

Andrew Ng’s Latest Agentic AI Course and LLM Evals from Scratch: The Tokenizer Edition #7
This week's most valuable AI resources

Hey there! Reinforcement learning just got a lot cheaper. While everyone’s been throwing compute at fine-tuning, researchers figured out how to improve agent performance without touching a single parameter. Elsewhere, a multimodal model is running 32x faster than autoregressive approaches, and Sebastian Raschka published a thorough breakdown of LLM evaluation methods with working code. Plus, Andrew Ng’s new course focuses on building agents that ship to production, not just impress in demos.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Training-free RL that actually works, 32x faster multimodal generation, smarter experience replay for reasoning models, 5.6x code compression without quality loss, unified video generation across tasks
🎥 Videos: AI security vulnerabilities you need to know, why design judgment beats technical specs, how vision-language models actually work, building production apps with AI coding assistants
📰 Reads: Four evaluation methods every ML engineer should understand, the practical path from notebooks to production MLOps, comprehensive analysis of AI’s current state across research, industry, and policy
🛠 Tools: Learn LLMs through 300+ visual explanations and working code, or understand transformers from scratch with Karpathy’s minimal implementation
🎓 Learning: Andrew Ng’s new course for building agents that handle real production workflows, not just demos
Preorder my first book — AI for the Rest of Us — today!
If you’ve enjoyed my work, you’ll find incredible value in this book. I promise.
Early preorders make an enormous difference in determining how many bookstores will carry the book, how widely it will be seen, and whether publishers believe there’s demand for accessible AI education.
