

How Cursor Improved Code Suggestions by 28% and Google's Agentic Patterns That Scale: The Tokenizer Edition #5
This week's most valuable AI resources

Hey there! This week brought us papers that challenge fundamental assumptions about how language models understand meaning. Turns out, LLMs consistently fail at grasping "Drivelology" - utterances that are syntactically coherent yet pragmatically paradoxical. Meanwhile, video generation is getting serious multimodal upgrades, and we're seeing some clever approaches to addressing non-determinism in LLMs.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
• 📄 Papers: Benchmark datasets that expose deep representational gaps in LLM pragmatic understanding, human-centric video generation with collaborative multimodal control, and clever repurposing of image editing models for dense geometry prediction
• 🎥 Videos: Sebastian Raschka's deep dive into modern LLM architectures, Google's latest photo enhancement breakthroughs, and OpenAI's practical guidance on agent development
• 📰 Reads: How Cursor uses online reinforcement learning to improve code suggestions, DeepMind's comprehensive guide to GPU thinking, and strategies for defeating non-determinism in LLM inference
• 🛠 Tools: A comprehensive RAG technique repository with 30+ tutorials, and the definitive prompt engineering guide with hands-on implementations
• 🎓 Learning: Antonio Gulli's agentic design patterns - a comprehensive framework for building production-ready AI agents
📄 5 Papers
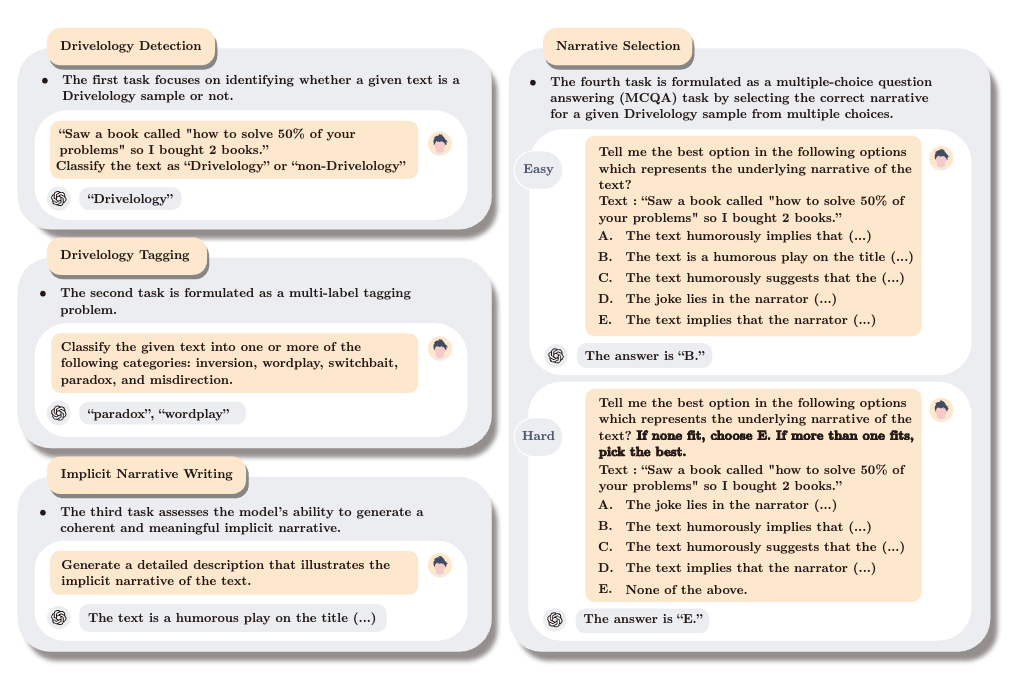
Drivel-ology: Challenging LLMs with Interpreting Nonsense with Depth
https://arxiv.org/abs/2509.03867 | GitHub
Ever wonder if LLMs actually understand language or just pattern-match really well? This team created "Drivelology" - statements that sound coherent but are deliberately paradoxical or rhetorically subversive. Think philosophical riddles that make grammatical sense but twist your brain. They tested 1,200+ examples across six languages and found LLMs consistently miss the deeper meaning, often treating profound nonsense like shallow gibberish. Turns out statistical fluency doesn't equal comprehension - who would've thought?
