

AI Agents That Train Themselves, NVIDIA Cuts Training Costs 360x, and Meta's SAM 3D Wins 5:1: The Tokenizer Edition
This week's best AI resources

Hey there! Meta released SAM 3D, a model that generates complete 3D objects from a single photo with a 5:1 win rate against competing methods. Meanwhile, Agent0 proved you can train capable AI agents entirely from scratch without any human-curated data. Maybe self-evolution actually works when you give agents the right tools?
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Single-image 3D reconstruction that handles real-world clutter, self-evolving agents that need zero external data, cost-efficient model families from NVIDIA, and formal proofs of LLM scaling limits
🎥 Videos: Mapping open model progress, practical AI coding workflows, and surprising advances in small reasoning models
📰 Reads: How OpenAI is using evals to drive enterprise AI, Stanford’s CS336 study notes, and insights on policy distillation
🛠 Tools: Automated paper-to-agent systems and comprehensive ML systems resources
🎓 Learning: Google’s Nano Banana Pro (Gemini 3 Pro Image), the studio-quality upgrade to their viral image model
Grab my first book — AI for the Rest of Us — today!
Quick note: If you find the book useful, please leave a review on Amazon. It makes a world of difference. If you have a picture of the book IRL, please share it with me. I really appreciate it.
📄 5 Papers
SAM 3D: 3Dfy Anything in Images
https://arxiv.org/abs/2511.16624 | GitHub