📄 5 Papers
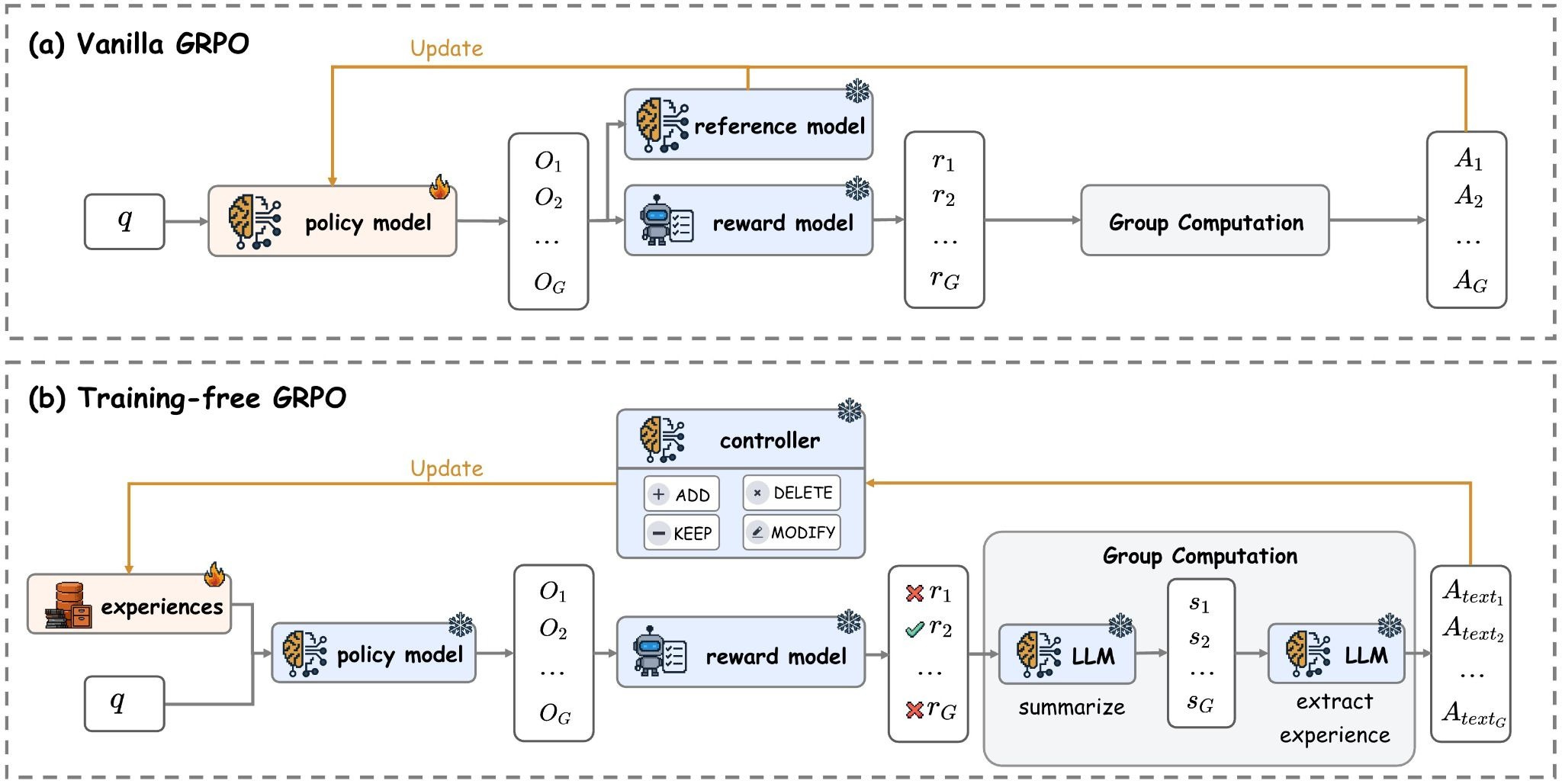
Training-Free Group Relative Policy Optimization
https://arxiv.org/abs/2510.08191 | GitHub
Skip the expensive fine-tuning. This research improves LLM agent performance without touching model parameters. The trick is learning experiential knowledge as a token prior instead of altering weights. Applied to DeepSeek-V3.1-Terminus with just a few dozen training samples, it outperforms fine-tuned models at a fraction of the cost. If you’re tired of burning compute on agentic RL, this lightweight approach actually works.
Lumina-DiMOO: An Omni Diffusion Large Language Model for Multi-Modal Generation and Understanding
https://arxiv.org/abs/2510.06308 | GitHub
Fully discrete diffusion for multimodal tasks. Handles text-to-image, image editing, and image understanding in one model. The speed gain is real: 32x faster than autoregressive models, with another 2x from their caching method. Beats existing open-source models on benchmarks. Also does zero-shot inpainting and lets users refine specific areas interactively. The discrete approach makes it faster without sacrificing quality.

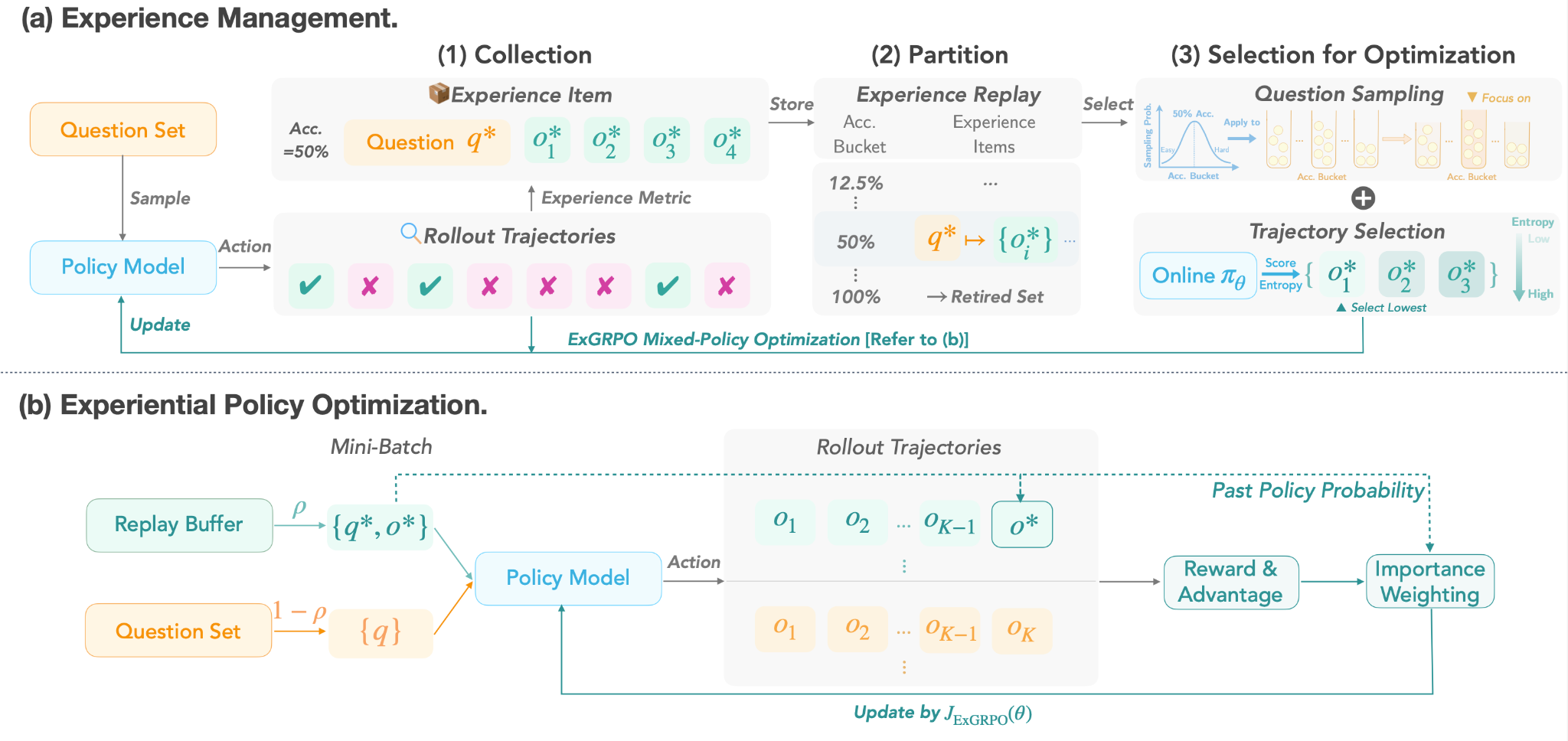
ExGRPO: Learning to Reason from Experience
https://arxiv.org/abs/2510.02245 | GitHub
Most RL training tosses experiences after one update. Wasteful. This paper identifies which experiences actually matter: correctness and entropy. ExGRPO organizes valuable experiences and reuses them strategically. Across five models from 1.5B to 8B parameters, it gains +3.5 points on math and +7.6 on general benchmarks over standard approaches. More importantly, it stabilizes training where on-policy methods collapse. Smart experience management beats throwing more compute at the problem.
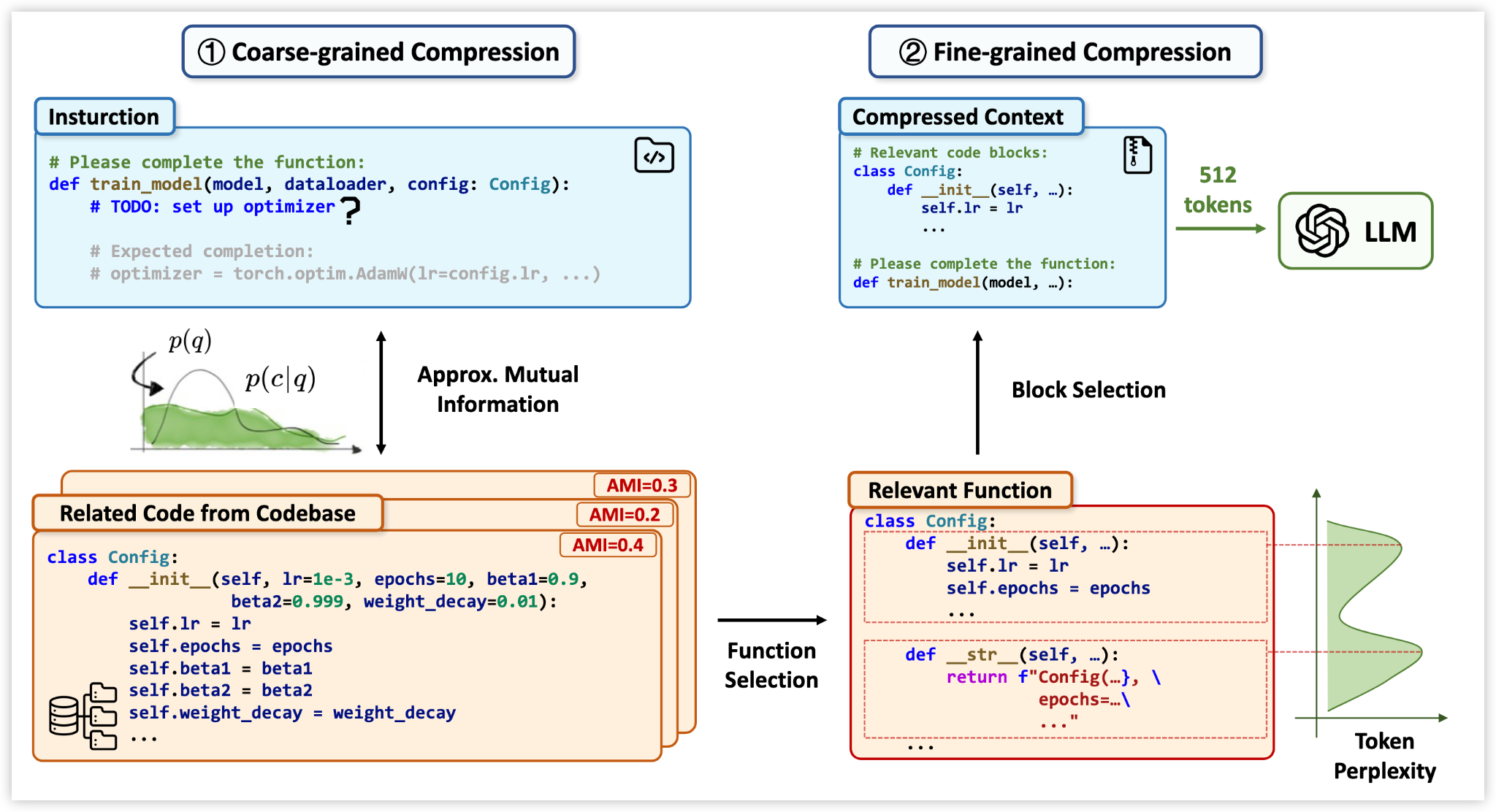
LongCodeZip: Compress Long Context for Code Language Models
