



Culinary compression: Data distillation in the Top Chef Kitchen
Choosing the right data matters more than you think

Before we start, thank you for your incredible support and encouragement on the pre-sale of my book. I'm excited to get the finished version in your hands soon. If you missed the announcement, use the code GRADASCENT for 20% off on top of the pre-order price.
This Week on Gradient Ascent:
Data distillation quickfire - Please pack your outliers and go 🧑🍳
[Check out] A tutorial on tensor parallelism 🖇️
[Consider reading] Video editing using image diffusion 📽️
[Definitely read] The Prompt artists 🎨
[Novel research] RNNs are not dead 🪦
[What in the?] ChatGPT plugins! 🔌
Data Distillation Quickfire - Please pack your outliers and go:

Over the past few weeks, I've been binge-watching Top Chef. For those who don't know, it's a cooking competition where talented chefs from around the world compete against each other to win big bucks. Every episode has two rounds, a quickfire challenge, and an elimination challenge. The chef with the worst dish in the elimination challenge gets, um, eliminated (from the competition)1.

In both rounds, the chefs are expected to make delicious food that fits a brief. But that's not all. They are put under other constraints like the time they have and the ingredients they can use.
The quickfire challenge is a pressure cooker (pardon the pun). The chefs must develop something unique quickly, often with bizarre constraints. My favorite quickfire involves a restriction on ingredients. The chefs have to prepare a complex dish but use just 3 or 5 ingredients versus the cornucopia they are usually afforded from the Top Chef pantry.
That's insanely hard. Can you imagine making a Mole with five ingredients? Some of the variants of this sauce have more than 100 components. Yet, successful chefs find a way to condense the essence of a complex dish down to its bare bones. They can transfigure water into a flavorful umami bomb that the judges then wax lyrical about. But you're not reading this to get a blow-by-blow account of how Buddha Lo prepared autumn leaves from a pumpkin.
Modern machine learning glorifies petabyte-scale datasets and trillion-parameter models. This is because this kind of scaling works well for various tasks. But, on the flip side, it restricts the research and development of similar models to a few labs that have the necessary data and computing power.
But almost everyone else doesn’t have a server farm to train these models. So what do we do if can't fit both a colossal dataset and a model into memory?
Model optimization techniques are well-documented. So, can we do something about the dataset instead?
Can we produce an exquisitely trained model with fewer ingredients?
Gourmet Data Reduction: Small Bytes, Big Insights
Three years ago, researchers introduced the idea of data distillation. As the name suggests, it is a method which creates a tiny synthetic dataset that summarizes the knowledge contained in a large dataset. This summary can then be used as a drop-in replacement for the original dataset. In other words, we can get the same results from training a model whether we use the original dataset or its condensed counterpart.

This has several benefits. We can train models faster through data distillation, leading to cost savings, reduced carbon emissions, and faster research iteration. High-quality distilled datasets can be easily shared with a broader community of practitioners which opens the doors for more people to train state-of-the-art models on commodity hardware. This approach also complements existing model optimization methods like knowledge distillation and transfer learning. In fact, data distillation is inspired by knowledge distillation. While knowledge distillation aims to produce a smaller model, data distillation strives to create a smaller yet more potent dataset.

You might wonder why we can't just select a small subset of examples from the original dataset and use that instead. That's a fair suggestion, and researchers have tried this before. The fancy name for this approach is Core-set Selection or Instance Selection. The challenge with this approach is that it relies on well-chosen heuristics and thus can lead to a trade-off between efficiency (the size of the dataset) and performance (the quality of the trained model).
Umami Unleashed: Flavors of Data Distillation
To quickly recap, data distillation aims to extract knowledge from a large dataset and use it to create a significantly smaller synthetic dataset such that models trained on the latter have comparable performance to those trained on the former.
The creation process happens within an optimization loop. First, we initialize the synthetic dataset (S in the flowchart below) either randomly or by selecting samples from the original dataset (T in the flowchart). Then, throughout the optimization process, we train both a network (used to evaluate how S compares to T) and the synthetic dataset alternately. By the end of the process, we have a synthetic dataset that is an excellent drop-in for the original dataset.

The types of data distillation come from how this smaller dataset is learned.
Performance matching
In this class of methods, the synthetic dataset is learned by optimizing for the neural network's performance that is trained on this data. The goal is to create a synthetic dataset such that a neural network trained on this dataset has the lowest possible loss on the original dataset.

