



AI Distillation #3
Google's Vizier, Meta's Sapiens, Transformer Explainers and more...

These are some excellent resources I found over the past week covering various CV, NLP, and optimization topics.
FutureDepth: Predicting the Future to Improve Depth Estimation
FutureDepth introduces a novel approach for video depth estimation by using a Future Prediction Network (F-Net) and a Reconstruction Network (R-Net). These networks enhance depth estimation by leveraging multi-frame temporal and spatial information. Thus, the model predicts future frames and reconstructs features adaptively. The method significantly improves depth accuracy and temporal consistency across various benchmarks while maintaining computational efficiency.

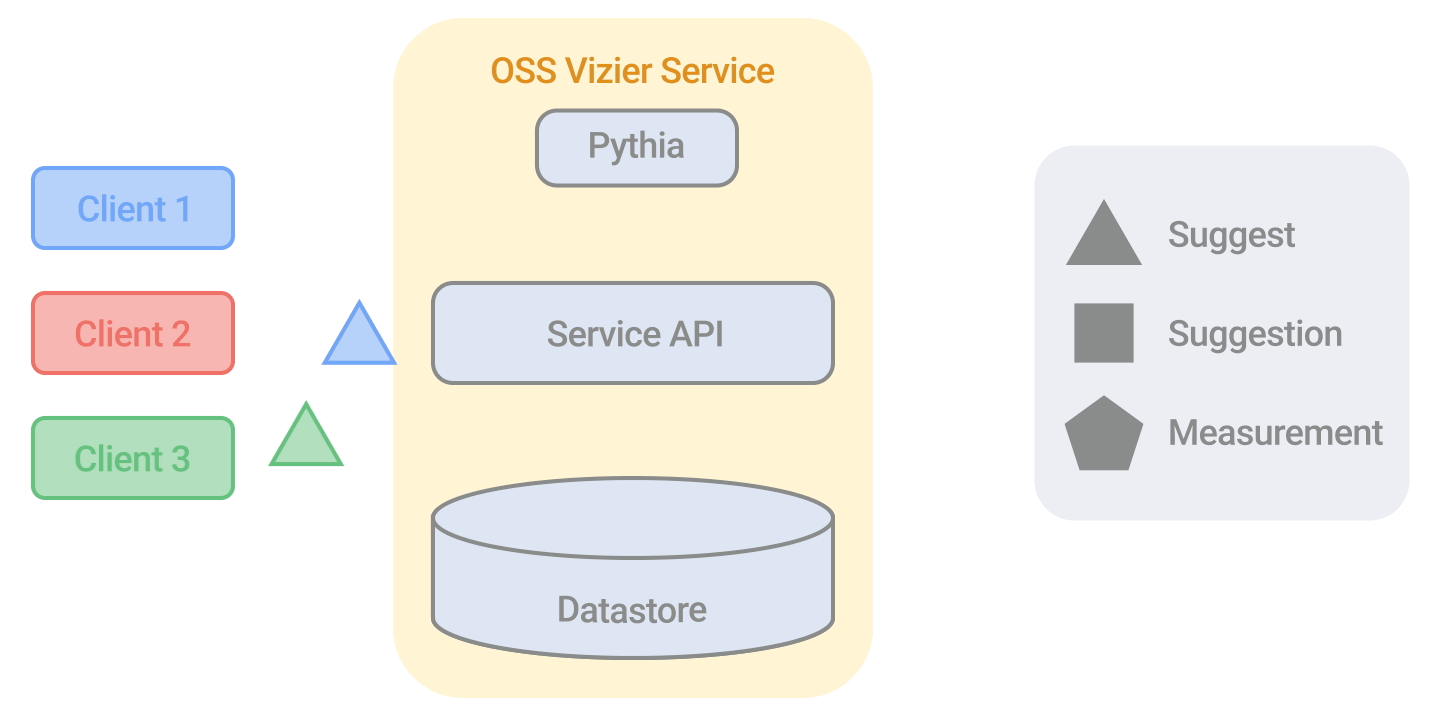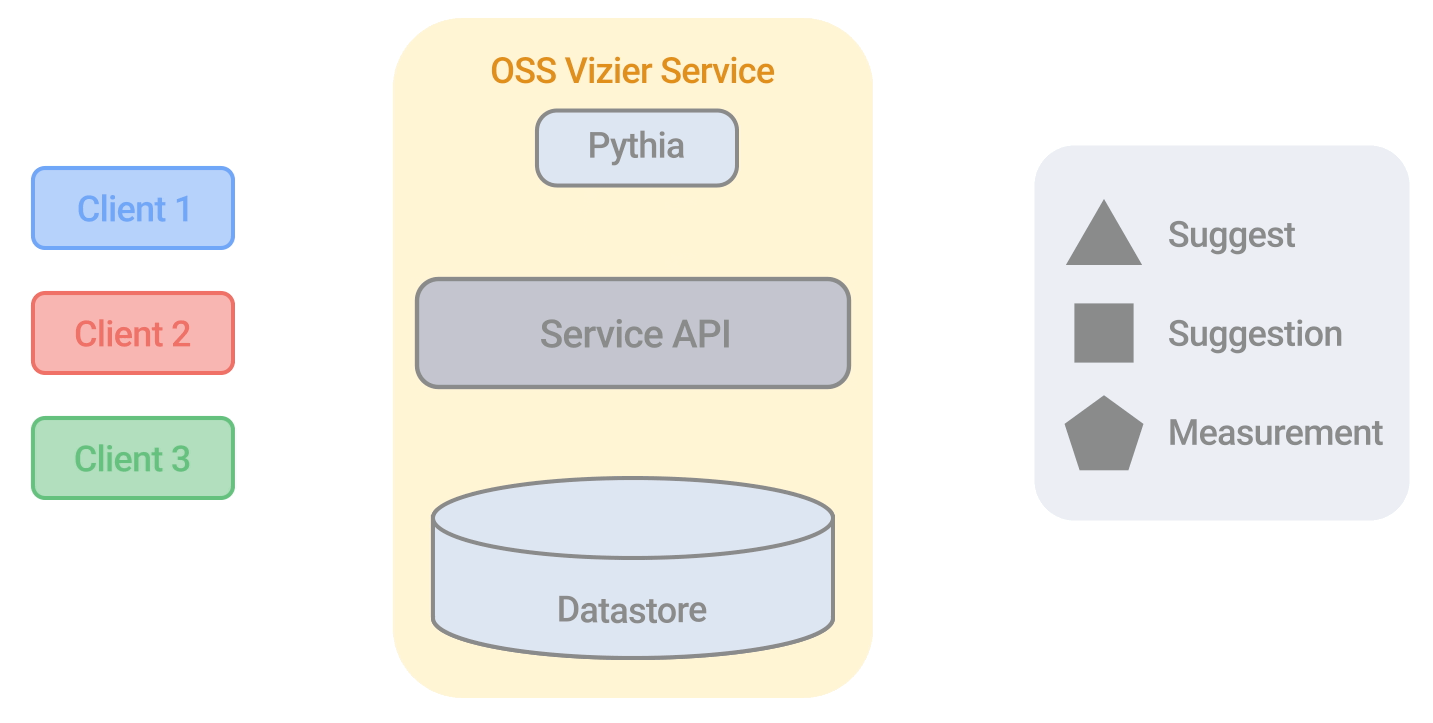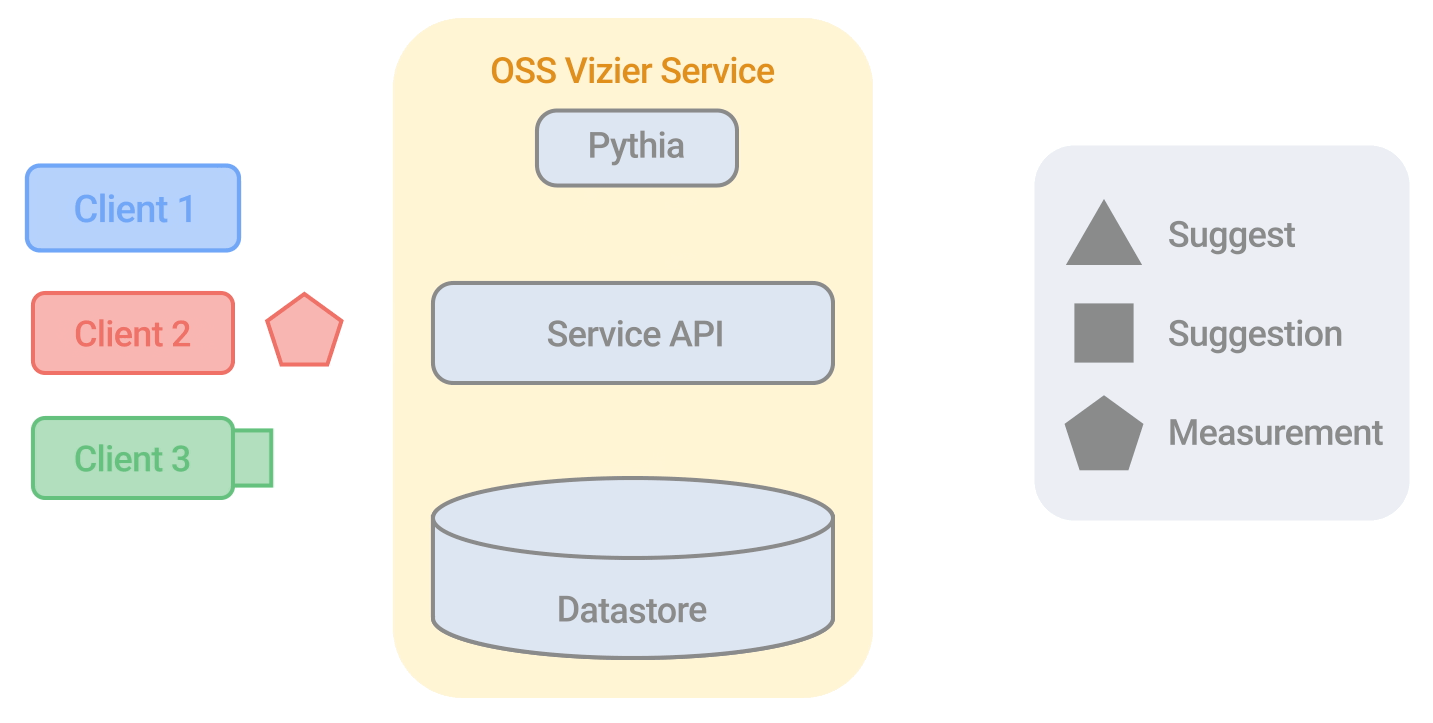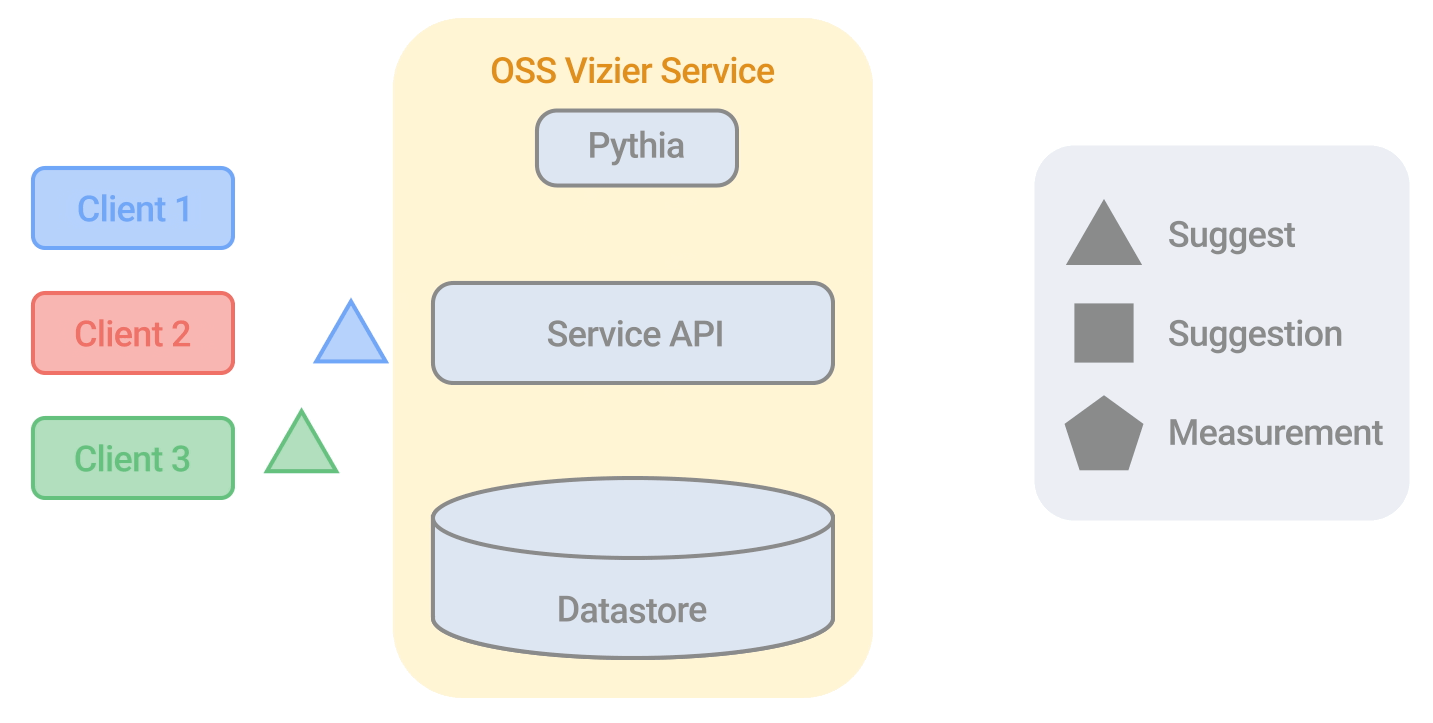
Google's Vizier Algorithm
This paper discusses the implementation and design of the current algorithm used in Google’s Open Source Vizier. This algorithm, used in large-scale Bayesian optimization, has undergone numerous improvements, making it robust and versatile against industry benchmarks. The paper provides technical details on the algorithm's evolution and performance, highlighting its application across various research and production systems at Google.
On the Speed of VITs and CNNs
Lucas Beyer, co-author of the original ViT paper, compares the speed and efficiency of Vision Transformers (ViTs) with Convolutional Neural Networks (CNNs) in image classification tasks. He finds that ViTs offer flexibility and accuracy but tend to be slower than CNNs, particularly in scenarios requiring real-time processing. The analysis suggests that for specific applications, especially where speed is crucial, CNNs might still be the better choice despite ViTs' advantages in other areas. Read the blog post to learn more.
Text-to-Video Using Compressed Representations
In this paper, the authors introduce a high-fidelity text-to-video synthesis model leveraging compressed representations. xGen-VideoSyn-11 utilizes a Video Variational Autoencoder (VidVAE) to compress video data, significantly reducing computational costs while maintaining quality. A divide-and-merge strategy ensures temporal consistency across video segments. The model, trained on over 13 million video-text pairs, supports generating 14-second 720p videos, showing competitive performance against state-of-the-art text-to-video models.

Sapiens: Foundation for Human Vision Models
Meta's Sapiens introduces a family of models designed for human-centric vision tasks, including 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction. The models support high-resolution inference and are easily adaptable through fine-tuning on a large dataset of human images. Sapiens demonstrates significant performance improvements over existing baselines across various benchmarks, achieving state-of-the-art results.
