

Google Compresses KV-Cache 6x Without Training, How Every Modern Attention Variant Works, and a Claude Code Cheat Sheet - 📚 The Tokenizer Edition #21
This week's most valuable AI resources

Hey there! This week’s theme is speed: faster OCR through diffusion, faster inference through speculative execution, faster compression through polar coordinates, and Stripe shipping 1,300 agent-written pull requests every week. Whether you’re optimizing tokens, transistors, or team velocity, there’s something here for you.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Diffusion-based OCR that’s 3x faster, a package manager for AI agent skills, world modeling from Monster Hunter, probability-aware RL clipping, and speculative shortcuts for agentic vision systems
🎥 Videos: Stripe’s internal AI coding agents at scale, building your own AI operating system from scratch, DeepSeek’s conditional memory for transformers, and going from Figma design to working code with Claude
📰 Reads: Sebastian Raschka’s visual taxonomy of attention mechanisms, Google’s training-free KV-cache compression via polar coordinates, and why on-device AI needs new architectures (not smaller cloud models)
🛠 Tools: ByteDance’s filesystem-based context database for AI agents, and Cornell’s free GPU architecture course
🎓 Learning: A beautifully maintained Claude Code cheat sheet that doubles as a feature discovery tool
📄 5 Papers
1. MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding
https://arxiv.org/abs/2603.22458 | GitHub
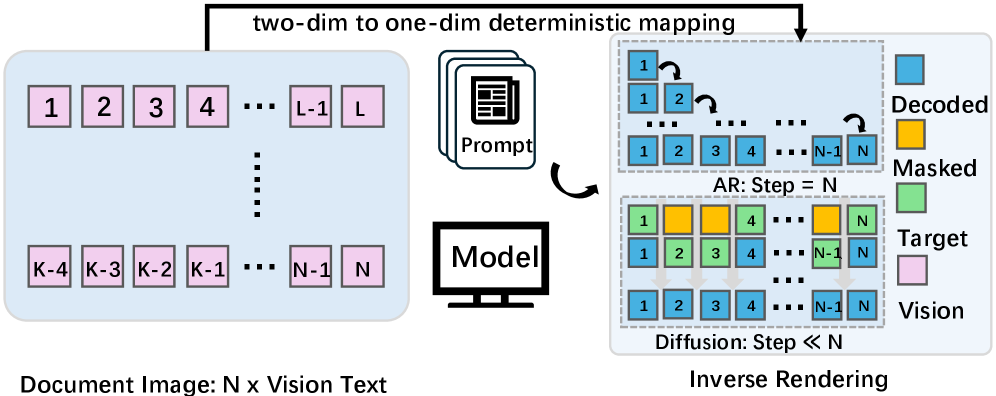
What if OCR didn’t need to generate text one token at a time? This paper replaces autoregressive decoding with block-wise diffusion denoising, reframing document OCR as inverse rendering. The result: up to 3.2x faster throughput with a tunable speed-accuracy tradeoff depending on your pipeline needs. A proposed “Semantic Shuffle” benchmark shows the model genuinely reads visual structure rather than leaning on linguistic shortcuts.
2. SkillNet: Create, Evaluate, and Connect AI Skills
https://arxiv.org/abs/2603.04448 | GitHub
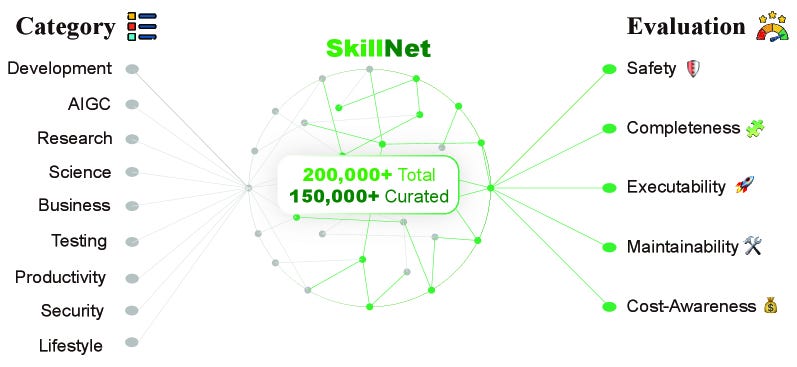
Think npm, but for AI agent skills. SkillNet treats agent capabilities as shareable, composable packages with a unified ontology for creating skills from heterogeneous sources (repos, docs, logs, prompts) and connecting them through dependency graphs. The framework delivers a 40% improvement in average rewards and 30% fewer execution steps across ALFWorld, WebShop, and ScienceWorld. With 200,000+ skills in the repository and a Python toolkit plus Open Access API, this could become critical infrastructure for the tool-using agent ecosystem.
3. WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
https://arxiv.org/abs/2603.23497 | GitHub
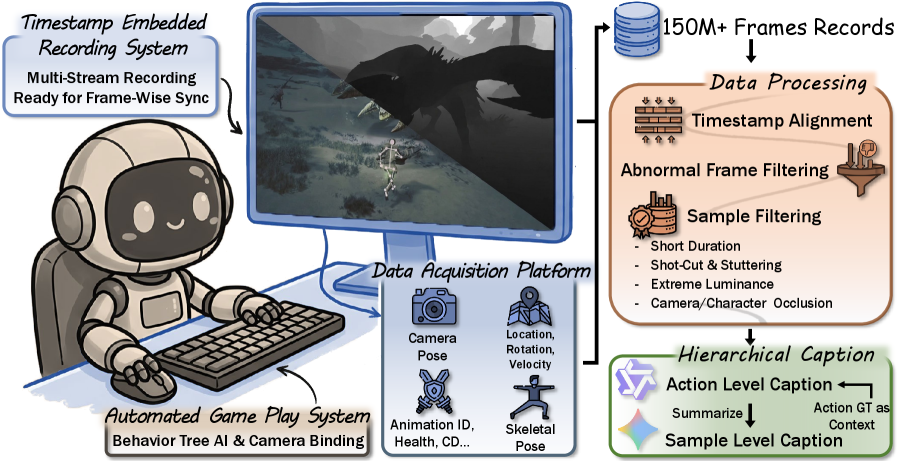
Most world-modeling datasets treat video prediction as frame interpolation. WildWorld takes a different approach: 108 million frames automatically collected from Monster Hunter: Wilds, with per-frame action labels (450+ semantically meaningful actions), character skeletons, world states, camera poses, and depth maps. The key insight is decomposing dynamics into action, state, and pixels separately, giving world models the causal structure they need to simulate rather than interpolate.
4. BandPO: Bridging Trust Regions and Ratio Clipping via Probability-Aware Bounds for LLM Reinforcement Learning
https://arxiv.org/abs/2603.04918 | GitHub
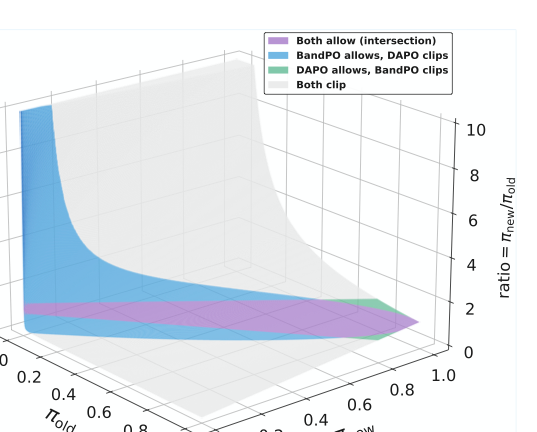
PPO’s fixed clipping bounds have a quiet failure mode: they disproportionately suppress high-advantage, low-probability actions, which are exactly the exploratory tail strategies you want to preserve in reasoning tasks. BandPO replaces static bounds with dynamic, probability-aware intervals derived from f-divergence constraints, formulated as a convex optimization problem with closed-form solutions. Tested on Qwen2.5 and Llama3 for mathematical reasoning, it consistently outperforms canonical GRPO clipping while preventing entropy collapse. A drop-in replacement for anyone doing GRPO-style training post-DeepSeek-R1.
5. SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
https://arxiv.org/abs/2603.23483 | GitHub
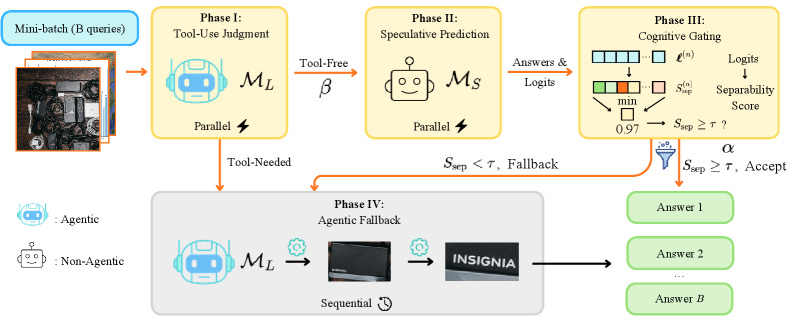
Agentic vision systems are slow because every query triggers a full sequential tool-use chain, even when the answer is straightforward. SpecEyes uses a lightweight gating mechanism (based on top-K logit gaps) to predict when the expensive pipeline can be short-circuited. The result: up to 3.35x speedup (averaging 1.4-1.7x across benchmarks) with accuracy maintained or improved by up to 6.7%. The gating requires no labeled routing data, making it deployable without per-task annotation on any production agentic vision system where latency matters.
🎥 4 Videos
1. Building a Full-Stack AI Operating System from Scratch
A three-layer architecture for a personal AI platform: webhook-driven triggers, scheduled workflows (cron-style recurring tasks), and an autonomous agent layer with persistent context and reusable skills. Dave Ebbelaar builds the entire system on FastAPI, Celery, Redis, and Docker. This 28-minute walkthrough gives you the blueprint instead of cloning random agent repos.
2. DeepSeek’s Engram: Adding Conditional Memory to Transformers
DeepSeek’s Engram module adds O(1) lookup memory to transformers by modernizing n-gram embeddings as a new sparsity dimension alongside Mixture-of-Experts. Dr. Karoly Zsolnai-Feher (Two Minute Papers) explains how it outperforms comparable MoE baselines at 27B parameters on both parameter and compute budgets. The surprise: the biggest gains show up not in knowledge retrieval (MMLU +3.4) but in reasoning (BBH +5.0, ARC-Challenge +3.7), because offloading pattern reconstruction to memory frees attention depth for harder tasks.
3. From Figma Design to Working Code with Claude Code and MCP
Figma mockup to working website in 15 minutes, FigJam flowchart to a working game, then exporting code back to Figma as editable components. Felix Lee (designer at ADPList) demonstrates the full design-to-code loop using Claude Code with Figma MCP in this 50-minute session hosted by Peter Yang. The core insight: MCP reads every color, spacing value, and component variant directly from Figma, eliminating the translation loss in design-to-dev handoffs.
4. How Stripe Ships 1,300 AI-Written Pull Requests Per Week
Stripe built internal AI coding agents called “minions” that now ship roughly 1,300 PRs per week. Steve Kaliski (software engineer at Stripe) walks through the architecture: Goose (Block’s open-source agent harness) with cloud dev environments, activated from Slack via emoji reactions. The key takeaway: Stripe’s existing investment in developer tooling (CI, testing, linting) made agent adoption frictionless, because good DX for humans turns out to be good DX for agents too. Non-engineers at Stripe now use minions to ship code.
📰 3 Curated Reads
1. A Visual Guide to Attention Variants in Modern LLMs

Seven attention mechanism families in one visual taxonomy, from classic Multi-Head Attention through GQA, DeepSeek’s Multi-Head Latent Attention, Sliding Window Attention, and hybrid architectures mixing transformers with linear or state-space modules. Sebastian Raschka diagrams how queries, keys, and values interact in each variant, how KV-cache mechanics change, and how memory growth curves differ. The practical payoff: a clear framework for choosing the right attention mechanism based on your model scale and deployment constraints, with Gemma 3 and DeepSeek V2 as case studies.
2. TurboQuant: Redefining AI Efficiency with Extreme Compression
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
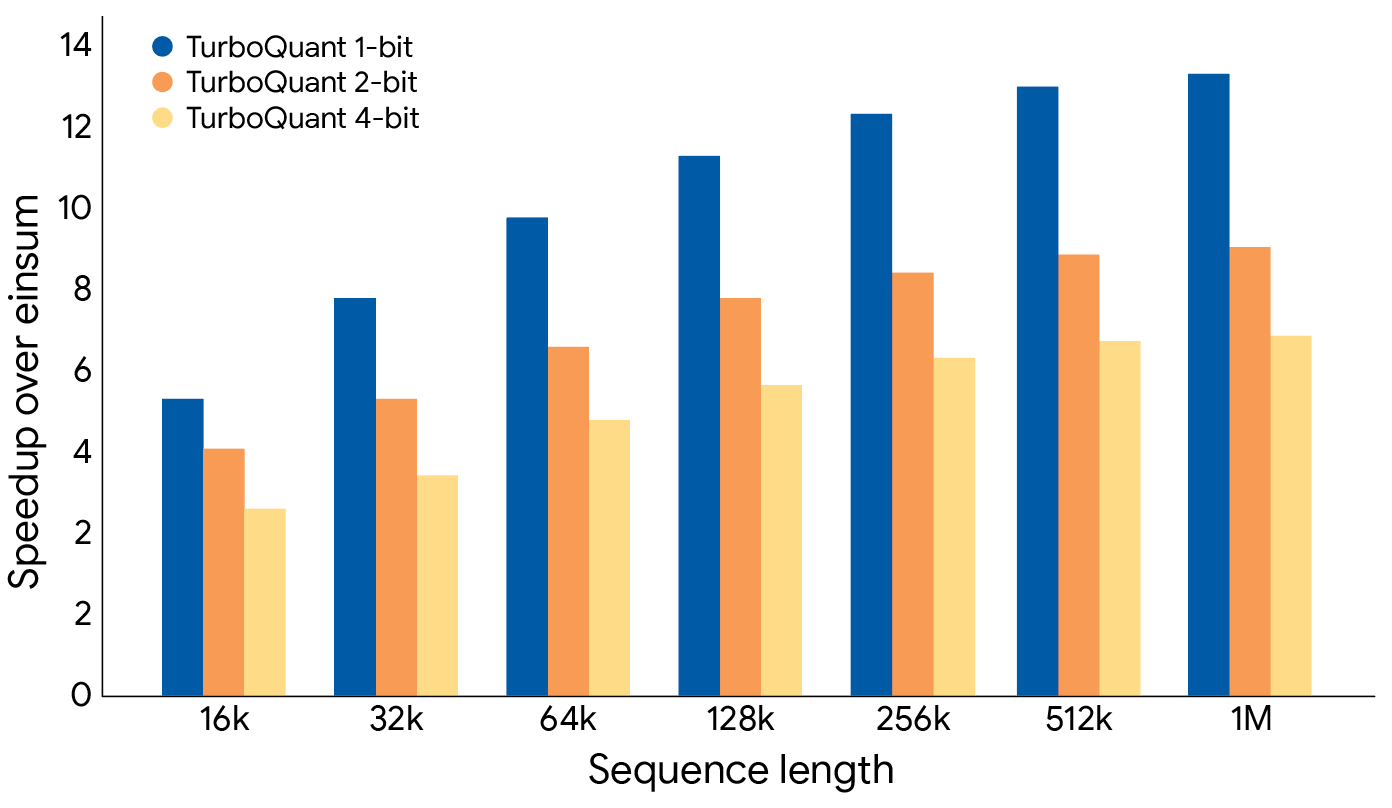
