortish 30k-word book. Instead, it's expanded into a 54k-word, 300-page book complete with 110 hand-drawn illustrations. It's taken me seven sleepless months to get it over the finish line, and I'm delighted to have finally finished it.
How you can help me
If you feel inclined to support my book launch (no obligations) and make it a success, I'd be highly honored. Here's how you can help:
Invite friends to order the book: If you know of friends or colleagues who'll benefit from this book and the bundles, please forward this email or share a link to the landing page.
Share on social media: If you ordered the book and/or are just really excited for me, share the landing page with your social network. Please tag me so that I can repost it.
Provide a testimonial: If my writing has helped you achieve something, or you simply enjoy it, share a sentence or two with your name, and I'll be honored to have it on the landing page.
Thank you so much for your support. I honestly couldn't have dreamt about doing any of this without your readership. I value your time and attention above all.
Related Update
I saved some of the beta readers for the print version of the book. All these amazing folks have received an email from me today requesting their aid in beta reading for the print version of the book.
Thanks again to everyone who volunteered. As I mentioned before, all beta readers will be acknowledged in the print version of the book and will receive a special gift from me once the book is sent for print.
Since we're going to be looking at language models for the next few editions, this week's essay is actually a related snippet from the book. Let's get started!
This Week on Gradient Ascent:
A Simple Primer on LLMs 📝
A Simple Primer on Large Language Models
Large language models, or LLMs, are called so because they have billions of parameters. The number of parameters strongly correlates with the model's capacity to learn from data and capture more complex patterns in it. Therefore, the more knobs it has, the more complex representations it can learn. In the case of these language models, size does seem to matter. So we know why they're called large language models. Are they really such a big deal? Well, kind of. They can do everything from writing essays, creating charts, writing code, and planning your next marketing campaign with limited or no supervision.
To drive this point home, play along with me on this thought experiment. Imagine you have a magic mouse (I did say imagine). By showing it examples of five tasks that you want to be done, no matter how difficult or different, you can train it to be a world-class expert at them. You don't need to show a lot of examples. Just a few will suffice. How awesome would that be?
Now imagine that you are given a magic cow. This cow can do the same five tasks as your magic mouse but better. Also, it can do five more new tasks that the mouse can't do. Even better, right?
Humor me once more and imagine that the gods have bestowed upon you a magic dinosaur. This can one-up the cow and do even better on the ten tasks that the cow could do and do another five new ones. Do you see where I'm going with this?
LLMs are remarkable because a single model can be used for several tasks. As the model's size increases (in parameters), it can learn more complex representations and, therefore, can do more tasks better than a smaller model. Moreover, they can learn new tasks from just a handful of examples. These tasks can be any of the things I mentioned before and more! That's why researchers are trying to scale these models up.
The Types of LLMs
We've seen why LLMs are large. But do all LLMs have the same underlying architecture? Is it only their size that has changed? Nope. While the original Transformer model had both an encoder and a decoder, researchers have found situations where just using the encoder, or decoder alone, is the best option. Some modern LLMs use both, though.
This is an important consideration since this directly affects how these models are trained. Broadly, there are three categories based on the underlying architecture:
Encoder-Based
These types of models only use the encoder from the original Transformer. They are also called auto-encoding Transformer models. BERT (Bidirectional Encoder Representations for Transformers) is an example of this category. The self-attention layers within these models can look at all parts of the input, just like the encoder from the original Transformer. As these models are trained in a way that helps them understand entire bodies of text, they are great for tasks like sentiment analysis, sentence classification, and extractive question answering.
Decoder-Based
As the name implies, these models only use the decoder from the original Transformer. They are also called auto-regressive Transformer models. The GPT (Generative Pretrained Transformer) family of models belongs to this category. The self-attention layers within these models can only look at parts of the input before the current token. Thus, they are trained to predict the next token in a sequence. This makes them great for generative tasks like text generation.
Encoder-Decoder Based
These models have both the encoder and decoder and are also called sequence-to-sequence Transformer models. T5 (Text-To-Text Transfer Transformer) and BART (Bidirectional and Auto-Regressive Transformer) are examples of this class. Self-attention layers in the encoder can look at all parts of the input, while those in the decoder can only look at the parts that have occurred just before the current token. These are great for summarization, translation, and generative question answering.
