

DeepSeek V4, LeCun's Bet Against LLMs, and Lovable's Self-Improving Agent - The Tokenizer Edition #30
This week's most valuable AI resources

Hey there! This week is about what AI actually costs once it leaves the demo: million-token context that is finally cheap, FP8 serving that nearly halves the latency slope, and the fidelity that quietly erodes when agents hand work to each other. Let’s dig in.
New here?
The Tokenizer is my weekly roundup of the best AI/ML papers, videos, articles, tools, and learning resources. I sift through the noise so you don’t have to. Subscribe to Gradient Ascent for the full experience:
TL;DR
What caught my attention this week:
📄 Papers: One-step text-to-image, RL for research agents with no verifiable reward, self-evolving spatial reasoning, an agent benchmark across 65 professional domains, and two sign-bit flips that wreck a network.
🎥 Videos: LeCun’s case for JEPA world models over LLMs, how DeepSeek V4 made million-token context cheap, Lovable’s hourly self-improvement loops, and why task quality drives 5x more RL uplift.
📰 Reads: FP8 KV-cache quantization that holds accuracy out to a million tokens, flow maps that turn diffusion into few-step generation, and how delegated work loses fidelity over long chains.
🛠 Tools: fork() for agent microVMs, and ninety percent context compression before the model sees it.
🎓 Learning: Build a modern LLaMA-style LLM from scratch, every line commented.
📄 5 Papers
1. Extending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation
https://arxiv.org/abs/2604.18168 | GitHub

Generating an image from a text prompt in a single forward pass, not dozens of diffusion steps. The authors find the real bottleneck is text representation: few-step synthesis only works when the encoder’s features are discriminative enough, so they pair an LLM text encoder with the MeanFlow framework. CVPR 2026, and the same gains carry over to standard diffusion models.
2. RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
https://arxiv.org/abs/2605.10899
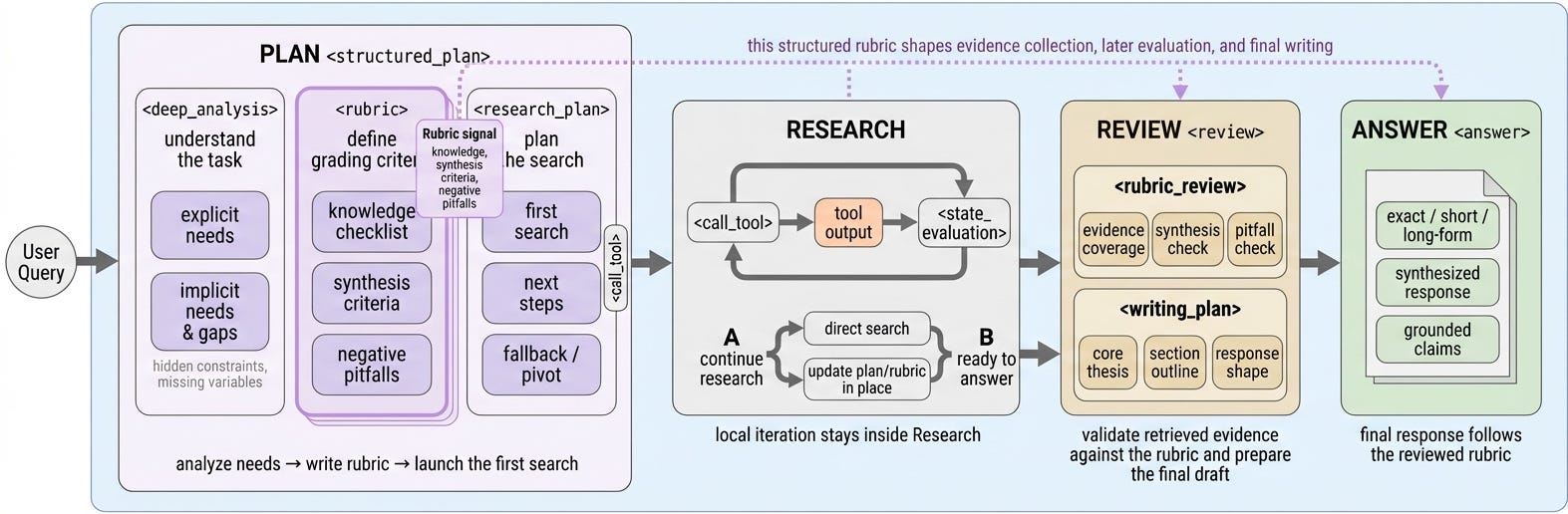
How do you run RL when the task is a long-form research report with no ground-truth answer to grade against? RubricEM turns rubrics into a shared interface that structures the agent’s planning, the judge’s feedback, and the agent’s memory, with denser per-stage credit assignment. The 8B model trained this way approaches proprietary deep-research systems across four long-form benchmarks.