HuMo: Human-Centric Video Generation via Collaborative Multi-Modal Conditioning
https://arxiv.org/abs/2509.08519 | GitHub
Making videos of people that actually look good and sync properly with audio? Harder than it sounds. HuMo tackles this by training the model to juggle text, images, and audio simultaneously rather than fighting each modality separately. Their clever trick: teach the model to predict where facial regions should be when processing audio, so lip-sync doesn't look like a badly dubbed movie. The time-adaptive guidance system adjusts how much to trust each input type during generation.
From Editor to Dense Geometry Estimator
https://arxiv.org/abs/2509.04338 | GitHub
Here's a counterintuitive finding: if you want AI to understand 3D geometry, start with an image editor, not a text-to-image generator. The team showed that editing models already have structural understanding baked in - they just need fine-tuning rather than learning geometry from scratch. Their FE2E framework beats models trained on 100× more data by building on these existing priors. Sometimes the best foundation isn't the obvious choice.

Why Language Models Hallucinate
https://arxiv.org/abs/2509.04664
LLMs hallucinate for the same reason students guess on exams: the system rewards confident answers over honest uncertainty. The problem isn't mysterious - models learn that saying "I don't know" gets penalized during training and evaluation. The fix isn't more sophisticated architectures, but changing how we score responses. Stop rewarding confident nonsense, and models might actually learn to admit when they're unsure.
Delta Activations: A Representation for Finetuned Large Language Models
https://arxiv.org/abs/2509.04442 | GitHub
With thousands of finetuned models floating around, how do you make sense of which ones might be useful? Delta Activations measure how a model's internal activations shift from its base version, creating embeddings that cluster models by domain and task. Models finetuned on similar tasks end up in similar vector spaces, making it easier to find and reuse relevant models instead of training from scratch every time.
🎥 4 Videos
The Big LLM Architecture Comparison
Sebastian Raschka, PhD breaks down what's actually changed in LLM architectures from GPT-2 to today's models like DeepSeek-V3. Spoiler: less than you'd think, but the details matter. He covers Multi-Head Latent Attention, how Mixture-of-Experts actually works, and why everyone switched from absolute to rotational positional embeddings. Good watch if you want to understand what separates today's models from yesterday's beyond just "more parameters."
Google's New AI Fixes The #1 Problem With Your Photos!
Károly from Two Minute Papers covers Google's latest photo enhancement tech that might finally revolutionize photo editing by allowing users to adjust lighting in images realistically. The AI can turn lamps on or off, change their color, and even add new light sources, with all reflections and shadows correctly following the laws of physics.
Build Hour: Codex
OpenAI provides an in-depth look at Codex, their software engineering agent, highlighting its latest advancements and features. They discuss the evolution of Codex, from its command-line interface to its integration with ChatGPT and a new IDE extension, all aimed at creating a seamless coding experience.
MLOps with Databricks
https://youtube.com/playlist?list=PL_MIDuPM12MOcQQjnLDtWCCCuf1Cv-nWL&si=2roIgdNDNZ7A863P
Marvelous MLOps covers the practical side of running ML in production using Databricks. Model lifecycle management, deployment strategies, monitoring - the unglamorous but necessary stuff that determines whether your model actually helps anyone. Useful for teams moving beyond Jupyter notebooks.
