

Cursor's Agent-Written CUDA Kernels, Claude Cowork for Non-Engineers, and Stanford's Frontier Systems - 📚 The Tokenizer Edition #24
This week's most valuable AI resources

Hey there! This week the strongest work happened underneath the models: in the training signal, the kernel compiler, and the retrieval pipeline. Over at Cursor, an agent swarm writes CUDA kernels 38% faster than human-tuned baselines on GQA and MoE GEMMs, where the baselines were already aggressive. Self-distilled RLVR reopens token-level updates inside RL training without the late-stage collapse that earlier approaches kept running into. Hugging Face ships a working multimodal retrieve-and-rerank recipe you can copy tonight, and Stanford’s new Frontier Systems course is pulling the people building the stack into weekly lectures while they build it.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate high-signal AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: a cleaner RL gradient signal that doesn’t collapse late in training, the GUI agent stack done end-to-end for once, memory-aware reward shaping that notices recurrent failure modes, a four-frame streaming video baseline that quietly beats thirteen heavyweight ones, and retrieval supervision pulled straight from agent trajectories.
🎥 Videos: Notion on custom-agent evals at scale, the Gemma 4 architecture delta, Claude Cowork for non-engineers, and a recipe for LLM judges that don’t silently drift.
📰 Reads: Agent swarms writing faster CUDA kernels at Cursor, a hands-on multimodal embedding tutorial from Hugging Face, and a clean first-principles tour of mathematical modeling.
🛠 Tools: VoxCPM2, a tokenizer-free multilingual TTS system, and a viral Claude/Codex plugin that cuts output tokens ~75% by making the agent talk like a caveman.
🎓 Learning: Stanford’s Spring 2026 Frontier Systems course, weekly lectures from the people building the AI infrastructure stack.
📄 5 Papers
1. Self-Distilled RLVR
https://arxiv.org/abs/2604.03128
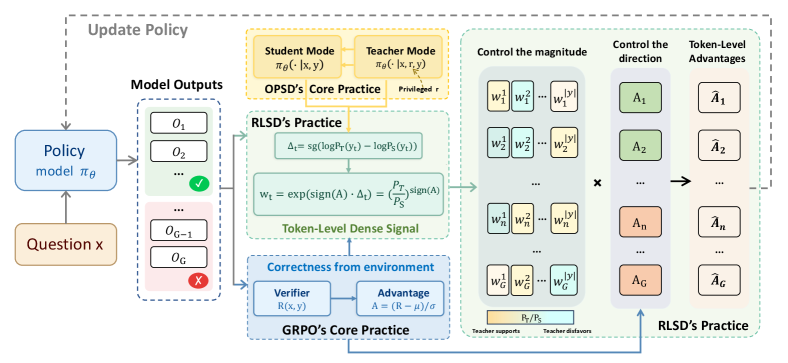
On-policy self-distillation (OPSD) was supposed to give RL training a denser gradient signal. In practice it leaks privileged teacher information into the student and destabilizes training past the early-peak stage. RLSD keeps RLVR’s environmental feedback as the direction signal and uses self-distillation only to set token-level update magnitudes. The result: +4.69% average over the base LLM and +2.32% over GRPO across five multimodal reasoning benchmarks (MMMU, MathVista, MathVision, ZeroBench, WeMath), without the late-stage collapse OPSD exhibits.
2. ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
https://arxiv.org/abs/2604.11784
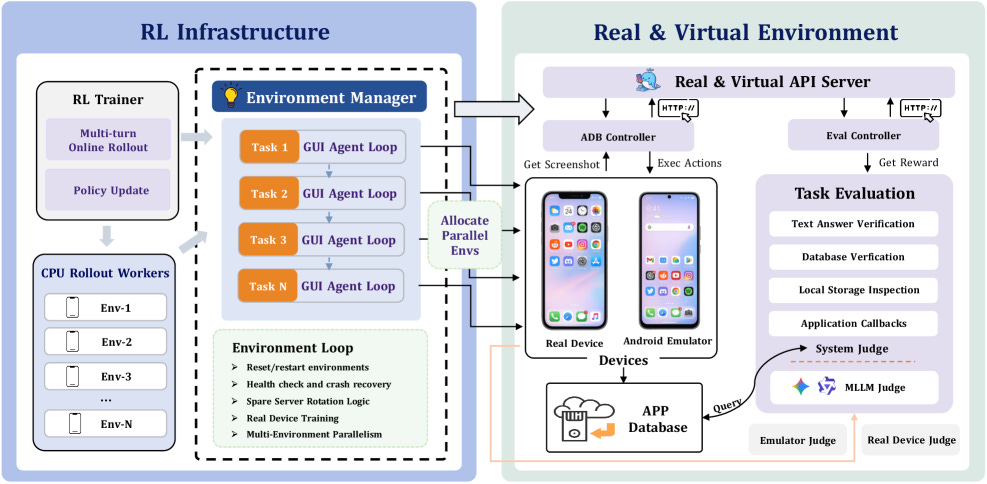
GUI agents aren’t stuck because the models are weak. They’re stuck because the training pipelines, eval harnesses, and deployment layers keep breaking in public, and nobody’s addressed all three at once. The authors cover all three layers: RL training with GiGPO plus a process reward model, 95.8% evaluation reproduction across 6 benchmarks, and cross-platform deployment to Android, HarmonyOS, and iOS with hybrid CLI-GUI control. ClawGUI-2B trained inside this pipeline hits 17.1% success on MobileWorld GUI-Only, beating the same-scale MAI-UI-2B baseline by 6 points and larger untrained models like UI-Venus-72B.
3. The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
https://arxiv.org/abs/2604.11297
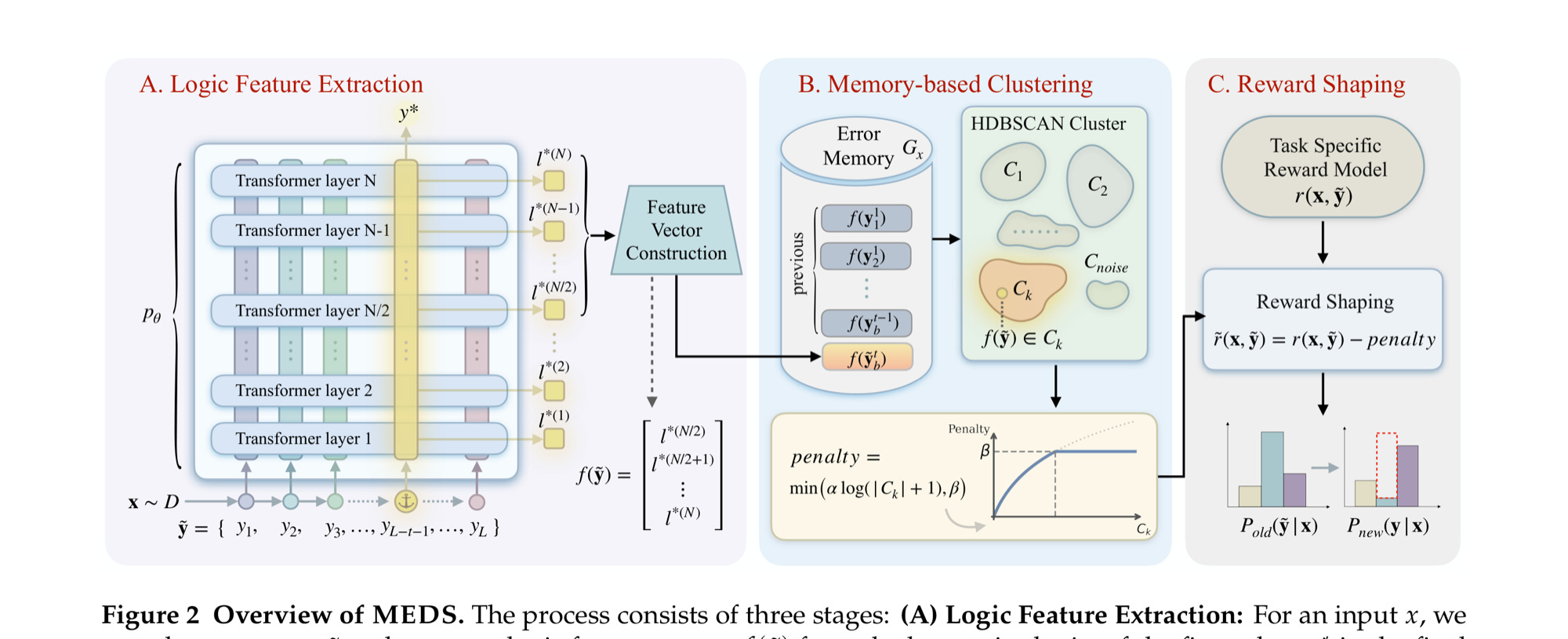
RL for LLMs keeps collapsing into the same wrong answers. Entropy regularization penalizes randomness within the current policy but ignores recurrent failure patterns across rollouts. MEDS stores historical model representations, clusters them with HDBSCAN to surface common error modes, and down-weights reward for rollouts landing in high-density error clusters. Up to 4.13 pass@1 points gained on math reasoning benchmarks, with measurably higher behavioral diversity and negligible compute overhead.