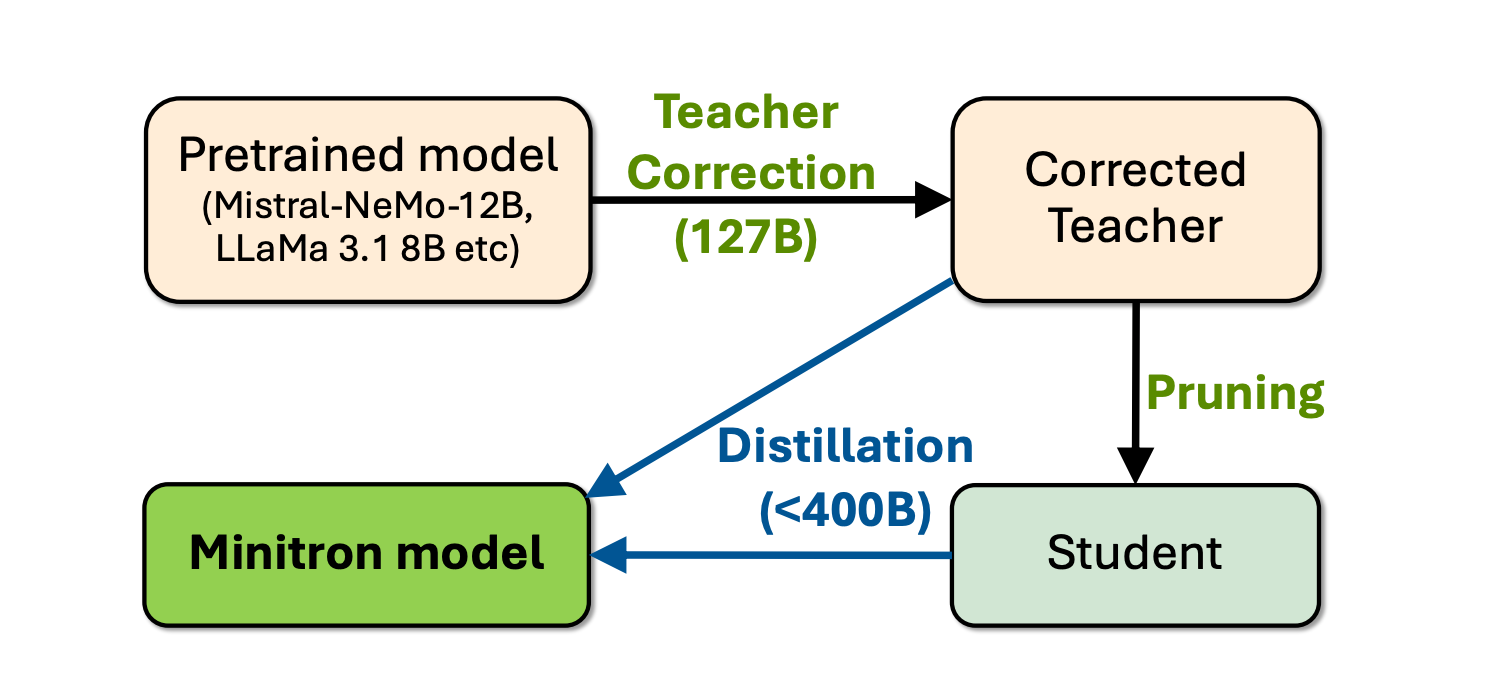
LLM Pruning and Distillation in Practice
In this paper, NVidia details the process of compressing large language models (LLMs) like Llama 3.1 8B and Mistral NeMo 12B down to smaller models with 4B and 8B parameters. The authors explore different pruning strategies, such as depth and joint hidden/attention/MLP pruning, and demonstrate how these techniques maintain performance on benchmarks. The paper also highlights the benefits of fine-tuning teacher models on distillation datasets and shares open-source model weights.
TurboEdit: Instant Text-based Image Editing
TurboEdit introduces a fast, text-based image editing method using few-step diffusion models. An encoder-based iterative inversion technique corrects reconstructions and allows for precise, disentangled editing by adjusting text prompts. This approach achieves real-time, realistic image modifications with significantly fewer functional evaluations than state-of-the-art methods. For more details, check out the project page.

Transformer Explainer
The Transformer Explainer is an interactive tool designed to help users understand the inner workings of transformer models. It provides visualizations demonstrating how transformers process and attend to different parts of the input text, making it easier to grasp concepts like attention mechanisms and token relationships. This tool is handy for educators or students wanting a deeper understanding of this model.

Definitely a mouthful if you keep trying to say it over and over.