Meta’s SAM 3D reconstructs full 3D geometry, texture, and layout from single images, focusing on real-world scenarios where objects are partially occluded or surrounded by clutter. The breakthrough comes from a human-and-model-in-the-loop pipeline that generated visually grounded 3D reconstruction data at unprecedented scale, combined with a multi-stage training framework that moves from synthetic pretraining to real-world alignment. Unlike methods that fail when objects are partially hidden, SAM 3D achieves at least a 5:1 win rate in human preference tests on real-world objects and scenes.
Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
https://arxiv.org/abs/2511.16043 | GitHub
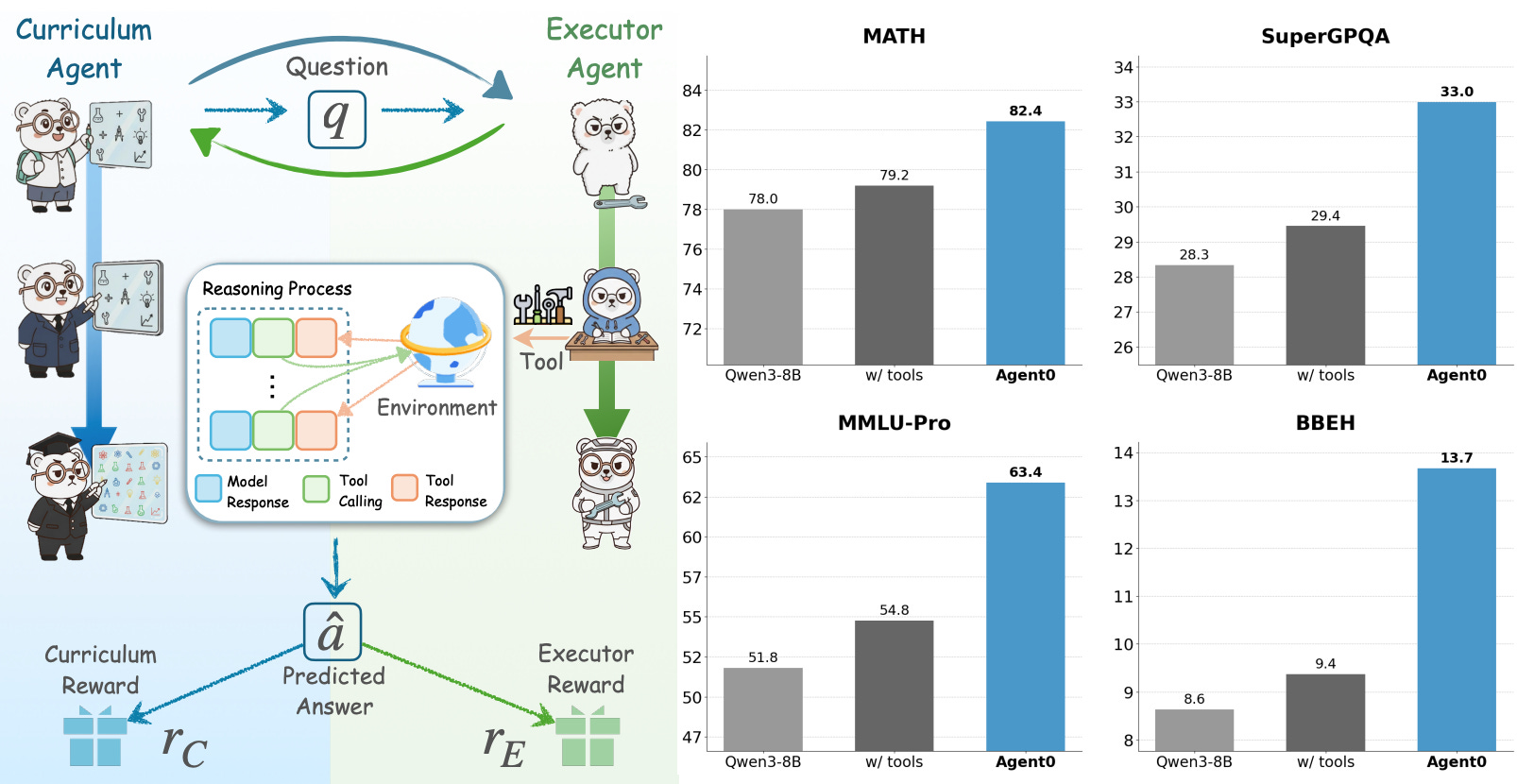
Training AI agents typically requires massive amounts of human-curated data, limiting both scalability and capabilities to what humans already know. Agent0 breaks this dependency through symbiotic competition between two agents: a curriculum agent that proposes increasingly complex tasks, and an executor agent that learns to solve them using external tools. The key insight is giving agents access to tools like Python interpreters, which provides problem-solving capabilities beyond the base model. This self-reinforcing cycle improved Qwen3-8B-Base by 18% on mathematical reasoning and 24% on general reasoning benchmarks, entirely without external training data.
Nemotron Elastic: Towards Efficient Many-in-One Reasoning LLMs
https://arxiv.org/abs/2511.16664
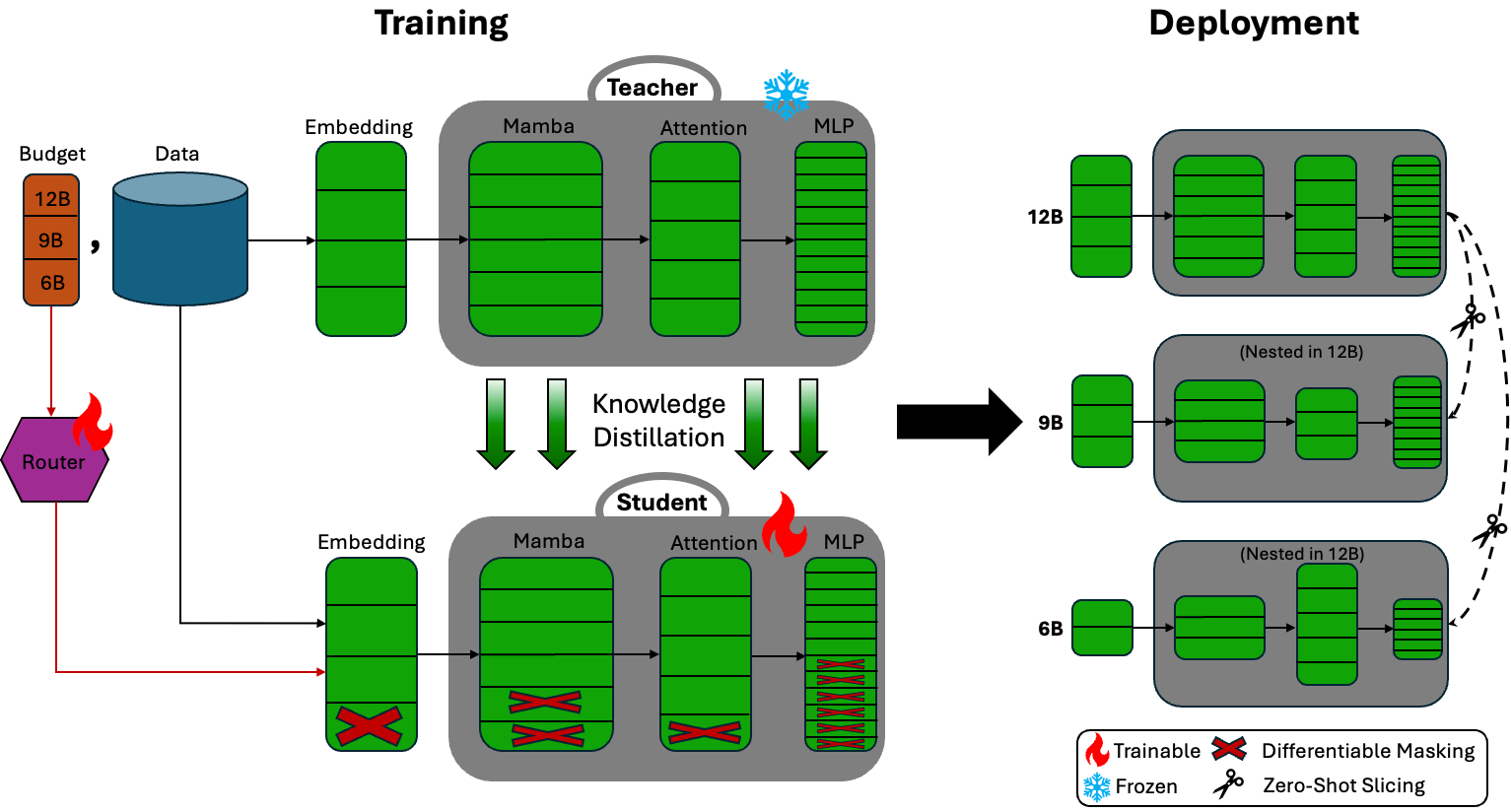