Training an LLM
All of this is well and good. But these models are enormous. Naturally, the training process must be complicated, right? Not exactly. Fundamentally, all these models are trained to predict the next word in a sentence - Yes, similar to autocomplete on your phone. Wait, what? So why do you need a large model and datasets for something this trivial? Let's look at that next.
These models learn in two stages— Pretraining and finetuning.
Pretraining
In the pretraining stage, the goal is to teach the model the semantics, structure, and grammar of language by showing it many examples (think billions). As is the case with machine learning, we simply show examples to the model and let it learn the rules by itself.
Pretraining is the longest and most computationally expensive part of the learning process. It requires petabyte-scale datasets and loads of computation power. A model is repeatedly shown examples from these datasets and eventually learns the rules. So, how does it learn?
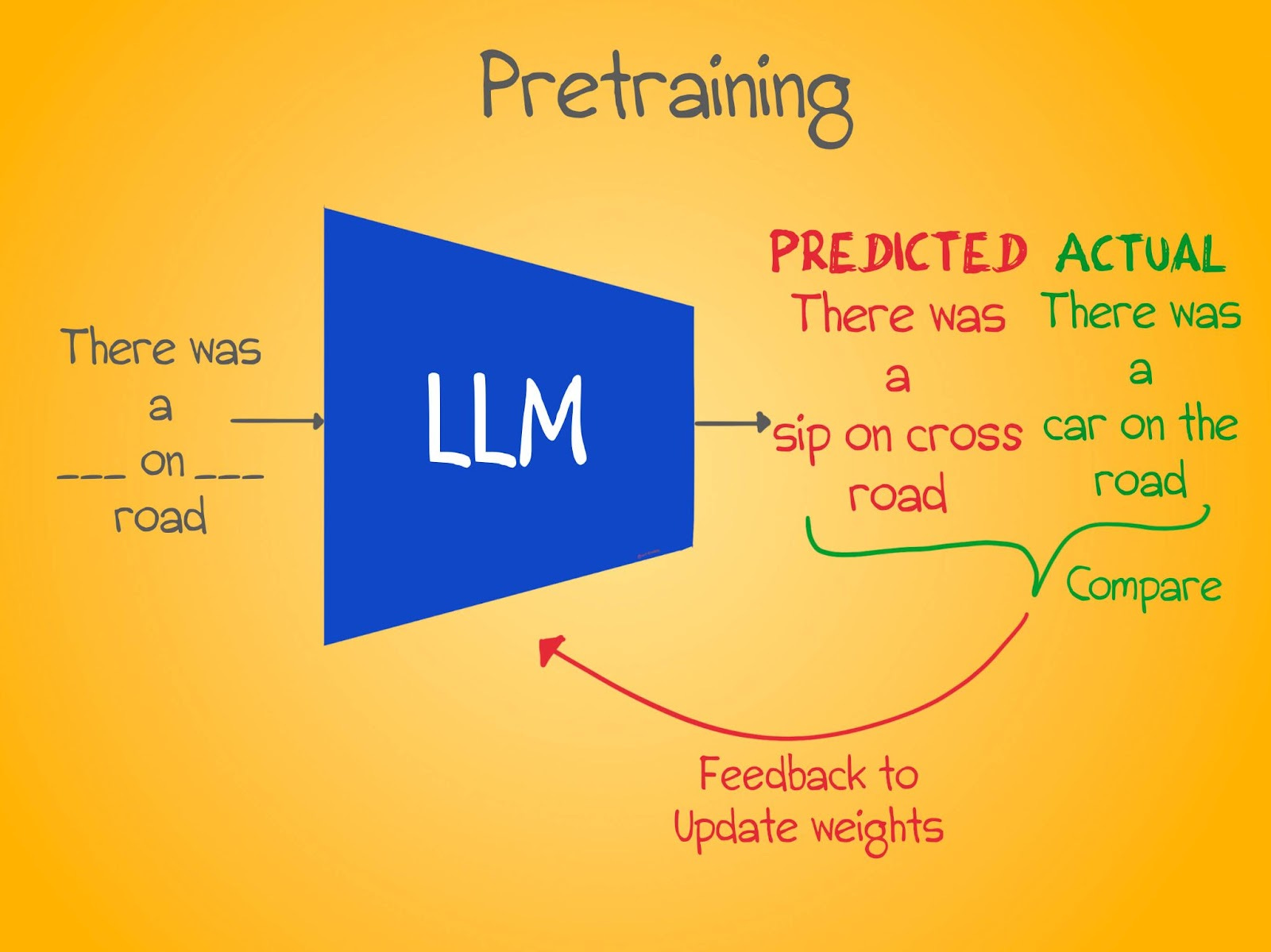
Depending on the type of model, pretraining can be done in a number of different ways. Here are a few common ones.