Google Research introduces a training-free, data-agnostic compression algorithm that achieves 3-bit KV-cache quantization without accuracy loss. The trick: PolarQuant converts data vectors from Cartesian to polar coordinates (concentrating angle patterns predictably), then QJL reduces residual errors to single sign bits via random projections. On H100 GPUs, TurboQuant delivers a 6x reduction in KV memory and up to 8x performance gains over 32-bit unquantized baselines. Unlike most quantization work, this targets the KV-cache specifically (the bottleneck that grows with context length) and requires zero calibration data or fine-tuning.
3. The Future of On-Device AI

Devansh argues the real bottleneck for on-device AI is memory bandwidth, not compute. Using Liquid AI’s LFM2 (1.2B parameters, runs on Samsung Galaxy S25) as a case study, the piece shows why shrinking data-center models is the wrong approach. LFM2 uses 10 gated short convolutions plus 6 grouped-query attention blocks, cutting peak cache to 192 MB at 32K tokens (versus Llama 3.2 1B’s 524 MB). It matches Qwen3-1.7B on benchmarks despite having 42% fewer parameters and runs at 70 tokens per second on a phone CPU. The thesis: the field needs device-native architectures designed from scratch, not miniaturized cloud models.
🛠 2 Tools & Repos
1. OpenViking: A Context Database for AI Agents
https://github.com/volcengine/OpenViking
ByteDance’s open-source solution for the “stuff everything into the prompt” problem. OpenViking organizes agent context (memories, resources, skills) into a navigable filesystem hierarchy with three-tier demand-based loading, so agents only consume tokens for what they actually need. It combines directory-based navigation with semantic search, auto-compresses conversations into long-term memory, and provides visualization of retrieval trajectories for debugging. 19.1K stars, Apache 2.0, supports major LLM providers via LiteLLM.
2. Cornell Virtual Workshop: GPU Architecture Fundamentals
https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/design

Free, NSF-funded course from Cornell’s Center for Advanced Computing covering why GPUs work the way they do: transistor allocation tradeoffs, memory hierarchies, parallelization design choices, and the practical implications for your code. Modules covering fundamentals through V100 and RTX 5000 deep dives, with exercises. No parallel programming experience assumed. If you call `.cuda()` daily but lack a mental model for what happens underneath, start here.
🎓 1 Pick of the Week
Claude Code Cheat Sheet
https://cc.storyfox.cz/

This single page Claude code cheat sheet covers 100+ commands across 8 color-coded sections: keyboard shortcuts, ~40 slash commands, MCP server configuration, memory and files, workflows, config, skills and agents, and CLI flags. Commands like `/btw` for side questions without derailing context, `/schedule` for cloud-scheduled tasks, and git worktree isolation with sparse checkout are buried in docs but surfaced here at a glance. Auto-detects Mac versus Windows, prints cleanly to A4, works offline, and updates daily as Claude Code evolves.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.