3. SpatialEvo: Self-Evolving Spatial Intelligence via Deterministic Geometric Environments
https://arxiv.org/abs/2604.14144 | GitHub
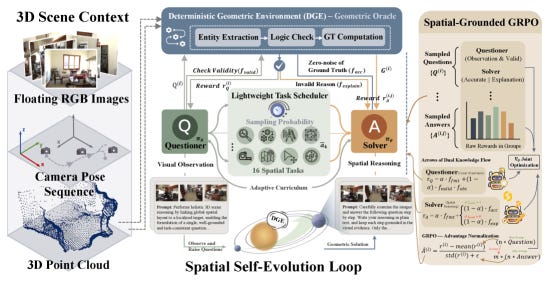
Self-training usually reinforces a model’s own mistakes, which is fatal for 3D spatial reasoning. The fix here: 3D ground truth is computable exactly from point clouds and camera poses, so unlabeled scenes become zero-noise oracles. One model uses them to co-evolve as both questioner and solver, with a scheduler that targets its weakest spatial skills. The 3B and 7B weights, a 160K dataset, and the simulator are all released.
4. OccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
https://arxiv.org/abs/2604.10866 | GitHub
A benchmark that drops agents into 100 professional scenarios across 65 specialized domains, from ED triage to customs, using LLM-simulated environments where no public sandbox exists. It scores two things: can the agent finish the task, and does it hold up when the environment injects errors and degraded data. One finding worth sitting with: being a strong agent does not make a model a strong environment simulator. Separately, GPT-5.2 gains 27.5 points going from minimal to maximum reasoning effort.
5. Maximal Brain Damage Without Data or Optimization: Disrupting Neural Networks via Sign-Bit Flips
https://arxiv.org/abs/2502.07408 | GitHub
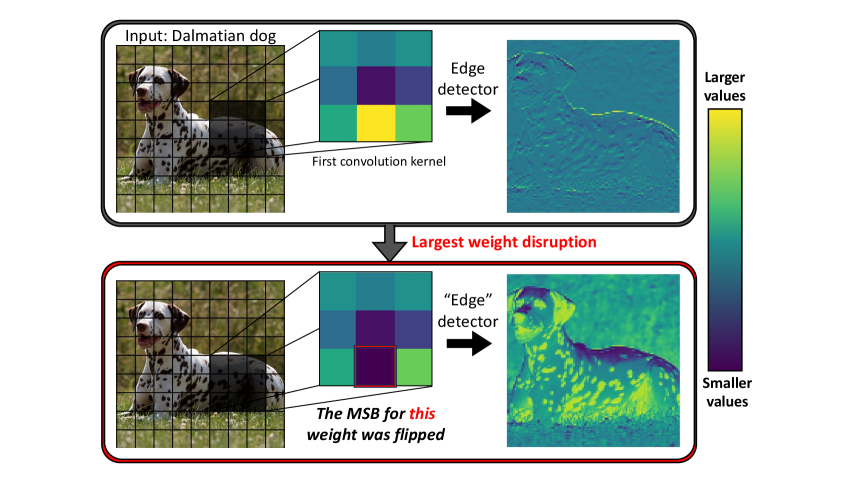
Two sign bits. Out of billions of weights. That is all it takes to drop ResNet-50’s ImageNet accuracy by 99.8 percent. The attack needs no training data and no optimization, just a structural method for finding the most critical parameters, with a one-pass variant that refines targets using random inputs. Two flips also take Qwen3-30B-A3B from 78 percent to zero. The same analysis points to a cheap defense: protect a small fraction of vulnerable sign bits.
🎥 4 Videos
1. Could JEPA world models replace LLMs? Walking up the vision-language-action stack
Yann LeCun’s argument that next-token prediction is a dead end, made concrete. Welch Labs walks up the vision-language-action stack and shows a JEPA-based alternative at each layer. One predicts text embeddings instead of generating tokens, reaching higher accuracy with fewer parameters. It stays honest about the limits: the world-model approach reliably plans only about 5 to 15 steps ahead today. Forty-one minutes, with LeCun interview footage.
2. How DeepSeek V4 made million-token context cheap
A clear breakdown of the two attention mechanisms behind DeepSeek V4’s cost drop: a compressed sparse attention that squeezes every four tokens into one cache entry, and a heavily compressed variant for cheap global attention. The number the video walks through is roughly a tenth of the KV cache and a quarter of the per-token compute at one million tokens, versus the previous version. This is focused on the architecture rather than the serving infrastructure.