Training a family of language models at different scales typically requires separate training runs for each size, burning through hundreds of billions of tokens per model. NVIDIA’s Nemotron Elastic embeds multiple nested submodels within a single parent model, where each smaller version shares weights with the parent and can be extracted zero-shot at deployment. Applied to the Nemotron Nano V2 12B model, this approach simultaneously produced 9B and 6B models using only 110B training tokens. That’s over 360x cost reduction compared to training from scratch, and around 7x better than existing compression techniques, while each nested model performs on par or better than state-of-the-art models at their respective sizes.
On the Fundamental Limits of LLMs at Scale
https://arxiv.org/abs/2511.12869
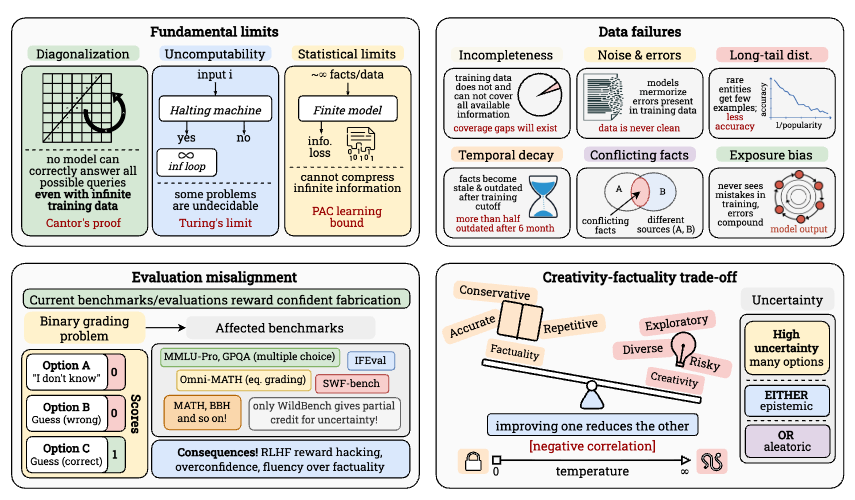
Large language models have improved dramatically with scale, but these gains face five fundamental limitations: hallucination, context compression, reasoning degradation, retrieval fragility, and multimodal misalignment. This paper provides a rigorous theoretical framework showing these aren’t engineering problems to be solved through more compute. Computability theory guarantees that for any model family, diagonalization ensures inputs where models must fail. Finite description length enforces irreducible generalization error. Long context windows compress far below their nominal size due to positional under-training and attention mechanics. The work establishes mathematical boundaries for where scaling helps, where it saturates, and where it provably cannot progress.