4. A Simple Baseline for Streaming Video Understanding
https://arxiv.org/abs/2604.02317
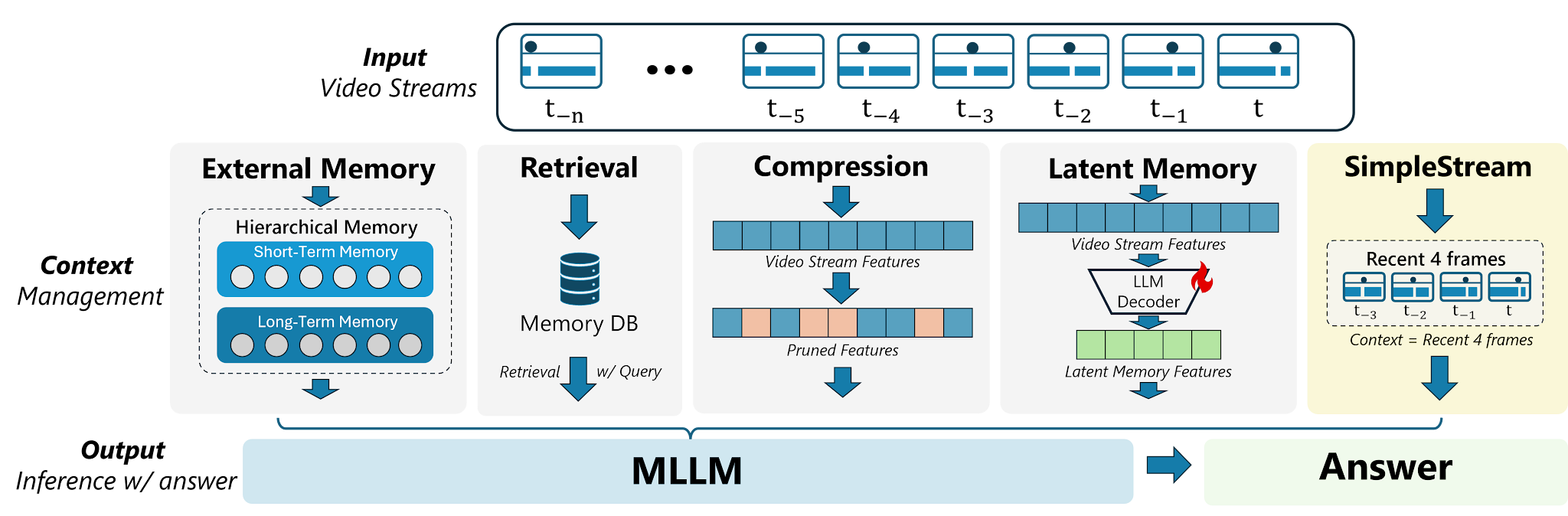
Streaming-video models keep stacking heavier memory mechanisms. A sliding window of 4 recent frames into an off-the-shelf VLM (SimpleStream) matches or beats 13 specialized baselines: 67.7% on OVO-Bench and 80.59% on StreamingBench. The deeper finding is a perception-memory trade-off. Longer context often helps recall but hurts real-time perception. Future streaming benchmarks need to separate the two or they’ll keep rewarding machinery for its own sake.
