

Depth Anything, Vision Mamba, Self-Extending LLMs, and more...
A round up of the most interesting resources from the week gone by

These are some of the most interesting resources I found over the past week covering a range of topics in computer vision and NLP. If you’re a new reader, I alternate between curating resources and long-form writing. As always, your feedback and comments are welcome!
Depth Anything
Depth Anything is a streamlined approach to monocular depth estimation. Instead of adding new technical modules, it turns to a vast dataset (~62M unlabeled examples) to enhance adaptability and reduce errors. Using robust data augmentation and leveraging pre-trained encoders for semantic insights, it generalizes across diverse datasets and real-world images. This work is worth checking out.
Instant Identity-Preserving Generation
The authors propose a new method for identity-preserving image synthesis using just a single facial image. They introduce a plug-and-play module for enhancing existing text-to-image diffusion models like SD 1.5 and SDXL. By integrating an ID embedding with an Image Adapter and IdentityNet, InstantID can generate personalized images in a variety of styles while maintaining a high level of fidelity.

CamP and Zip-NeRF Code Released!
Researchers from Google have released implementations for both CamP and ZiP-NeRF. The implementations are in JAX and worth checking out if you're working on rendering and reconstruction projects.
Text-Driven Object Insertion in 3D Scenes
InseRF inserts 3D objects into NeRF reconstructions of scenes using textual descriptions and a 2D bounding box. It can generate new objects in 3D scenes with consistency across multiple views without needing explicit 3D information. The method involves grounding 3D object insertion to a 2D object insertion in a reference view, then lifting the 2D edit to 3D using a single-view object reconstruction method.
DocGraphLM: Documental Graph LM for Information Extraction
Researchers from JP Morgan integrate graph neural nets with pretrained language models to enhance document representation. The integration of graph neural features with language features and a novel link prediction approach leads to consistent improvements in information extraction and question-answering tasks, as well as faster convergence in learning. This framework marks a significant advancement in visually rich document understanding.
Vision Mamba: State Space Models for Vision
Vision Mamba (Vim) introduces a state space model approach for efficient visual representation learning. Vim marks image sequences with positional embeddings and employs bidirectional state space models, eliminating the reliance on self-attention. This leads to notable improvements in computation and memory efficiency, particularly with high-resolution images. Vim demonstrates superior performance in various vision tasks, including ImageNet classification, COCO object detection, and ADE20K semantic segmentation, while offering significant speed and memory advantages.

LoRA from Scratch
Sebastian Raschka has written a comprehensive guide on implementing LoRA from scratch. The tutorial is hands-on, offering practical insights and coding examples. It's an excellent resource for anyone looking to understand and implement LoRA in their machine learning projects.
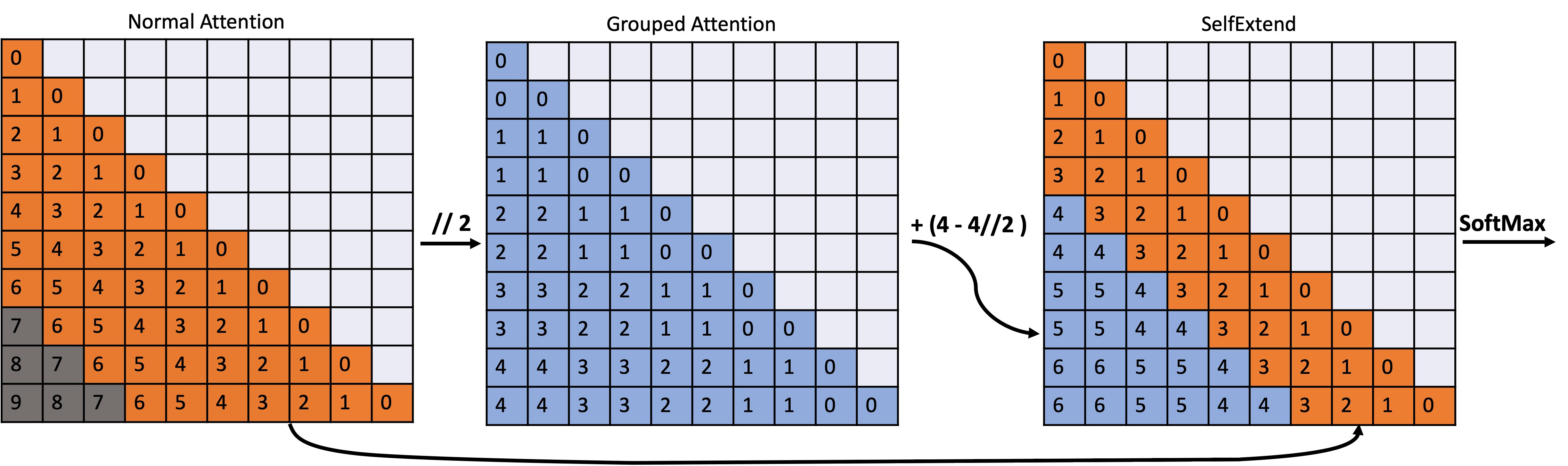
Self-Extend LLM Context Window without Tuning
This paper introduces a method for extending the context window of LLMs without the need for fine-tuning. The approach involves a simple mapping function and grouped attention, allowing the LLMs to handle longer contexts naturally–with just four lines of code change.
Excellent work