Auto-Regressive Language Modeling
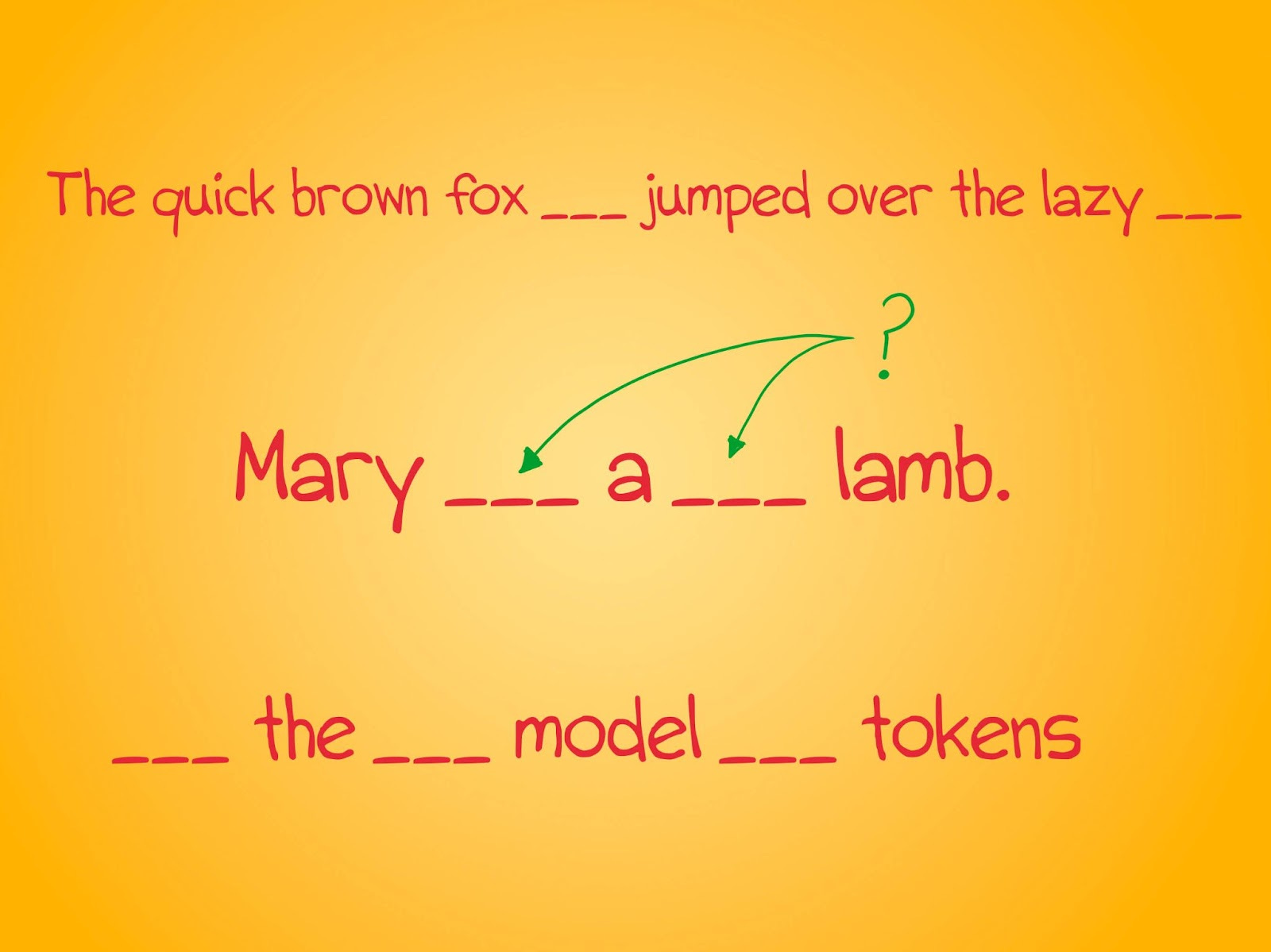
Look at the sentences below. What comes next? This is one of the ways in which decoder-based models like GPT are pretrained. Given a partial sentence, they have to predict the next word in the sentence and then the next, and so on. Even though we may have a complete sentence to show the model, we don't. This prevents the model from cheating and looking into the next set of words that may occur in the sentence.

Masked Language Modeling
Let's try that exercise again. Can you complete the sentences here? You might have had luck guessing the first two, but the third might be tricky. This is called masked language modeling. In this approach, we randomly blank out words in a sentence and have the model guess what those words might be. Unlike the previous approach, we present a full (but blanked out) sentence to the model so it can learn from words on either side of the blanks. Autoencoding models like BERT are pre-trained using this approach.
Next Sentence Prediction
Does the second sentence in the examples below follow the first sentence? In this exercise, the model has to guess if two sentences follow each other or if they are entirely random.

There are many more pretraining tasks, but the idea is the same. By doing this repeatedly on a ridiculously large dataset, these models learn rich representations of language. Did you notice something? We used only the input data to train the model in the pretraining tasks above. We didn't use any labels. So, yes, these are examples of self-supervised training.
The models that we get at the end of the pretraining stage have recently been dubbed "foundation models" by some of the research community. In other words, they are trained on a humongous dataset and can be adapted to a variety of specific tasks.
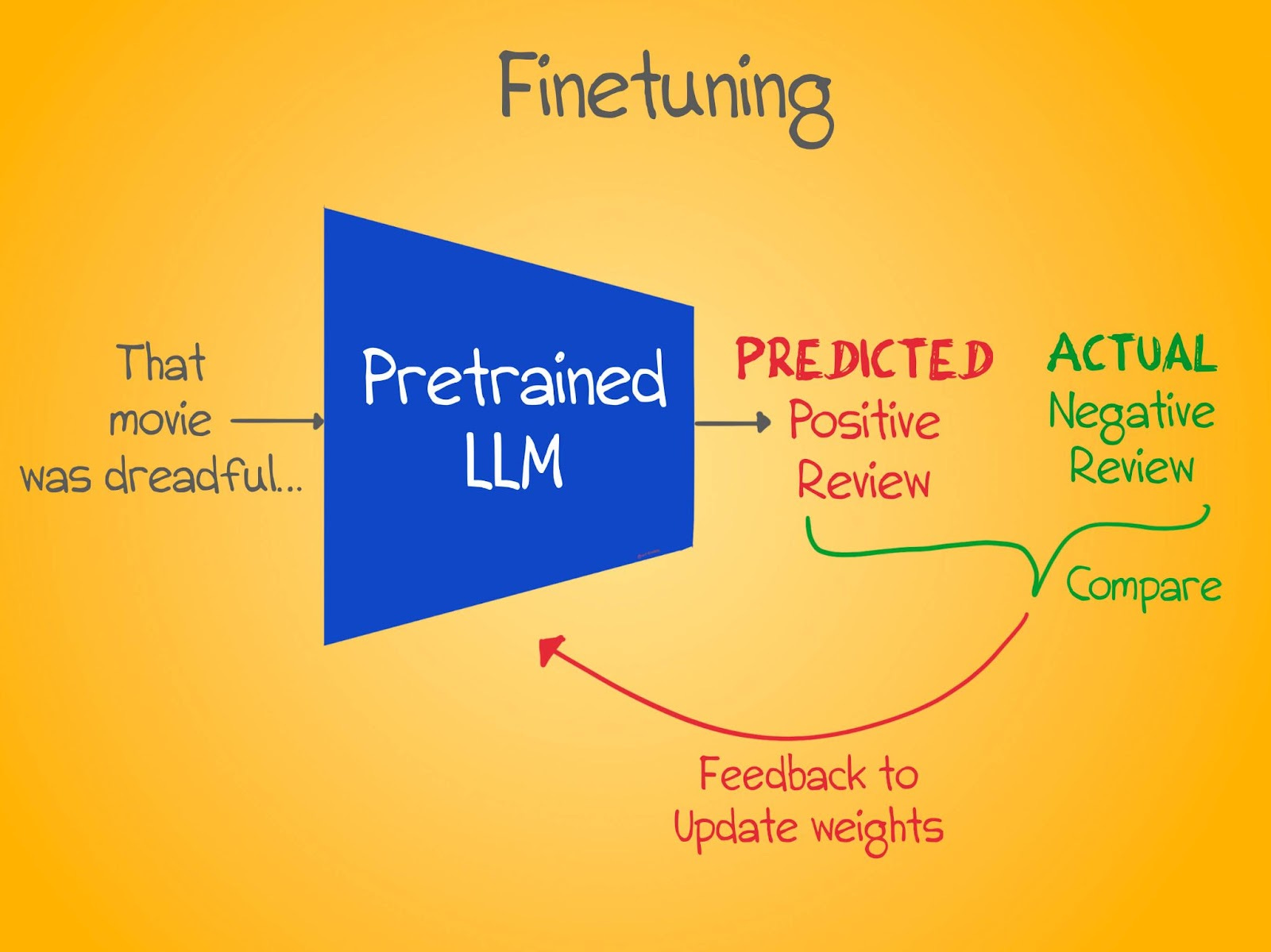
Finetuning
In the second phase, called finetuning, we can take a pretrained model and show it a few examples of the task we want it to solve. This can be question answering (who is Neil Armstrong?), sentiment analysis (was that tweet mean?), conversation, and so on. This stage usually takes much less time and data than the pretraining phase, which is why these pretrained models are invaluable.
But that raises the question - "Where do you get all that data for pretraining?"
Datasets for Pretraining an LLM
How smart would you be if you took all the books in the world, all of Wikipedia, all known research papers, code repositories, and all of the text you can get by crawling the web and ingesting that knowledge? Pretty smart, right? Well, that's what these models are pretrained on. In the pretraining phase, these models are trained on all of these datasets (amounting to just short of the collective human consciousness). That's another reason why they are large by design. Smaller models are limited in what they can learn.