https://arxiv.org/abs/2510.00446 | GitHub
Long context for code is expensive. LongCodeZip compresses it smartly. First, it ranks functions by relevance and keeps what matters. Then it segments those functions into blocks and picks the optimal subset. Result: 5.6x compression without hurting performance on completion, summarization, or Q&A. If you work with large codebases, this makes LLMs practical without exploding your API costs.
UniVideo: Unified Understanding, Generation, and Editing for Videos
https://arxiv.org/abs/2510.08377
Unified models work for images but struggle with video. UniVideo fixes this. It combines a multimodal LLM for understanding instructions with a diffusion model for generation. One system handles text-to-video, image-to-video, and video editing under a single instruction paradigm. Matches or beats specialized models on standard benchmarks. The unified design enables task composition like editing plus style transfer in one instruction. It even transfers image editing skills to video tasks it wasn’t explicitly trained on.
🎥 4 Videos
Social engineering, malware, and the future of cybersecurity in AI
Hannah Fry sits down with Foret Flynn, VP of Security at Google DeepMind, who recounts the 2009 Operation Aurora attack on Gmail and how it shifted Google’s security thinking from server-side to client-side defenses. Flynn explains Google’s response: the BeyondCorp zero trust model and unfishable MFA tokens. The conversation then moves to new vulnerabilities from LLMs, including prompt injection and AI-generated polymorphic malware. Flynn introduces two Google DeepMind projects addressing these risks: Big Sleep, which uses AI to find zero-day vulnerabilities in code, and Mender, which aims to automatically generate patches for those vulnerabilities.
Taste is your moat