3. How Lovable turns stuck users and a complaining agent into hourly self-improvement
Lovable creates more than 200,000 projects a day, and this talk shows the two feedback loops that let its coding agent fix a mistake once and not repeat it. One mines sessions where a non-technical user got stuck then unblocked, and asks what context should have been injected up front. The other gives the agent a “vent” tool to flag genuine frustration: within an hour of launch it filed about 20 complaints about a silent file-copy bug the logs never showed. Benjamin Verbeek of Lovable walks through both.
4. Why high-quality agentic tasks deliver 5x more RL uplift
Same model, same compute, same number of tasks: fine-tuning on high-quality agentic tasks lifted the base model about 6 percent, versus 1 percent for low-quality ones. That 5x gap comes from task quality alone. Kobie Crawford of Snorkel defines what high quality means (achievable, correct, logically sound, reliable environment) and shows that accepted tasks run about twice the tool calls and fail for cleaner reasons, which is the signal RL can actually climb.
📰 3 Curated Reads
1. The State of FP8 KV-Cache and Attention Quantization in vLLM
https://vllm-project.github.io/2026/04/22/fp8-kvcache.html
A practitioner’s report, not a paper abstract, on making FP8 KV-cache and attention quantization actually work in production serving. In memory-bound decoding the inter-token-latency slope drops to 54 percent of the BF16 baseline, and accuracy holds: 97 to 98 percent recovery at 128k context, with full recovery of the aggregate metric out at one million tokens. It is candid about the precision bugs that were silently degrading quality and the hardware caveats. Authors from AWS and Red Hat AI.
2. Learning the integral of a diffusion model
https://sander.ai/2026/05/06/flow-maps.html
Diffusion models predict velocity at a point; flow maps learn to predict any point along the whole noise-to-data trajectory, which is the same as learning the integral of that velocity field. That is what lets generation collapse from dozens of steps to a few. Sander Dieleman builds the intuition carefully, including the three consistency rules a flow map is trained under and the tricks (stop-gradient, finite differences, self-distillation) that avoid higher-order derivatives. This is the idea under the current wave of few-step samplers.
3. Further Notes on Microsoft’s Recent Research on AI Delegation and Long-Horizon Reliability
When one model hands its work to the next across many steps, fidelity to the original artifact quietly erodes. Microsoft Research measured roughly 19 to 34 percent degradation over 20 delegated iterations with strong models, while routing the same work through a structured Python-mediated workflow held the loss under 1 percent. The takeaway for agent pipelines: the failure is cumulative and mostly invisible per step, and structure beats raw model quality over long horizons.
🛠 2 Tools & Repos
1. forkd
https://github.com/deeplethe/forkd
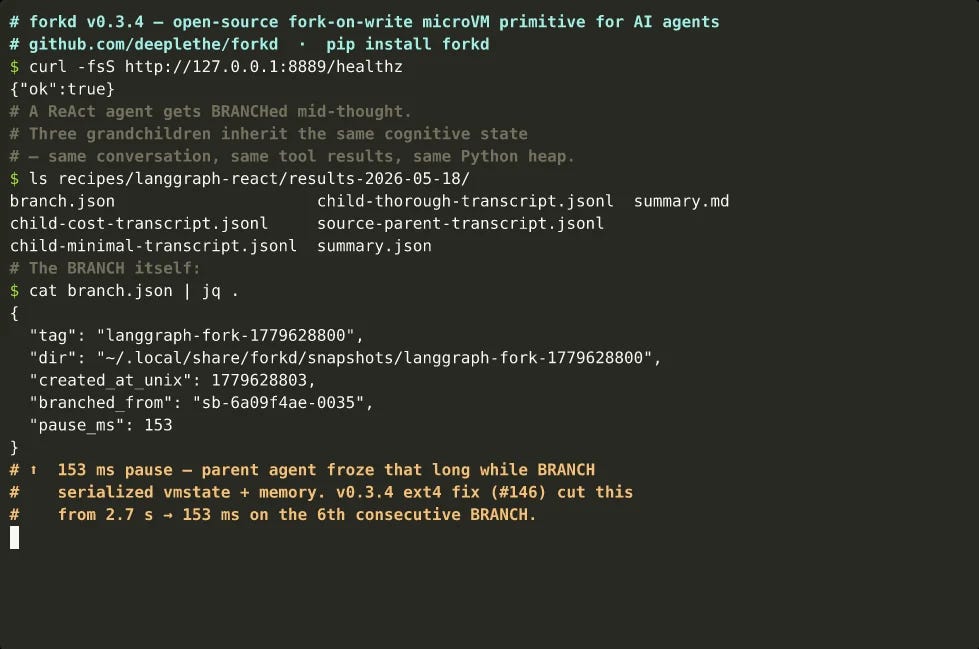
Spinning up a fresh sandbox per agent run means paying cold-start costs over and over: imports, JIT, model loading. forkd applies fork() to microVMs, spawning 100 KVM-isolated children in about 100 milliseconds from one warmed parent that shares memory copy-on-write, and it can branch a live VM in roughly 60 milliseconds. Built in Rust for code interpreters, eval harnesses, and untrusted-code platforms. It is alpha and Linux-only, and the benchmarks are the project’s own.
