

Claude Code Best Practices, Planning in 8 Tokens, and Why Reasoning Models Can't Control Their Own Thoughts - 📚 The Tokenizer Edition #20
This week's most valuable resources

Hey there! This week’s theme is the gap between what AI systems can do and what they actually do in practice. Reasoning models that can’t steer their own chain of thought. RAG systems that work in demos but hallucinate in production. Training clusters that fail in ways no tutorial prepares you for. The good news: attention training just got 1.67x faster, and Figma engineers are showing what a real design-to-code workflow looks like with Claude Code.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Low-bit attention training, efficient VLMs, scientific discovery shortcuts, robot planning in 8 tokens, and reasoning models that can’t control their own thoughts
🎥 Videos: Sakana AI’s evolved transformers, Turbopuffer’s post-RAG retrieval architecture, Figma’s Claude Code design pipeline, and DeepMind reflects on AlphaGo’s decade of impact
📰 Reads: Nathan Lambert on why the open model gap will widen (not close), production RAG done right, and diagnosing failures across 192-GPU training clusters
🛠 Tools: ByteDance’s open-source SuperAgent platform and OpenAI’s AI-powered LaTeX editor
🎓 Learning: A community-built field manual for getting the most out of Claude Code
📄 5 Papers
1. SageBwd: A Trainable Low-bit Attention
https://arxiv.org/abs/2603.02170 | GitHub
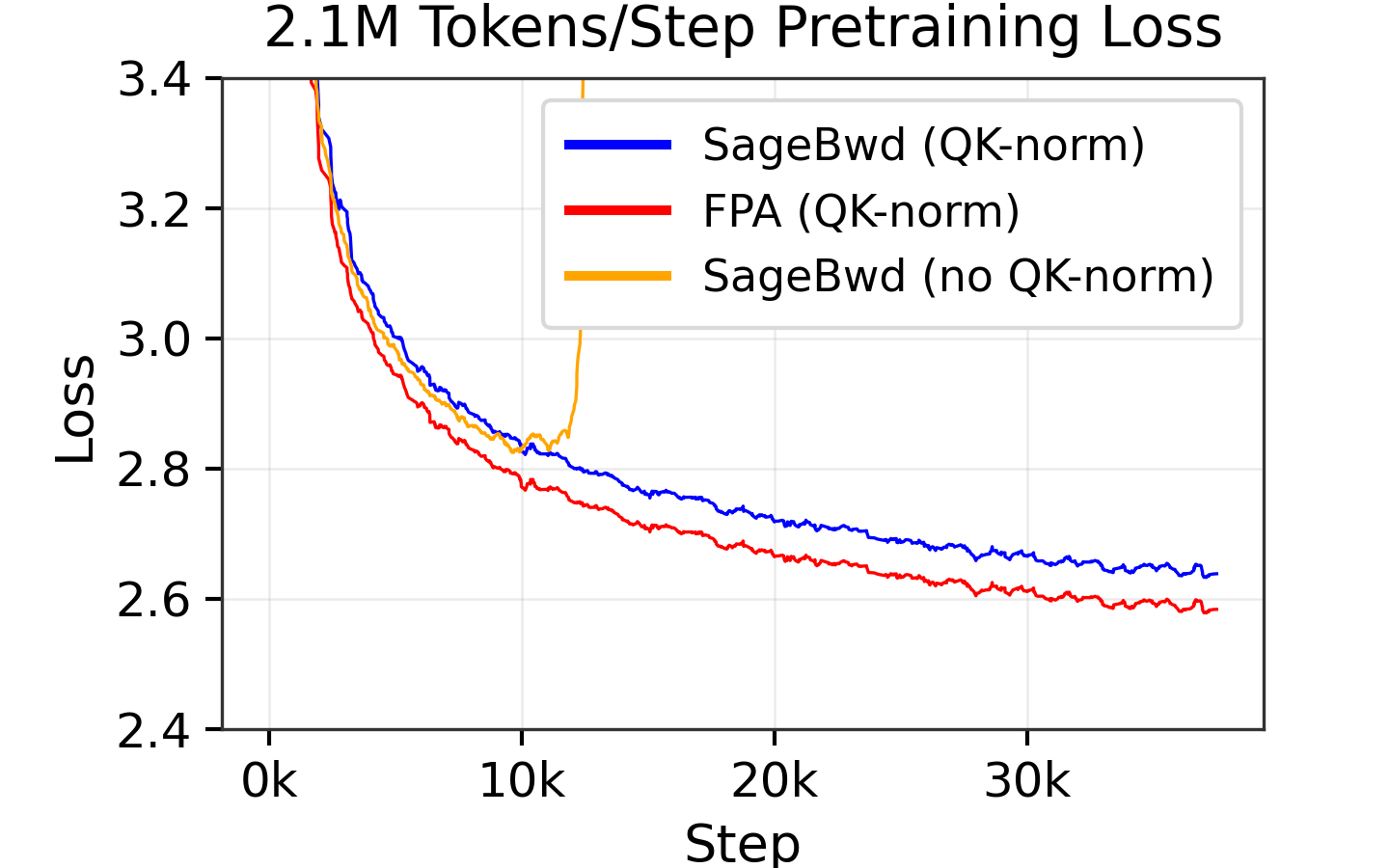
SageAttention already had 3,200+ GitHub stars for speeding up inference. Now SageBwd extends quantized attention to training by quantizing 6 of 7 attention matrix multiplications in the backward pass. The result: up to 1.67x speedup over FlashAttention2 with negligible loss difference (2.561 vs 2.563 at 260K tokens per step). If you’re spending money on attention compute during training, this is the paper to read.
2. Penguin-VL: Exploring the Efficiency Limits of VLM with LLM-based Vision Encoder
https://arxiv.org/abs/2603.06569
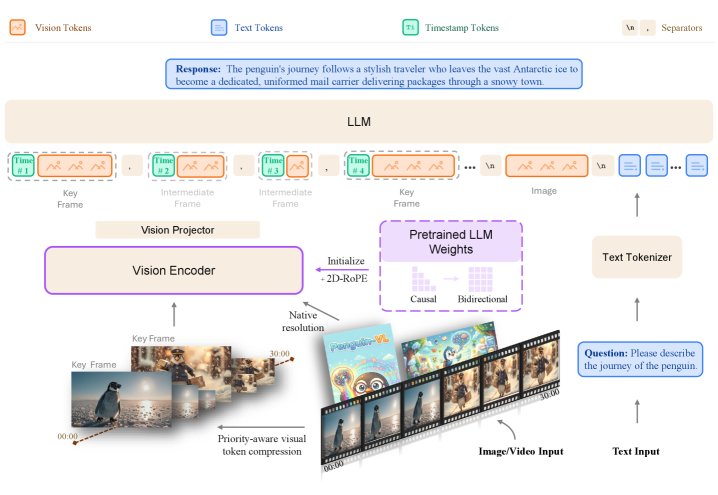
What if you replaced CLIP/SigLIP vision encoders with one initialized from a plain text LLM? Tencent AI Lab tried it. Their 8B model outperforms Qwen3-VL-8B and InternVL3.5-8B on document understanding, visual knowledge, and video reasoning, hitting 96.2 on DocVQA and 90.5 on ChartQA. Vision encoder architecture matters more than you’d think. Sometimes the answer is just using a language model.
3. MOOSE-Star: Unlocking Tractable Training for Scientific Discovery
https://arxiv.org/abs/2603.03756
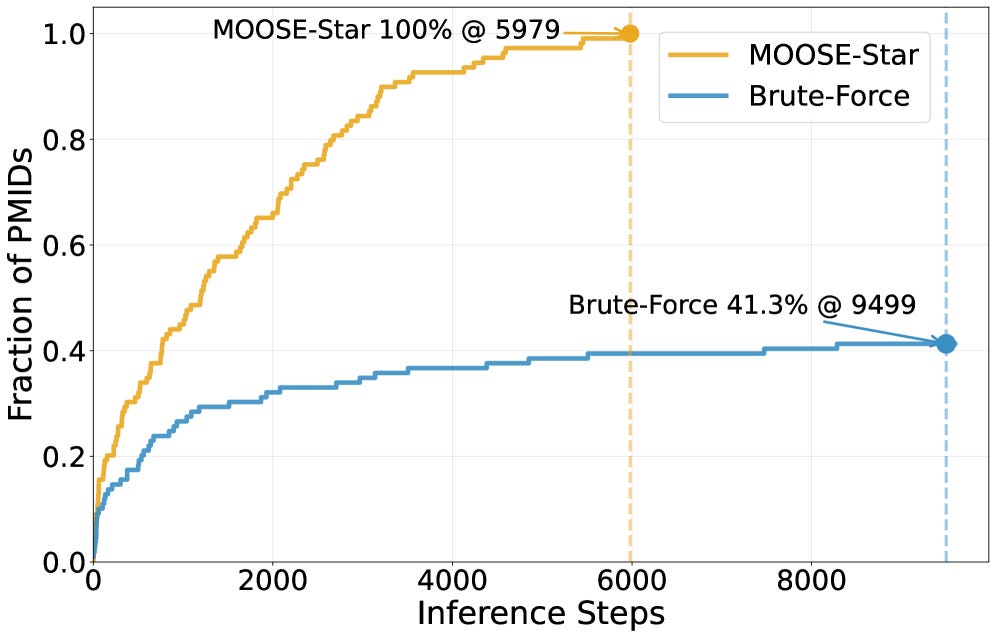
Scientific hypothesis discovery with LLMs has an exponential search problem. MOOSE-Star (from MiroMind AI) reduces combinatorial O(N^k) search to roughly logarithmic via hierarchical decomposition, hitting 100% success rate at around 6,000 inference calls where brute-force saturates at 41.3%. Also releases TOMATO-Star, a dataset of 108,717 decomposed papers for benchmarking. The complexity reduction alone makes previously intractable hypothesis spaces searchable.
4. CompACT: A Compact Discrete Tokenizer for Latent World Model Planning
https://arxiv.org/abs/2603.05438
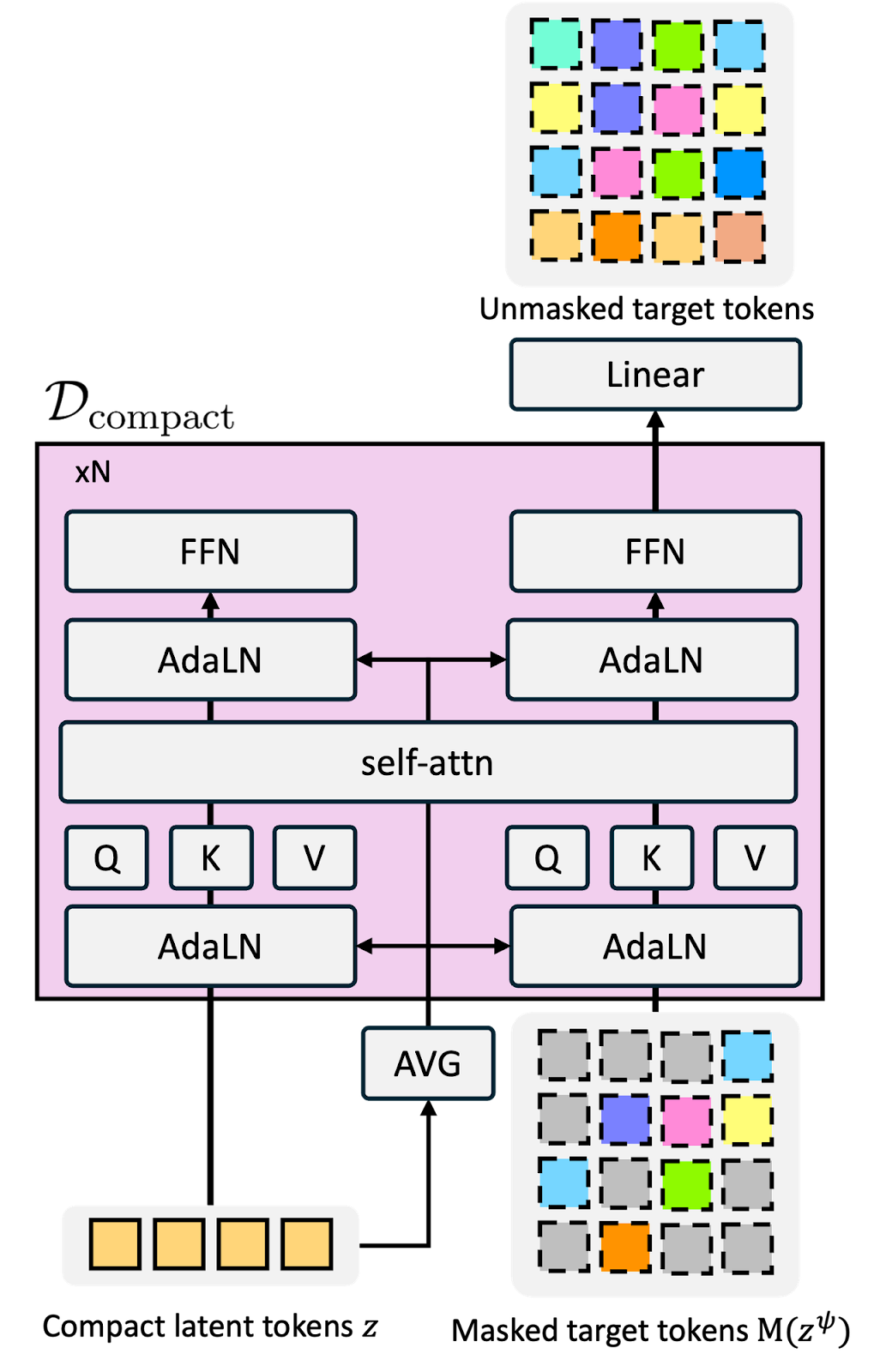