Dylan Field from Figma talks with Alessio about how design judgment becomes your competitive advantage as AI makes software creation easier. Field explains Figma’s evolution from bridging imagination to reality, emphasizing that as code generation improves, design matters more. He discusses the blurring lines between design specs and actual code, arguing for tools that let designers explore aesthetic space rather than imposing single viewpoints. The conversation covers early-stage recruiting, the value of contrarian thinking in entrepreneurship, and why design is increasingly the differentiator when everyone has access to similar AI capabilities.
What Are Vision Language Models? How AI Sees & Understands Images
Martin Keen from IBM breaks down how vision-language models work as multimodal AI systems that process both text and images. The explanation covers how VLMs convert images into tokens using vision encoders and projectors, allowing language models to process visual and textual information together. Practical applications include visual question answering, image captioning, and document understanding, like extracting data from receipts or graphs. The video also addresses real challenges: tokenization bottlenecks, hallucinations, and bias in training data.
Full Tutorial: A Proven 3-File System to Vibe Code Production Apps
Ryan Carson, a serial founder who is building his next startup solo, demonstrates his three-file system for coding production-ready apps with AI. The system: create a detailed Product Requirements Document, generate a hierarchical task list from the PRD, then iteratively process each subtask with AI using a “code, test, then commit” workflow with human oversight. Carson built his divorce-assistance app “Untangle” using this method. He advocates for solving specific pain problems rather than vitamin solutions, and emphasizes test-driven development as crucial for agents to verify they’re building correctly.
📰 3 Curated Reads
Understanding the 4 Main Approaches to LLM Evaluation

Sebastian Raschka, PhD breaks down the four fundamental methods for evaluating LLMs: multiple-choice benchmarks, verifiers, leaderboards, and LLM-as-a-judge approaches. Each method comes with from-scratch code examples that show exactly how they work under the hood. The article addresses a question that comes up constantly when advising on projects: how to choose between different models and make sense of evaluation results. Raschka clarifies that while multiple-choice benchmarks measure capabilities on standardized tests, verifier-based evaluation uses external tools to check correctness (like running code or verifying math), leaderboards rank models based on human preference patterns, and LLM judges use language models themselves to score outputs. Understanding these distinctions helps you interpret papers and benchmarks critically rather than taking numbers at face value, and the code examples let you implement each approach for your own evaluation needs.
How to get started with MLOps and ML Engineering

Devansh walks through the complete ML lifecycle from experimentation to production deployment, explaining why most ML models never reach users. The article breaks down the experimentation phase (problem formulation, data collection, model training) and the production phase (automated pipelines, deployment, monitoring). He covers critical skills MLOps engineers need: software engineering fundamentals, ML framework comfort, data engineering, and automation. The piece includes practical guidance on building an ML platform from scratch using Kubeflow, feature stores, and model registries. If your models work great in notebooks but you struggle getting them into production systems that run reliably, this clarifies the infrastructure and workflows that bridge that gap.
State of AI Report 2025

Nathan Benaich’s eighth annual State of AI Report provides the most comprehensive analysis of AI developments across research, industry, politics, and safety. This year includes the first State of AI Usage Survey of 1,200 practitioners, showing that 95% use AI at work or home, 76% pay out of pocket, and productivity gains are real across diverse use cases. The research section reveals OpenAI still leads, but competitors have closed the gap significantly, while the industry analysis shows AI software adoption has gone mainstream, with 44% of US businesses now paying for AI (up from 5% in 2023). The politics section examines Europe’s AI Act struggling with only 3 states compliant, China’s massive AI spending despite record debt, and the $500B Stargate project representing the industrial era of AI infrastructure. The safety section highlights concerning budget gaps with all major US safety organizations spending $133M in 2025 - less than frontier labs burn in a day - while cyber and alignment risks accelerate.
🛠 2 Tools & Repos
Hands-On LLM
https://github.com/HandsOnLLM/Hands-On-Large-Language-Models
The official code repository for the O’Reilly book “Hands-On Large Language Models” by Jay Alammar and Maarten Grootendorst provides practical tools and concepts for using LLMs today through nearly 300 custom-made figures. All examples are built and tested using Google Colab with free T4 GPU access, making it accessible regardless of your local hardware. The book steadily builds from introductory concepts to fine-tuning and building your own large language models, covering transformer architectures, tokenizers, semantic search, RAG, and cutting-edge techniques with working code. If you learn better through visual explanations and hands-on implementations rather than pure theory, this resource combines clear illustrations with comprehensive code labs.
NanoGPT
https://github.com/karpathy/nanoGPT
Andrej Karpathy’s minimal implementation of GPT provides the simplest, fastest repository for training and fine-tuning medium-sized GPTs. The codebase is intentionally small and hackable, making it perfect for understanding transformer fundamentals without getting lost in abstraction layers. Unlike production frameworks that hide implementation details, nanoGPT lets you see exactly how GPT training works at every step. Valuable whether you’re a beginner trying to understand transformers from first principles or an experienced practitioner who wants a clean starting point for experiments without framework overhead.
🎓 1 Pick of the Week
Agentic AI Course
https://www.deeplearning.ai/courses/agentic-ai/
Andrew Ng’s latest course teaches you to build agentic AI systems that take action through iterative, multi-step workflows, moving beyond single-prompt approaches to autonomous systems that handle complex tasks. You’ll learn four key agentic design patterns: Reflection (where agents examine their own output and improve it), Tool use (where LLM-driven applications decide which functions to call for web search, calendar access, email, code execution), Planning (using an LLM to break down tasks into sub-tasks), and Multi-agent collaboration (building multiple specialized agents to perform complex tasks). The course emphasizes evaluation-driven development, teaching you to build robust testing frameworks and conduct systematic error analysis, which Ng identifies as the single biggest predictor of whether someone can build agents effectively. The self-paced course is taught in a vendor-neutral way using raw Python without hiding details in frameworks, so you’ll learn core concepts you can implement using any popular agentic AI framework or no framework at all. Together, you’ll build a deep research agent that searches, synthesizes, and reports using all these agentic design patterns and best practices.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.
Really love your approach to Al course and LLM …. It deserves more eyes on it.
I work with Substack writers to increase visibility and drive more genuine subscribers.
Happy to share what’s been working lately if you’re interested.
Thanks Tim for reaching out, would love to learn more.