5. LRAT: Learning to Retrieve from Agent Trajectories
https://arxiv.org/abs/2604.04949 | GitHub
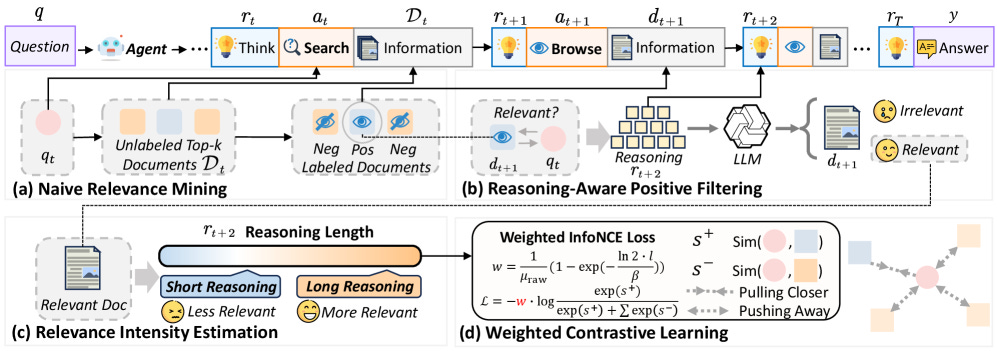
Retrieval models trained on human click and dwell logs are mismatched to how LLM agents query and consume results. LRAT derives retrieval supervision directly from agent trajectories (browses, unbrowsed rejections, and post-browse reasoning traces) with weighted relevance intensity. Evidence recall, task success, and execution efficiency all improve across agent scales, and the BM25 and FAISS pipelines are in the repo.
🎥 4 Videos
1. Notion’s Head of AI Engineering on Running Custom-Agent Evals at Scale
When every Notion user has a bespoke agent, eval becomes a combinatorial problem. Sarah Sachs (head of AI engineering at Notion) and co-founder Simon Last walk Latent Space through how they keep the signal alive through that explosion. Technical interview, not product marketing. Worth it if you’re past the “does the agent work on my test case” stage and need patterns for eval at scale.
2. What’s New in Gemma 4
A 60-second official overview from Google DeepMind on what changed between Gemma 3 and Gemma 4. Treat it as a trailer, not a tech report. The architecture and training deltas it calls out are the right ones to chase down in the model card afterward. Worth including because the open-weights frontier is where half the interesting work this edition lives.
3. Claude Cowork Tutorial for Non-Engineers with JJ Englert (Tenex)
First hands-on Claude Cowork walkthrough aimed at people without an engineering background. JJ Englert runs end-to-end setup and a real workflow, which is the kind of demo that travels because it proves the tool works without scaffolding. Watch this for the first clean demo of Cowork running end-to-end without an engineer in the loop.
4. Judge the Judge: Building LLM Evaluators That Actually Work with GEPA
Mahmoud Mabrouk from Agenta AI at AIE Europe on building LLM judges that don’t silently drift. GEPA (Gradient-free Evaluator Prompt Adaptation) is a practical recipe for keeping your judge calibrated as the underlying model and task distribution shift. Directly useful if you’re running eval harnesses in production and can’t afford quiet regressions.
📰 3 Curated Reads
1. Speeding Up GPU Kernels by 38% With a Multi-Agent System
https://www.cursor.com/blog/multi-agent-kernels
Cursor and NVIDIA show a coordinated agent swarm writing CUDA kernels (CUDA C with inline PTX, CuTe DSL, a shared markdown scratchpad as the coordination medium) that hits a 38% geomean speedup across 235 real kernels. Standout wins include 84% on grouped-query attention and real gains on MoE GEMMs where human-tuned baselines were already aggressive. Read this for the concrete coordination pattern, not the headline number alone.
2. Multimodal Embedding and Reranker Models With Sentence Transformers
https://huggingface.co/blog/multimodal-sentence-transformers
Tom Aarsen’s step-by-step guide to building cross-modal retrieve-and-rerank over text, image, audio, and video using Qwen3-VL-Embedding and Reranker. Working code you can copy tonight, with the full retrieve-then-rerank pipeline wired up in Sentence Transformers. Rare to get the full modern multimodal RAG stack wired up in one notebook. Clone it, run it, then decide whether you need anything more than this.
3. The Power of Mathematical Modeling

Manlio De Domenico guest-posts on Tivadar Danka’s Palindrome with a first-principles tour of mathematical modeling: the SI compartment model applied to the ILOVEYOU worm, a four-compartment SIZR extension for zombie outbreaks, and a network-science result showing that immunizing hubs beats random interventions. The SI-to-SIZR extension is the kind of move that sticks. You watch a textbook model flex to handle zombies without losing any of its explanatory structure, which is exactly the feel you want from a modeling tour. The hub-immunization result at the end is the payoff. Drop this into the week when the systems-and-tooling fatigue catches up with you.
🛠 2 Tools & Repos
1. VoxCPM2: Tokenizer-Free Multilingual TTS
https://github.com/OpenBMB/VoxCPM
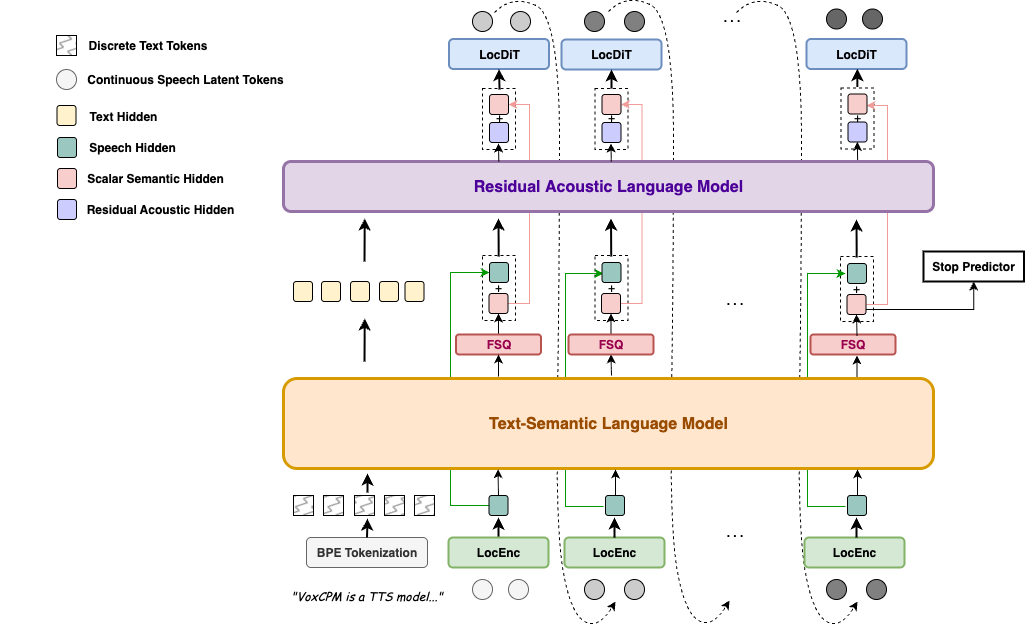
Tokenizer-free TTS system that generates continuous speech directly through a diffusion autoregressive architecture, bypassing discrete audio tokenization entirely. 30 languages, controllable voice cloning, voice design from text descriptions, and 48kHz studio-quality output. Over 13k stars and climbing fast. Pick this up if you’re building anything speech-facing and want to skip the usual codec-and-vocoder tax.
2. caveman
https://github.com/JuliusBrussee/caveman
A Claude Code / Codex / Gemini CLI plugin that instructs the agent to drop articles, filler, and pleasantries in its output while preserving technical content. Benchmarks in the README clock ~75% output token reduction and ~46% input token reduction with no quality loss on downstream evals. 30,800 stars in 11 days since launch. MIT, active maintainers, one-line install across seven agents. Worth the three-minute install if you’ve watched an agent burn context on “Certainly! I’d be happy to help you with that.” Note: Try it and test your luck :)
🎓 1 Pick of the Week
Stanford CS 153: Frontier Systems (Spring 2026)
https://www.youtube.com/playlist?list=PL2aDf5-VARtBwz1kz5FsuSZXOig2U6aJI
Stanford’s new Spring 2026 course on the AI infrastructure stack, taught by Anjney Midha (AMP PBC) and Michael Abbott. Weekly lectures from the people building the frontier: Andreas Blattmann on Black Forest Labs’ image models, Mati Staniszewski on ElevenLabs’ audio stack, and Midha himself on the infrastructure rewrite underneath this moment. Runs through June 3, with upcoming guests including Karpathy, Jensen Huang, Sam Altman, and Satya Nadella. The closest thing to a live running commentary on the stack as it’s being built.
That’s the twenty-fourth Tokenizer. If one of these fifteen resources changes what you’re building this week, forward the edition to whoever should see it next, and come find the long-form work at Gradient Ascent.