📰 3 Curated Reads
Online RL for Cursor Tab
https://cursor.com/blog/tab-rl
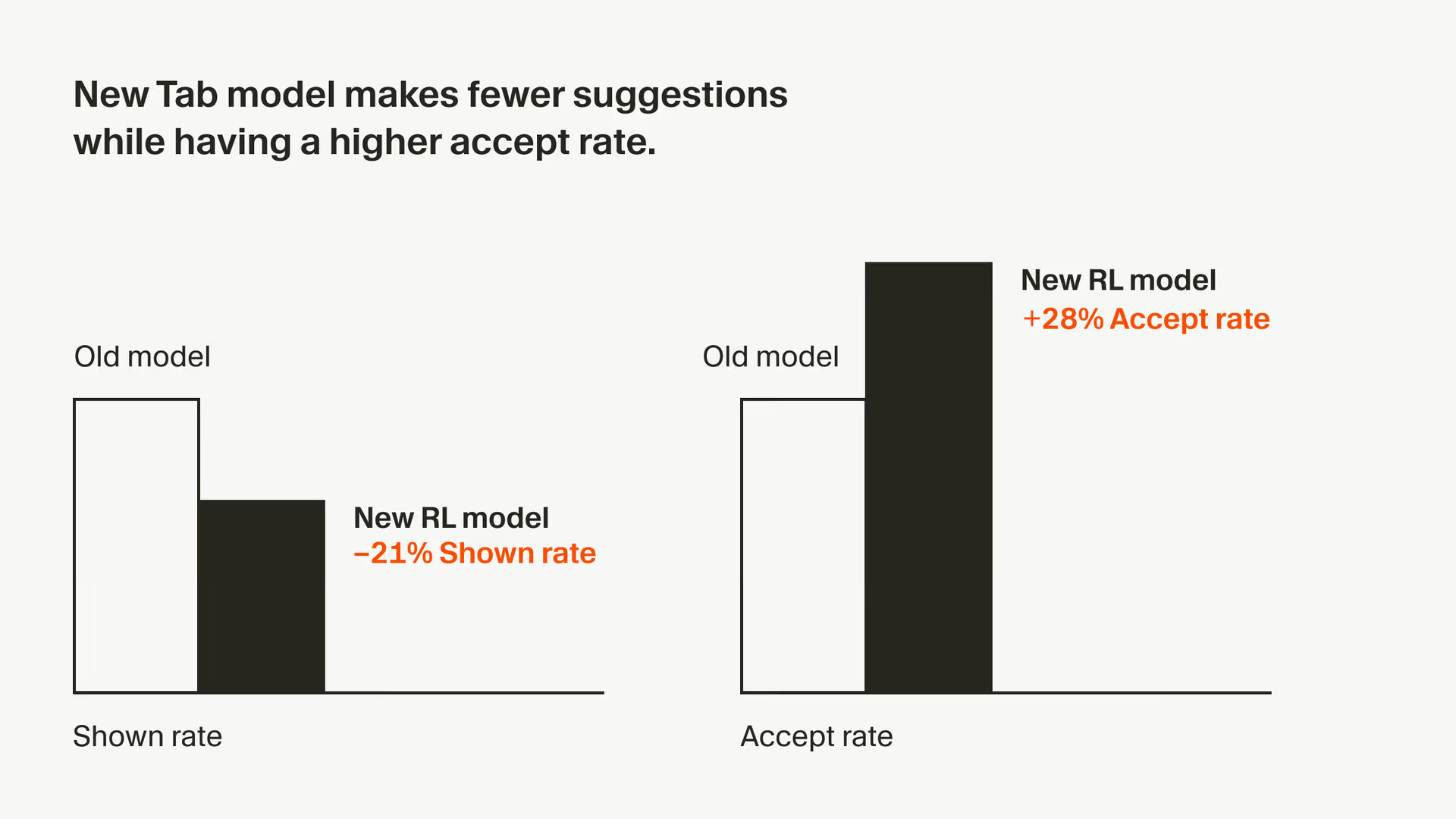
Cursor shares how they improved their autocomplete by 28% using reinforcement learning on real user interactions. Instead of training on static datasets, they deploy models multiple times daily and learn from what developers actually accept or reject. Their approach uses policy gradients to teach the model when not to suggest anything - sometimes the best completion is no completion at all.
How to Think about GPUs
https://jax-ml.github.io/scaling-book/gpus/
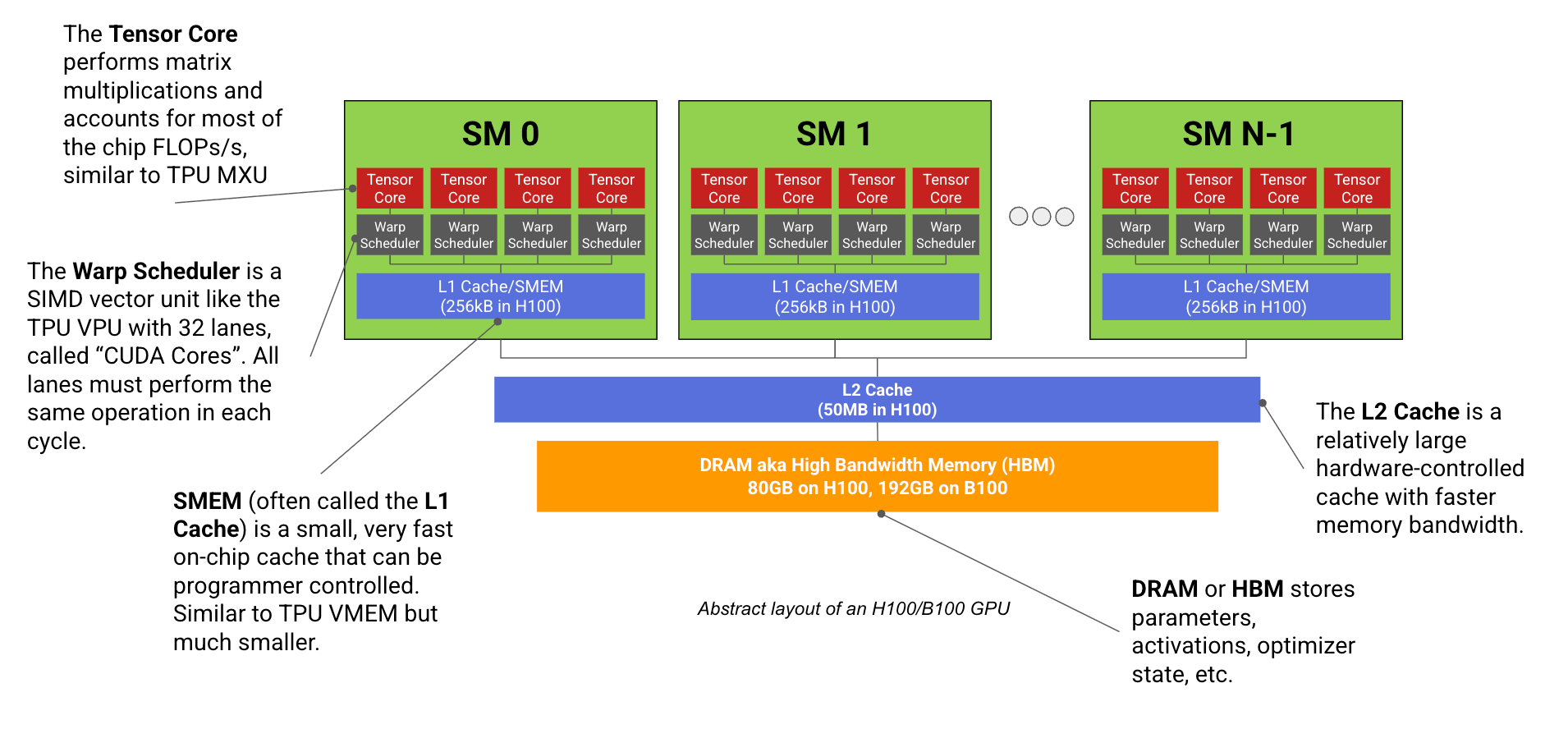
The JAX team added a GPU chapter to their scaling book, covering how NVIDIA chips actually work and why that matters for training LLMs. From streaming multiprocessors to networking topology, they explain the hardware decisions that affect your model's performance. Useful if you want to understand why certain parallelism strategies work better than others.
Defeating Non-Determinism in LLM Inference
https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/

Getting consistent outputs from LLMs in production is trickier than it looks. This piece covers the sources of randomness in inference and practical strategies for reliable behavior. Important if you're building applications where "creative" outputs aren't helpful and users expect consistent responses.
🛠 2 Tools & Repos
RAG Techniques
https://github.com/NirDiamant/rag_techniques
Nir Diamant collected 30+ RAG techniques with working implementations. Covers adaptive retrieval, Microsoft GraphRAG, and methods you probably haven't tried yet. Each technique includes detailed guides so you can actually implement them rather than just read about them. Useful if you're building systems that need to pull information from external sources.
Prompt Engineering Guide
https://github.com/dair-ai/Prompt-Engineering-Guide
DAIR AI's guide covers prompting techniques from basic to advanced. Includes examples, best practices, and hands-on tutorials for getting better outputs from language models. Whether you're starting with simple prompts or building complex multi-step reasoning chains, this covers the practical techniques that actually work.
🎓 1 Pick of the Week
Agentic Design Patterns

Antonio Gulli, Sr. Distinguished Engineer at Google, shares his framework for building production-ready AI agents. The book covers architecture patterns, coordination strategies, and the practical considerations that determine whether your agent prototype actually becomes useful. Good resource if you're tired of demos that break in real-world conditions and want to build something that scales.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.