

Exponentially Faster Language Modeling
Blazing fast Transformers with no fuss?

This week, we'll look into a brilliant piece of research that might hold the key to blazing-fast Transformers. Quick announcement before we start– I'll announce the winners of the strategy session raffle in next week's edition. If you'd like to be considered in the draw, enter here.
Let's get started.
Exponentially Fast, Environmentally Conscious Language Modeling
Creating an image using generative AI models consumes the same amount of energy as charging a smartphone.
This isn’t a clickbait headline. It’s the findings of top researchers from HuggingFace and CMU.
Charging the average smartphone requires 0.012kWh of energy, which means that the most efficient text generation model uses as much energy as 16% of a full smartphone charge for 1,000 inferences, whereas the least efficient image generation model uses as much energy as 950 smartphone charges (11.49 kWh) or nearly 1 charge per image generation.
~ Luccioni et. al

Now, this might not seem like much, but it adds up really quickly. When you prompt a model like ChatGPT or Midjourney, how often does it get what you want in the first go? Until it does, we users either modify the prompt or click the nifty "regenerate" button and wait. Before long, we've done about 5-10 loops to get a result we're happy with.
Half a dozen smartphone charging sessions to perfect a knock-knock joke.
Now, these models serve up to 100 million users, 10 million of them active daily. That's a lot of charging and emissions to boot. As AI rapidly integrates into the fabric of our day-to-day lives, balancing innovation with ecological empathy has never been more critical.
How do we do this? We could make AI models energy efficient. Let's explore a few options.
Knowledge distillation allows us to transfer the learnings of a larger, complex teacher model into a smaller, more efficient student model. We'd use the student model in production to reduce energy consumption and emissions.
We could also leverage quantization or compression techniques to convert 32-bit numbers into 8-bit values. This would cut memory overhead by 4x and reduce computations by 16x. These models would be blazing fast and conserve energy at the same time.
But these aren't perfect.
Both methods usually result in a drop in accuracy, often by a non-trivial amount. They also need careful tuning for each new model we'd like to put into production. This is a significant challenge. After all, your end-users won't pay for a half-baked model.
Mixture-of-Expert (MoE) models have gained widespread popularity in the past couple of years. These models are ginormous (think hundreds of billions of parameters or larger) and involve multiple specialized sub-modules called "experts." Over the course of training, each expert learns to specialize in certain types of data from the training set. The training process also involves a gating mechanism that learns how to route data. The gate determines which expert(s) to send a data sample to. The outputs of these experts are then combined to produce the final result.
While these models are computationally expensive to train, they leverage a nifty trick during inference time. Since the gating mechanism routes data only to the "experts" it deems suitable, only a part of the giant MoE model is activated at a given time. Thus, we get the accuracy benefits of a large model and speed benefits from activating only a part of it.
However, training these models is resource-intensive and doesn't help the emissions problem we've discussed so far.
That brings us to an exciting development: Exponentially Faster Language Modeling and the promise of an ultra-fast BERT model.
Researchers from ETH Zürich have shown that it's possible to build blazing-fast Transformers without sacrificing too much accuracy. By simply replacing the feed-forward (a.k.a fully connected) layers in a BERT model with Fast Feed-Forward (FFF) layers, they show improvements of 78x on CPU over the standard BERT model1.
In fact, their model UltraFastBERT only engages 12 out of 4095 neurons for inference per layer.
That's just 0.3% of the neurons!
It's not just fast. UltraFastBERT retains at least 96% of the original BERT's downstream performance on the GLUE benchmark.
To summarize, this method retains most of the accuracy benefits, is orders of magnitude more efficient than its counterparts, and, crucially, has the potential to improve.2
Over the next few sections, we'll look at why UltraFastBERT might be a game changer, the secret sauce that powers it, how it compares against the closely related MoE models, and open questions that lie ahead.
Breaking UltraFastBERT Down
UltraFastBERT is similar to the crammedBERT architecture in almost all respects. It has the same number of layers. Each layer has the same number of attention heads and the same number of feedforward layers.
But there's one key modification that makes all the difference.3
It uses Fast Feed-Forward (FFF) layers instead of regular feed-forward layers. FFF layers use a differentiable binary tree structure to decide which neurons the input flows through. Thus, only a fraction of neurons are used at a time. Whether a neuron is used depends on the result of other neurons earlier in the tree.
Inference on FFF layers is just about performing conditional matrix multiplication. A dot product is computed between the rows of the input and the columns of the neural weights. The choice of which weight column to use depends on the previous dot-product operations.

This structure has a few notable advantages:
Selective activation (only a small set of neurons process the input) drastically reduces computation costs. For n neurons, a forward pass through a regular feed-forward layer is O(n), while it is O(log2(n)) for FFF layers.
Unlike off-the-shelf quantization or distillation methods, this speed-up comes without a drastic drop in accuracy.4
During training, the tree structure partitions the input data into regions. Thus, certain neuron blocks are optimized for specific types of input. This has downstream effects in terms of improved interpretability, surgical model editing, etc.
What about Attention?
Since the pre-training context size of BERT is 128, the per-token inference cost of its attention to all other tokens is only slightly more than the cost of a 128-neuron feedforward network. So, they leave the attention heads untouched.
There are further gains here, particularly for larger transformers. For example, we could consider using Flash attention instead of BERT's regular multi-head self-attention.
To summarize, UltraFastBERT replaces the feedforward layers with FFF layers. Given this change, does the training process change significantly? Let's look at that next.
Training UltraFastBERT
Long story short, nope. Nothing is different in the overall training process. The authors use the same crammedBERT recipe for training. But there's a difference in how the FFF layers learn.
During training, some neurons (called node neurons) in an FFF layer recursively make a soft choice (sigmoid activation) over the outputs of their two children.5 Based on the final loss computed at the end of a forward pass, the optimizer updates both the weights of the children and the parent node that made the choice.
Over time, this process, called hardening, fragments the large feed-forward layer into many smaller leaf layers while still maintaining predictive performance. This process gradually solidifies the boundaries of input space regions and the neuron blocks associated with them. So, specific neuron blocks work on specific inputs during inference.
FFF vs. MoE
Fast Feed-Forward layers can memorize training data and generalize to test data faster than MoE layers. They also appear to outperform MoEs for the same training width. In other words, they deliver representation power more readily than MoEs for a given width. They're also way faster as you increase the number of blocks.
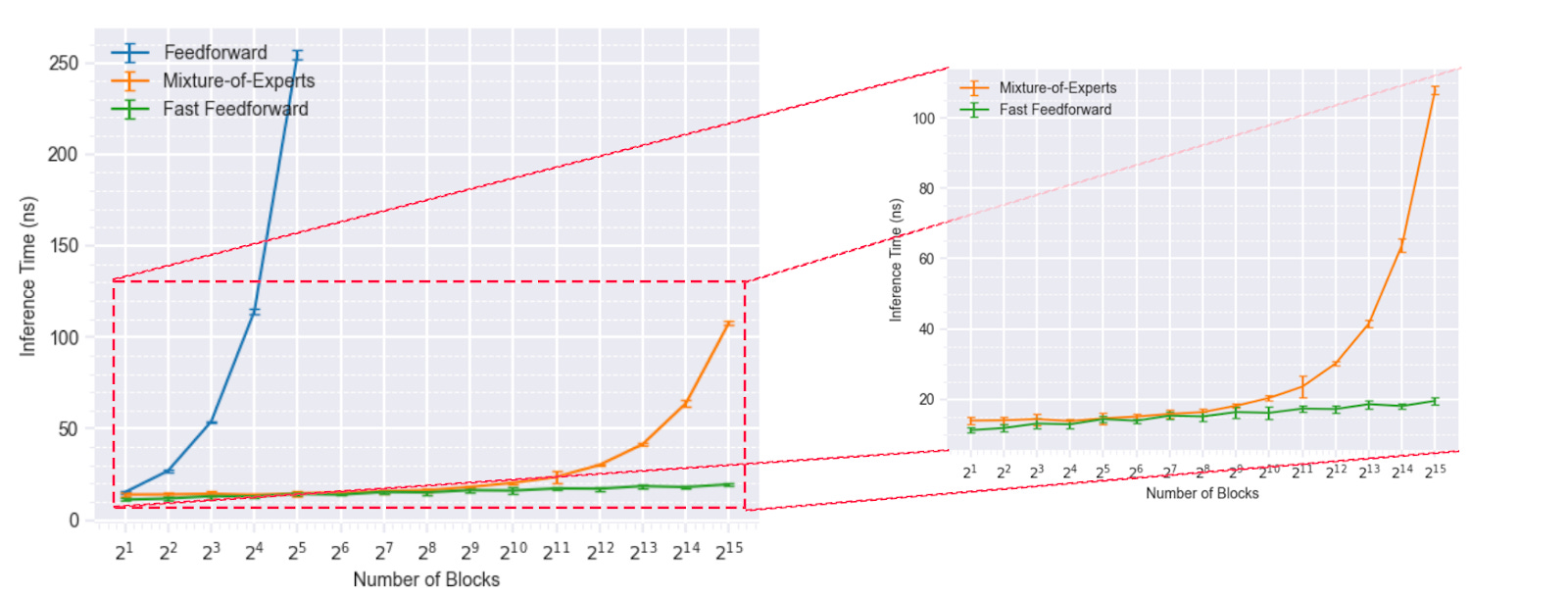
Naturally, the question of "Do MoEs matter anymore?" might arise in your head. I think they do. MoEs have proven that they're scalable and parallelizable. FFF layer-based networks need to prove that their results are possible at scale, particularly given the conditional nature of execution. At the moment, we have results for BERT. Let's look at that next.
A GLUE to the Future
UltraFastBERT retains 96% of BERT's performance on the GLUE benchmark. In the table below, each UltraFastBERT model has two numbers next to its name. The first is the depth of each FFF layer. The second is the number of trees. While performance might appear to drop with increasing depth, this is only true for the CoLA task. When you remove it from the overall benchmark, this model retains 98% of BERT's performance.

The best model from the set, UltraFastBERT-1x11-long (that's a mouthful), is on par (debatable) with the original BERT-base model while using only 0.3% of its neurons!
But that's not the main reason why we're interested in this approach, right? Here's how it stacks up in inference speed.

To put these numbers in context, imagine if we took GPT-3 and replaced all the feed-forward layers with FFFs. If trainable, this network could be replaced with an FFF counterpart with a maximum depth of 15. Such a network would use only 16 out of 65536 neurons for inference. There's a lot of potential to accelerate monstrous transformers. However, until proven, this remains a pipe dream.
Possibilities and Probabilities
FFFs aren't without imperfections, though. For starters, you could run into over-fragmentation while training them. If the network divides the input space into too many disjoint regions, this could lead to localized overfitting and the shrinking batch problem. The latter results in parts of the tree not learning much during training because there are insufficient examples.
Using larger batch sizes, lower learning rates, and gradient accumulation techniques can help somewhat alleviate this.
Conditional neural execution isn't heavily optimized (to the best of my knowledge), and without this, we might not realize the full acceleration potential of this approach. Finally, while BERT is a great starting point, modern transformers are orders of magnitude larger. These come with challenges like training instability, distributed training orchestration, and the need for careful hyperparameter optimization, to name a few.
If we introduce FFF layers into these architectures, would it work out of the box? I don't think so. Solving these challenges might pave the way for truly efficient models that deliver world-class performance.
At the end of the day, the quest for more efficient, less resource-intensive models isn't just a technical challenge. It's a crucial step towards sustainable innovation in AI. Recognizing the environmental impact of these large models is the first step toward addressing this challenge. As we continue to push the boundaries of what's possible, it's imperative that we also nurture our planet.
Planting trees, whether real or digital, might hold the key to a greener future.
Glossary
Feed-Forward Layers: Layers in neural networks where the output of each neuron goes to all neurons in the next layer without any feedback or memory elements.
Fast Feed-Forward (FFF) Layers: A modification of the standard feed-forward layers in neural networks, using a binary tree structure to reduce the number of active neurons during computation.
Knowledge Distillation: A technique where a smaller, more efficient "student" model is trained to reproduce the behavior of a larger, more complex "teacher" model.
Quantization: The process of reducing the precision of the numbers used in a model, typically from 32-bit to 16-bit or 8-bit, to minimize memory usage and increase computational efficiency.
Compression Techniques: Methods used to reduce the size of a neural network, often to decrease memory footprint and speed up inference.
Mixture-of-Expert (MoE) Models: Large-scale neural networks that contain multiple specialized sub-modules (experts), where each expert is trained on different types of data.
Gating Mechanism: In MoE models, a system that decides which expert sub-module should handle a given piece of data.
UltraFastBERT: A version of the BERT model with feed-forward layers replaced by Fast Feed-Forward layers, significantly improving computational efficiency.
Node Neurons: In the context of FFF layers, these neurons make decisions on which child neurons should be activated based on the input data.
Hardening Process: A training process in FFF layers where the network's decision boundaries become more defined over time.
Over-Fragmentation: A potential issue in training FFF layers where the input space is divided into too many small regions, leading to overfitting.
Shrinking Batch Problem: A challenge in neural network training where parts of the network receive too little data to learn effectively.
Gradient Accumulation: A technique used in training neural networks, especially with large models or small batch sizes, to accumulate gradients over multiple steps before updating model weights.
References
Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
Gou, Jianping, et al. "Knowledge distillation: A survey." International Journal of Computer Vision 129 (2021): 1789-1819.
Siddegowda, Sangeetha, et al. "Neural network quantization with ai model efficiency toolkit (aimet)." arXiv preprint arXiv:2201.08442 (2022).
Shazeer, Noam, et al. "Outrageously large neural networks: The sparsely-gated mixture-of-experts layer." arXiv preprint arXiv:1701.06538 (2017).
Belcak, Peter, and Roger Wattenhofer. "Fast Feedforward Networks." arXiv preprint arXiv:2308.14711 (2023).
Geiping, Jonas, and Tom Goldstein. "Cramming: Training a Language Model on a single GPU in one day." International Conference on Machine Learning. PMLR, 2023.
Belcak, Peter, and Roger Wattenhofer. "Exponentially Faster Language Modelling." arXiv preprint arXiv:2311.10770 (2023).
Luccioni, Alexandra Sasha, Yacine Jernite, and Emma Strubell. "Power Hungry Processing: Watts Driving the Cost of AI Deployment?." arXiv preprint arXiv:2311.16863 (2023).
Using high-level CPU code. The speedups are 40x with a Pytorch implementation which is still staggering!
The authors note that there are further optimization opportunities despite the already ridiculous speed-up.
The authors of UltraFastBERT use GeLU activation for all nodes, they fix the leaf size to 1, and they allow multiple FFF trees in parallel.
We'll need to see this play out for more models and datasets, but BERT is a pretty good starting point.