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
https://arxiv.org/abs/2511.08544 | GitHub
Self-supervised learning through Joint-Embedding Predictive Architectures has relied on brittle heuristics like stop-gradients and teacher-student networks to prevent collapse. LeJEPA replaces these with a comprehensive theory proving that isotropic Gaussian distributions minimize downstream prediction risk. The framework introduces Sketched Isotropic Gaussian Regularization (SIGReg) to constrain embeddings to this optimal distribution, requiring only a single trade-off hyperparameter and linear time/memory complexity. LeJEPA works out of the box across ResNets, ViTs, and ConvNets, achieving 79% on ImageNet-1k with a frozen ViT-H/14 backbone. The approach requires approximately 50 lines of code and eliminates the need for hyperparameter schedulers.
🎥 4 Videos
Mapping the Open Model Landscape in 2025
Nathan Lambert provides a comprehensive overview of where open-source AI models stand as we head into 2025. The discussion covers which models are genuinely competitive with proprietary options, where the gaps remain, and how the landscape has shifted over the past year. Particularly useful for understanding which open models to consider for specific use cases and what trade-offs you’re making when choosing between open and closed options.
Coding with AI
Chip Huyen walks through practical workflows for coding with AI assistance, moving beyond theoretical discussions to show how experienced engineers actually integrate AI into their development process. The video addresses when AI coding tools help versus when they get in the way, covering context management, code review workflows, and strategies for maintaining code quality when working with AI-generated suggestions.
Learn the basics of Google Antigravity
An exploration of Google’s experimental antigravity feature, demonstrating physics-based interactions and unconventional UI approaches. While playful in presentation, the video showcases interesting approaches to interactive design that challenge conventional interface patterns.
The Weirdly Small AI That Cracks Reasoning Puzzles [HRM]
Jia-Bin Huang examines surprisingly capable small models that solve complex reasoning tasks, challenging assumptions about the relationship between model size and reasoning capability. The video explores what makes these compact models effective and the implications for deploying reasoning systems with limited computational resources.
📰 3 Curated Reads
How evals drive the next chapter in AI for businesses
https://openai.com/index/evals-drive-next-chapter-of-ai/
OpenAI explains how systematic evaluation frameworks are becoming central to deploying AI in enterprise settings. The piece covers moving beyond anecdotal testing to rigorous evaluation systems that catch failures before production, measure performance across edge cases, and provide confidence for business-critical applications. Essential reading for anyone moving AI from prototype to production.
Study Notes: Stanford CS336 Language Modeling from Scratch
https://bearbearyu1223.github.io/cs336/2025/07/20/cs336-note-get-started.html
Han Yu shares detailed study notes from Stanford’s CS336, which covers building language models from first principles. The notes distill key concepts and implementation details that often get glossed over in high-level overviews. Useful for practitioners who want to understand what’s actually happening under the hood when training language models.
On Policy Distillation
https://thinkingmachines.ai/blog/on-policy-distillation/
Thinking Machines Lab explores policy distillation techniques for transferring capabilities from larger teacher models to smaller student models. The analysis covers when distillation works well, where it breaks down, and practical considerations for applying these techniques in production systems where you need efficient inference without sacrificing too much capability.
🛠 2 Tools & Repos
Paper2Agent
https://github.com/jmiao24/Paper2Agent
Automates the process of converting research papers into functional AI agents. Instead of manually implementing methods described in papers, this tool extracts key algorithmic details and generates working code. While it won’t replace careful human implementation for production systems, it accelerates prototyping and helps you quickly test whether a paper’s approach applies to your problem.
Machine Learning Systems Book
https://github.com/harvard-edge/cs249r_book
Harvard’s comprehensive resource on machine learning systems, covering everything from training infrastructure to deployment considerations. The book addresses practical engineering challenges that papers typically ignore: how to actually build, scale, and maintain ML systems in production. Valuable for anyone moving beyond toy datasets to real-world ML engineering.
🎓 1 Pick of the Week
Nano Banana Pro (Gemini 3 Pro Image)
https://deepmind.google/models/gemini-image/pro/
Google released Nano Banana Pro, their latest image generation model built on Gemini 3 Pro. While the original Nano Banana (Gemini 2.5 Flash Image) from August made waves with character consistency, Nano Banana Pro takes things further with studio-quality precision and advanced text rendering. The model can generate clear, legible text directly in images, create detailed infographics using Gemini’s real-world knowledge, and handle complex compositions at 2K and 4K resolutions. The upgrade addresses persistent pain points in professional creative workflows where text needed to be crisp, diagrams needed to be accurate, and outputs needed to meet production quality standards.
My oh my, are the results BANANAS!
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.