Robot planning typically requires hundreds of visual tokens per observation. CompACT (from POSTECH and KAIST, accepted at CVPR 2026) compresses that down to as few as 8 discrete tokens, making world-model planning 40x faster. Navigation planning drops from 178 seconds to under 6 seconds with competitive accuracy. This is what makes real-time robotic planning actually feasible.
5. Reasoning Models Struggle to Control their Chains of Thought
https://arxiv.org/abs/2603.05706
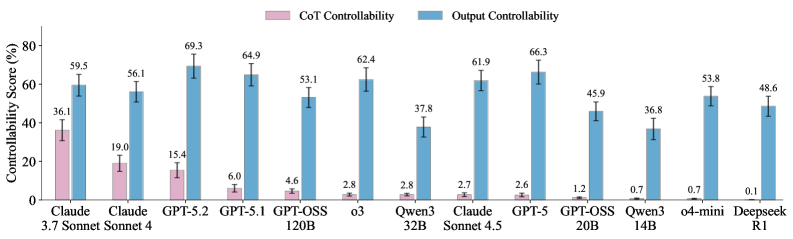
Can reasoning models actually control their chain of thought? Researchers from NYU, OpenAI, UCL, and UPenn tested 13 models. Claude Sonnet 4.5 achieves only 2.7% CoT controllability (versus 61.9% output controllability). DeepSeek R1 scores 0.1%. The safety implication: if models can’t steer their reasoning strategically, they also can’t easily hide deceptive reasoning from monitors. Matters more for what it implies than what it measures.
🎥 4 Videos
1. Sakana AI’s Open-Ended Evolution of Transformers with Robert Lange
LLMs combined with evolutionary algorithms for open-ended program search. That’s Shinka Evolve from Sakana AI, discussed by Robert Lange on Machine Learning Street Talk. Why “solving the wrong problem” sometimes leads to better architectures. How evolutionary pressure discovers novel transformer variants. What open-endedness means for AI research beyond benchmarks. Covers the gap between optimizing a known objective and discovering objectives worth optimizing.
2. Retrieval After RAG: Hybrid Search, Agents, and Database Design with Turbopuffer’s Simon Eskildsen
What comes after the first wave of RAG implementations? Hybrid search architectures, why vector-only retrieval hits a ceiling, agent-driven retrieval reshaping database design. Simon Eskildsen (Turbopuffer founder) walks through real case studies from Cursor and Notion on Latent Space. If you’ve built a RAG system and hit a quality wall, this is where you go next.
3. How Figma Engineers Sync Designs with Claude Code and Codex
MCP-based tooling that creates a continuous sync between design and code. Figma’s Gui Seiz and Alex Kern show their team’s actual production workflow using Claude Code and Codex. Not a concept demo. The design handoff becomes a two-way pipeline. Worth 40 minutes if your team still does screenshot-to-implementation.
4. 10 Years of AlphaGo: The Turning Point for AI
AlphaGo’s techniques propagated into protein structure prediction, materials science, and chip design. Google DeepMind’s Thore Graepel and Pushmeet Kohli trace the full decade of impact beyond the Go match itself. Covers how one system’s ideas became foundational building blocks across scientific domains.
📰 3 Curated Reads
1. What comes next with open models

The open-closed model gap will widen, not close. Nathan Lambert’s reframing: the real opportunity isn’t chasing frontier capability but building small, specialized models that are 10x faster and 100x cheaper. Introduces the “open models as sub-agents” framing where open-weight models handle specialized tasks within larger systems. Changes how you evaluate open models if you’ve been benchmarking them against GPT-5.
2. Production RAG: Learning from Scratch Done Right

Most RAG tutorials optimize for demos, not production. This piece on Paul Iusztin’s Decoding AI (by guest contributor Priya) walks through a 4-phase production RAG system: ingestion, retrieval, generation, serving. Uses Postgres and pgvector with explicit control flow and data lineage. The core insight: a bad chunk doesn’t throw an exception, it just hallucinates an answer three steps later. If your RAG prototype works in notebooks but fails in production, start here.
3. How to Diagnose Failures in Large AI Training Clusters

AI agents autonomously executing diagnostic runbooks against a unified Prometheus TSDB. Devansh details five case studies across multi-GPU clusters with quantified results: 30% throughput recovery, checkpoint restore penalties reduced from 1.0% to 0.15%. Not theoretical. Includes the actual diagnostic architecture and failure patterns you’d hit at this scale.
🛠 2 Tools & Repos
1. deer-flow (ByteDance)
https://github.com/bytedance/deer-flow

ByteDance’s open-source SuperAgent platform (MIT license, 31K+ stars) got a ground-up v2.0 rewrite that hit #1 on GitHub Trending. Ships as a complete deployable platform, not a framework you wire together. Web UI, Docker-sandboxed execution, persistent cross-session memory, parallel sub-agent spawning, messaging integrations (Telegram, Slack, Feishu). Built on LangGraph. For teams that want a working multi-agent system without assembling one from parts.
2. Prism (OpenAI)
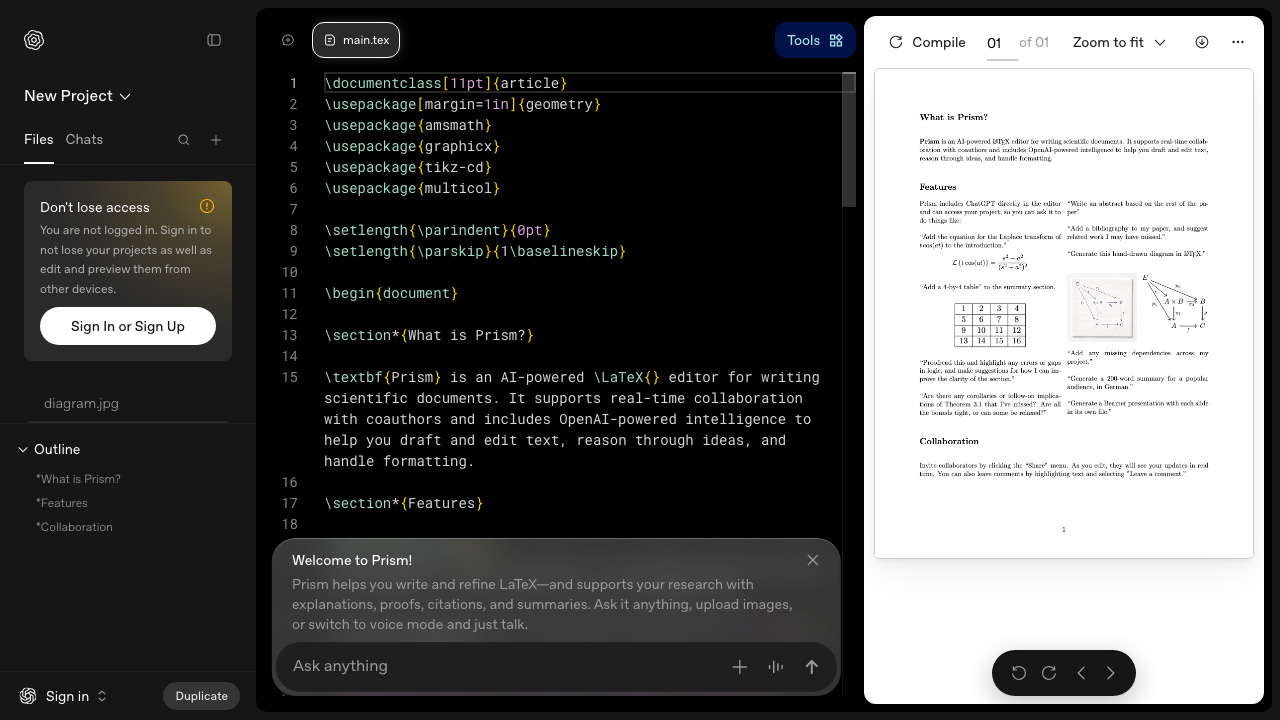
OpenAI’s browser-based LaTeX editor with GPT-5.2 integrated inline. Free tier: unlimited projects, compiles, and collaborators (Pro at $7/mo for unlimited AI features). Highlight text, ask the AI to rewrite or formalize, and it compiles in real time. Zotero integration, image-to-LaTeX, voice mode for dictating equations. Best for refining existing papers. Won’t generate structure from a blank page. No Git integration yet, which is the main gap versus Overleaf.
🎓 1 Pick of the Week
claude-code-best-practice
https://github.com/shanraisshan/claude-code-best-practice
How should you actually use Claude Code day-to-day? Official docs don’t answer that. This community-built field manual does (17,600+ stars, actively maintained). 40+ actionable tips across 8 categories, comparative reports against other tools, community workflow implementations. Includes a working `.claude/` directory you can clone. The “billion-dollar questions” section names what the community still hasn’t figured out. If you’re already using Claude Code and want to move from casual to systematic, bookmark this.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.
I subscribe to over 300 Substacks; this is one of the handful that's a must read. That you for producing this.