2. headroom
https://github.com/chopratejas/headroom
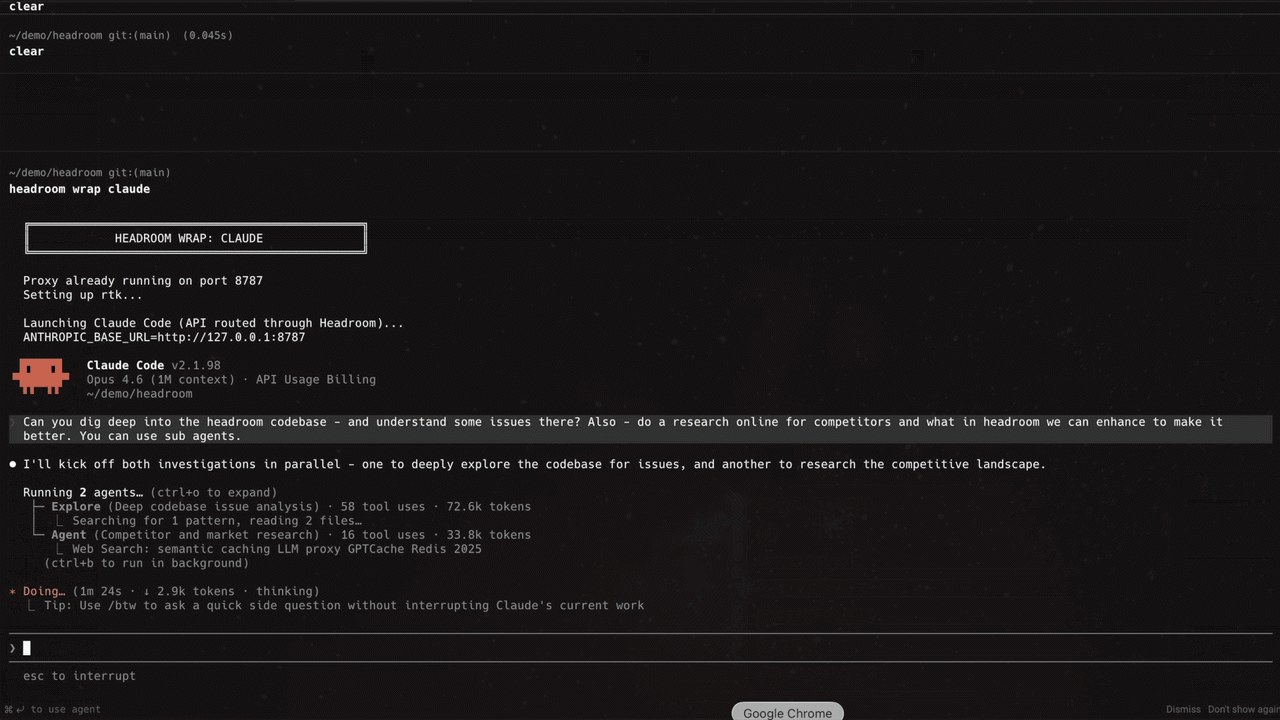
Agents read a lot of text they do not need in full: tool outputs, logs, RAG chunks, file dumps. headroom compresses that text before it reaches the model, with reversible storage so the model can call the original back when it matters. The project reports 60 to 95 percent fewer tokens with matched answers on its own eval suite, and it ships three ways: a library, an HTTP proxy, or an MCP server you point an existing agent at.
🎓 1 Pick of the Week
how-to-train-your-gpt
https://github.com/raiyanyahya/how-to-train-your-gpt
A from-scratch build of a modern LLM where every line of PyTorch is commented and each idea arrives as an analogy, then a worked number, then annotated code. Unlike the usual GPT-2-era tutorials, it targets the current LLaMA-style stack: RoPE, RMSNorm, SwiGLU, weight tying, and a KV cache. The only prerequisite is basic Python, the default model trains in minutes on a CPU, and a one-click Colab handles the GPU-scale version. Twelve chapters, plus a fine-tuning track that covers LoRA, QLoRA, and DPO.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights: