



A Tree-mendous Doodle: A Visual Explanation of Gradient Boosting
Gradient boosting is all you need. And coffee...

It's been a tough few weeks in the tech industry as layoffs rear their ugly head. I've seen many friends and colleagues impacted by this and it's been difficult to process this personally. If you are grappling with this and need to talk, or need connections or referrals, please reply to this email. I'll do my best to help you in any way I can.
My friend and engineering manager turned entrepreneur,
wrote about the current predicament more beautifully than I ever can here:There's no better way to be prepared than to invest in ourselves, and our personal growth. I hope for better times ahead.
This Week on Gradient Ascent:
Gradient boosting explained - the doodle edition 🎨
[Watch] How transformers behave in training vs test 📽️
[Try] Implement your own object detector from scratch 🧑💻
[Use] A nifty tool to build your own LLM applications 💻
[Consider reading] BERT style training for convolutional nets? 📜
[Consider reading] GANs make a comeback 📜
[Consider reading] Watermarking for large language models 📜
Poorly Drawn Machine Learning:
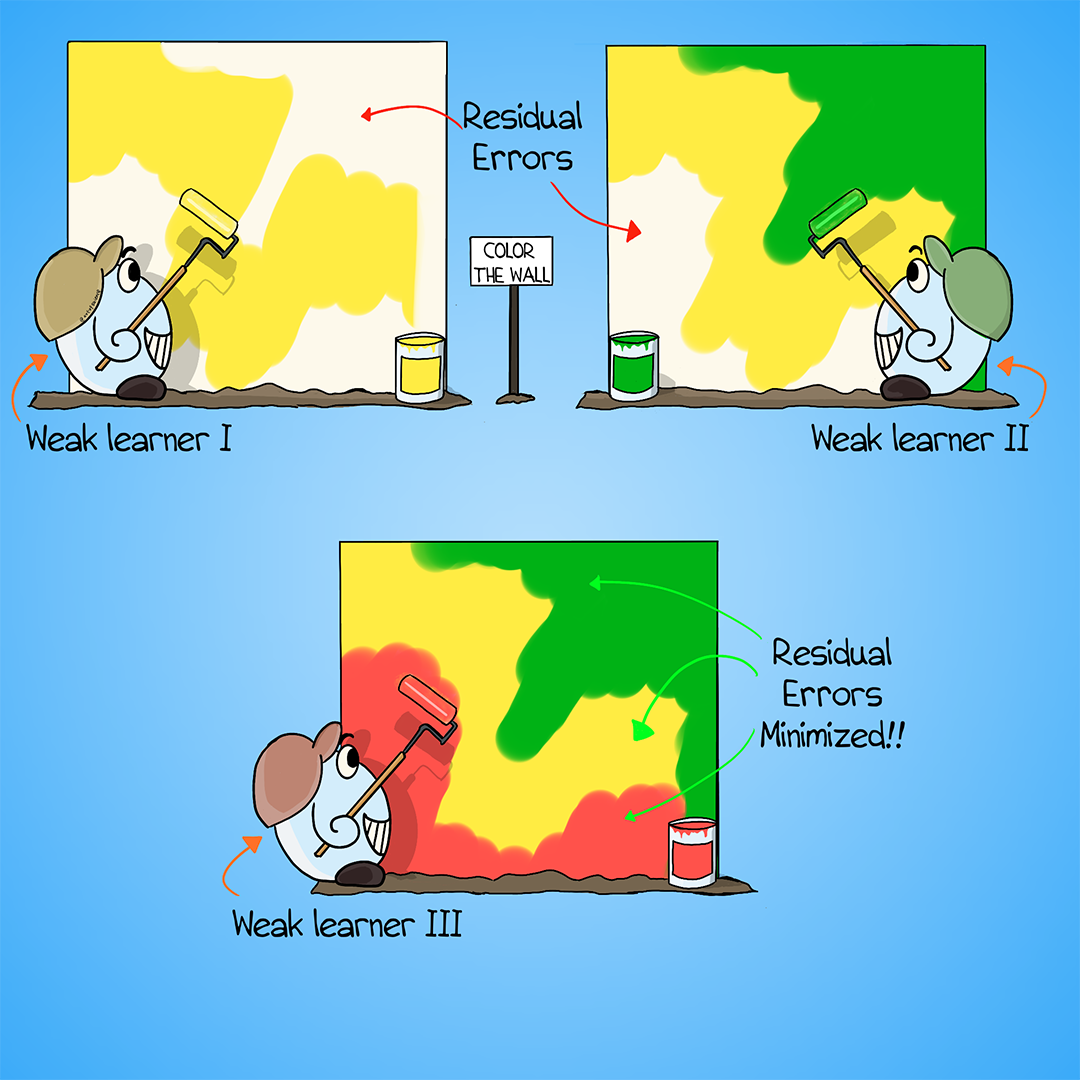
Gradient boosting is a versatile and powerful machine-learning algorithm. In simple terms, it's a way of combining many simple models (usually decision trees) to make a stronger and more accurate overall model. The idea is inspired by the wisdom of the crowd theory. This theory loosely states that the collective intelligence of large crowds outweighs that of individual experts.
How does it work?
In gradient boosting, one repeatedly adds new models to the mix (called an ensemble). Each new model (called a weak learner) is trained to correct the mistakes of the previous models. Specifically, each new learner is trained or fit on the residual error made by the previous learner.
The residual error is akin to the difference between the actual ground truth and the predicted value. By repeatedly adding learners to the ensemble to fix the predecessor's errors, we can minimize the overall error and thus obtain a strong model.
Useful concepts to learn
Loss function - A way to measure how well the model is doing. Examples: Mean-squared error, Mean-absolute error, Cross entropy, etc.
Gradient descent - The optimization process for gradient boosting. In gradient descent, we improve the model to make better predictions through small updates based on the gradient of the loss function (where Gradient boosting gets its name from incidentally).
Weak learner - A cog in the overall boosting machine. This is a simple model like a decision tree which isn't very accurate by itself (hence called weak). However, it yields a really powerful model when combined with other weak learners.
Boosting - The process of adding new learners to the ensemble and adjusting the weights of the previous learners.
Applications
Gradient boosting can be used both for regression and classification problems. It particularly shines for tabular datasets and is often a key component in many Kaggle competition-winning solutions.
If you'd like to learn more, check out this detailed deep dive.
Resources To Consider:
How transformers work at training vs inference
In this video, Niels Rogge, a machine learning engineer at HuggingFace walks through how a transformer network works during training time and inference time. This might be slightly advanced if you're not familiar with transformers, but it's really well put together.
Implement an object detector from scratch
Link: https://www.storminthecastle.com/posts/01_classification/
In this blog series, John Robinson walks through the process of building a single-shot object detector (YOLO/SSD) model using Pytorch and the FastAI library. He's released three parts so far and each one is chock full of details, visuals, and code. I highly recommend working through this yourself using the blog articles as a guide.


Building applications with LLMs
Link: https://github.com/hwchase17/langchain
We see new apps and solutions built using large language models every day. However, it's not a trivial process. Langchain aims to address this. Whether you want to build a chatbot, a Q & A agent for a notion database, or something completely different, check out this repository. It can help you develop these applications. All you need to do is "pip install" it :)
Mask pretraining for convolutional networks?
Paper: https://arxiv.org/abs/2301.03580
Code: https://github.com/keyu-tian/SparK
In this paper, the authors propose SparK which is the first BERT-style pretraining approach designed for convolutional networks (convnets). This is a really interesting breakthrough because it allows convnets to learn from "patches" without any modifications to the network architecture. To achieve this, the authors treat unmasked patches as flattened 3D point clouds. This allows them to apply sparse convolutions to encode them. Additionally, using SparK, results on standard convnets improve on downstream tasks.

Down but not out - The revenge of the GANs
Paper: https://arxiv.org/abs/2301.09515
Code: https://github.com/autonomousvision/stylegan-t
GANs have been surpassed by diffusion models in recent times in the generative domain. However, even the best diffusion models can only iteratively generate a single image. GANs can do it in a single pass. But they are far behind in the quality of the results. The model proposed in this paper, StyleGAN-T, addresses this issue and significantly improves over previous GANs. It actually outperforms distilled diffusion models - the previous state-of-the-art in fast text-to-image synthesis - in terms of sample quality and speed.
I know ChatGPT did your homework
Paper: https://arxiv.org/abs/2301.10226
Large language models can produce really convincing text output. Sometimes, this can be harmful, hallucinated, and can be misused. For example, how do you know if an article was written by a human or by a language model? This paper is one of the first steps in tackling this problem by watermarking text generated by a machine. The watermark can be embedded with negligible impact on text quality, yet can be easily detected by an open-source algorithm without access to the model or its parameters. This area will be really important in ensuring the safe use of language models for generative work. A very interesting paper worth reading.
GPTZero, which is an anti-plagiarism tool that was developed just prior to this work fails to be reliable as shown below.