In the fine-tuning phase, smaller in-house datasets relevant to your application are used. So if you wanted to train a model to review customer feedback, you'd have a small dataset of reviews to fine-tune the model. The critical point here is that these finetuning datasets are several orders of magnitude smaller than the pretraining datasets.
Limitations
LLMs have some limitations, though. First, only a few well-funded organizations can train these models since they require substantial computational resources (costing hundreds of thousands of dollars). Second, they have significant environmental impacts since the energy it takes to train these models amounts to several years of electricity consumption for an average household.
Even though these models can perform many tasks, they do not "understand" the tasks or the text in the same way a human does. Their responses are based on patterns they've learned during training, not on actual understanding.
Moreover, as LLMs are trained on data from the internet, they can unknowingly absorb and perpetuate biases present in that data. They might also inadvertently learn and propagate toxic or harmful content.
Despite their vast knowledge, LLMs may struggle with handling out-of-distribution data — data that is different from what they were trained on. Also, for some LLMs, controlling the generation of inappropriate content can be challenging due to their autoregressive nature.
Lastly, given how proficient these models are at generating human-like text, they could be exploited to spread disinformation, a significant concern that needs addressing. Researchers worldwide are currently working on finding solutions to these issues.
LLMs represent a monumental leap in the field of NLP. Despite their limitations, these models have ushered in an era of unprecedented possibilities and are a testament to the power of AI.
However, as we continue to scale these models and extend their capabilities, addressing the challenges they present is imperative — be it ethical, computational, or environmental. The journey to perfecting these AI behemoths is far from over. There are many more breakthroughs to come, and with them, a chance to shape a future where AI models are not just large but also responsible and beneficial to all.
Hope you enjoyed reading this one. Next week, we'll look at what language models like BERT actually look at in bodies of text.
Any update on the book? I love your style of writing and would enjoy reading the book but it seems unavailable.
Super pumped for your book launch, Sairam. I think this is the beginning of many things for you. I'm so excited to see what doors open up once the book gets its footing. I hope you'll write about that!