Parameter Matching
Unlike match-by-performance approaches, the idea in parameter matching methods is to train the same neural network on the synthetic and original data for a few steps and then ensure that the network parameters are consistent. In other words, the model should learn similar weights and biases when trained on the synthetic data as when trained with the original dataset.

Distribution Matching
This approach focuses on producing synthetic data whose distribution is similar to the original dataset. Thus, instead of trying to match the parameters of the neural network trained on these datasets or its downstream results, we focus on directly optimizing the distance between the two data distributions. Since directly estimating and matching the data distributions can be costly and inaccurate, we instead match a set of embedding functions learned from the respective datasets.
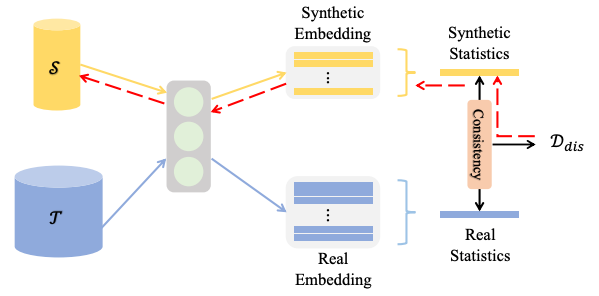
The Proof is in the Pudding
Data distillation research has led to progress in various applications. In particular, Continual learning, Neural Architecture Search (NAS), federated learning, and security comes to mind. In the first couple of these applications, the small proxy dataset makes storage a non-issue and accelerates the speed at which these iterative applications can run. In the case of federated learning and security, data privacy is vital. Synthetic datasets produced via data distillation are learned from the original data and are not just a collection of samples directly taken from it. Thus, this reduces unintended data leakage. Some studies have empirically shown that it isn't possible to recover the original data from the synthetic data, which makes it a huge win for these high-stakes applications.
Data distillation research is still nascent, and an important area of work to keep track of. In the machine learning kitchen, it helps you choose the right ingredients so that your model gets past the judges' table.
Resources To Consider:
A Tutorial on Tensor Parallelism
Link: https://www.mishalaskin.com/posts/tensor_parallel
In this fantastic tutorial, researcher Misha Laskin explains how tensor parallelism works with code examples. Considering how many large models are released daily, it's essential to know the tricks researchers use to train them. Tensor parallelism is definitely of them and is something that every modern practitioner needs to learn!

Video Editing with Image Diffusion Models
Paper: https://arxiv.org/abs/2303.12688
In this paper, researchers find a way to edit videos using image diffusion models. They do this using a two-stage process. First, since a video is just a sequence of images, they "edit" the anchor frame using a text-guided diffusion model. Then, they propagate this edit to future frames using a self-attention mechanism. Finally, they consolidate the changes across all the frames by adjusting latent codes. What's nice is that this approach is training-free! Check out a sample result below. "A giraffe with space suit standing on the moon" was the prompt that was used.

The Prompt Artists
Paper: https://arxiv.org/abs/2303.12253
Ever wondered how expert prompt artists produce mind-boggling imagery with the generative tools we have today? Researchers summarize the artistic styles and current practices in generative AI through extensive interviews, observations, and user surveys. This is a fun read to understand the current landscape around prompting and how these artists develop a unique prompt vocabulary to produce their "signature" results.
RNNs are Not Dead
An independent researcher is toiling away at improving Recurrent Neural Networks (RNNs). These networks were the precursors to the transformer architecture. However, as we know, transformers have completely taken over since. Nevertheless, the researcher has successfully parallelized an RNN, and a huge one at that (14 Billion parameters), and has shown GPT-level performance with it. Awe-inspiring work. Definitely check this out.


ChatGPT Plugins
Code: https://github.com/openai/chatgpt-retrieval-plugin
The rate at which ChatGPT updates are happening is just crazy. Today, OpenAI announced plugins for ChatGPT. These chat extensions allow users to share up-to-date information with ChatGPt, run computations, or interact with third-party services.
The sheer number of potential use cases for this is just staggering. Check out the demo below where Greg Brockman, President & Co-Founder of OpenAI, extracts a 5-second clip from a video using ChatGPT!

This isn’t Squid game