

Google's Antigravity 2.0, Awesome DESIGN.md, and Anthropic's HTML Specs: Tokenizer #29
This week's most valuable resources

Hey there! This week, models start slipping well before they hit their context limits. Thousand-line markdown plans go unread. Delegated work can lose up to a third of its fidelity over 20 steps. The answer in each case is better infrastructure. Let’s dig in.
New here?
The Tokenizer is my weekly roundup of the best AI/ML papers, videos, articles, tools, and learning resources. I sift through the noise so you don’t have to. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Models that mine their own skills from context, reconstruct 3D scenes from streaming video, and reason step-by-step over audio.
🎥 Videos: Four ways to fight context degradation. Anthropic explains why they ditched thousand-line markdown plans.
📰 Reads: Pass^K reveals agents are less reliable than benchmarks claim. Microsoft asks what happens when AI delegates to AI.
🛠 Tools: A new file search runs sub-10ms by skipping fork overhead. A DESIGN.md spec library turns your coding agent into a designer.
🎓 Pick: Google released a full agent ecosystem at I/O. The bundle includes an app, a CLI, an SDK, and managed agents.
📄 5 Papers
1. From Context to Skills: Can Language Models Learn from Context Skillfully?
https://arxiv.org/abs/2604.27660 | GitHub
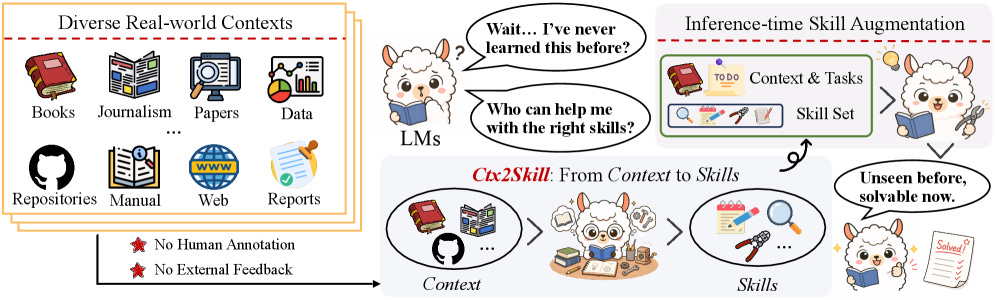
Ctx2Skill teaches a model to discover, refine, and select its own natural-language skills for unfamiliar contexts, with no human labels or external feedback. One frozen model fills several roles in a self-play loop: a Challenger invents probing tasks, a Reasoner solves them with an evolving skill set, and a Judge scores the result. A cross-time replay step keeps the best-balanced skills from past rounds, which stops the loop from collapsing into ever more extreme tasks. The skills then plug into any model at inference time. Across GPT-4.1, GPT-5.1, and GPT-5.2, solve rate climbs 3.2 to 5.4 points.
2. Geometric Context Transformer for Streaming 3D Reconstruction
https://arxiv.org/abs/2604.14141 | GitHub
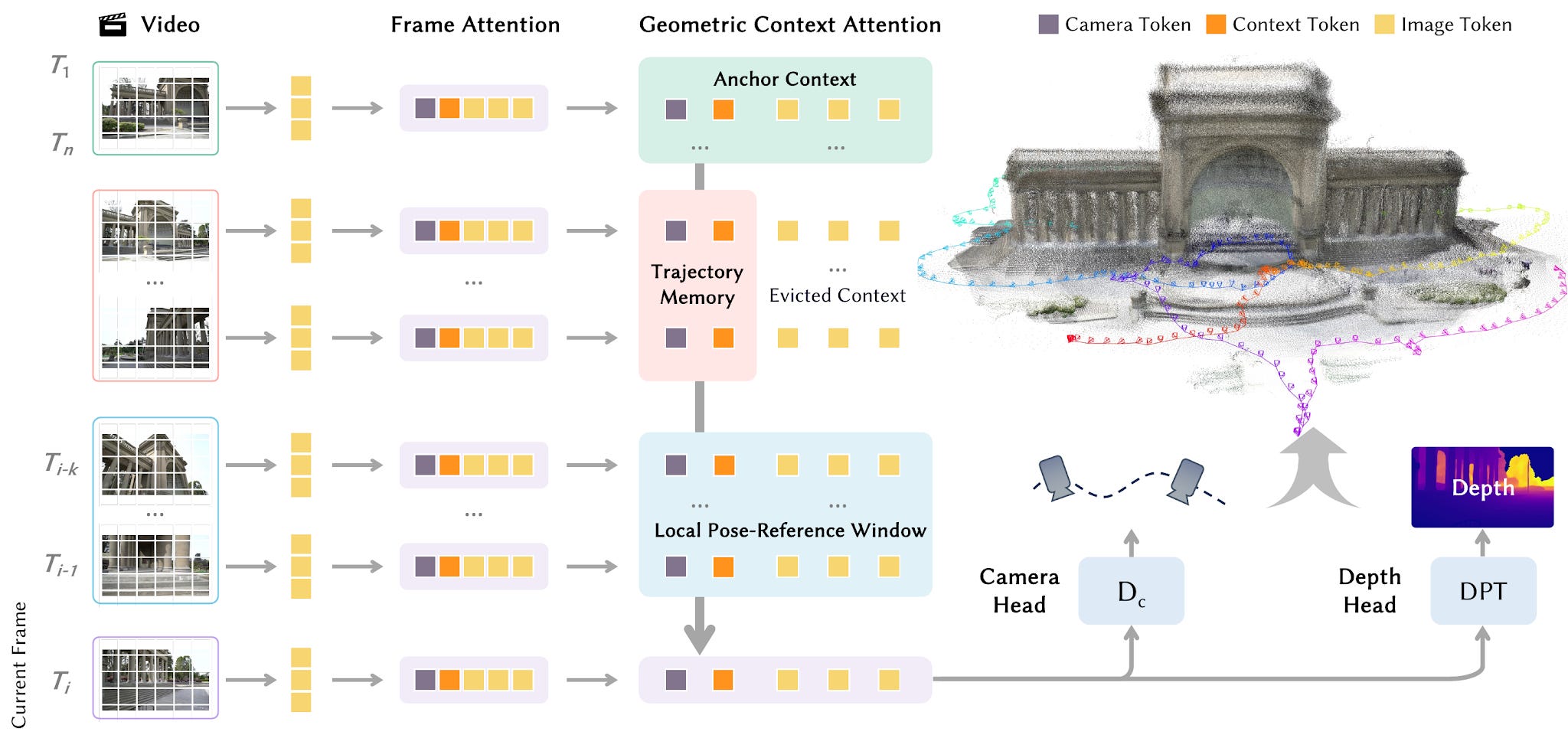
LingBot-Map reconstructs camera poses and point clouds from streaming video. It runs at about 20 FPS, even past 10,000 frames. The attention mechanism uses three tricks. Anchor context grounds the scene. A pose-reference window supplies dense geometric cues. A memory of past trajectories corrects drift. The model is feed-forward, so it needs no per-scene tuning.
3. CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
https://arxiv.org/abs/2605.08735 | GitHub
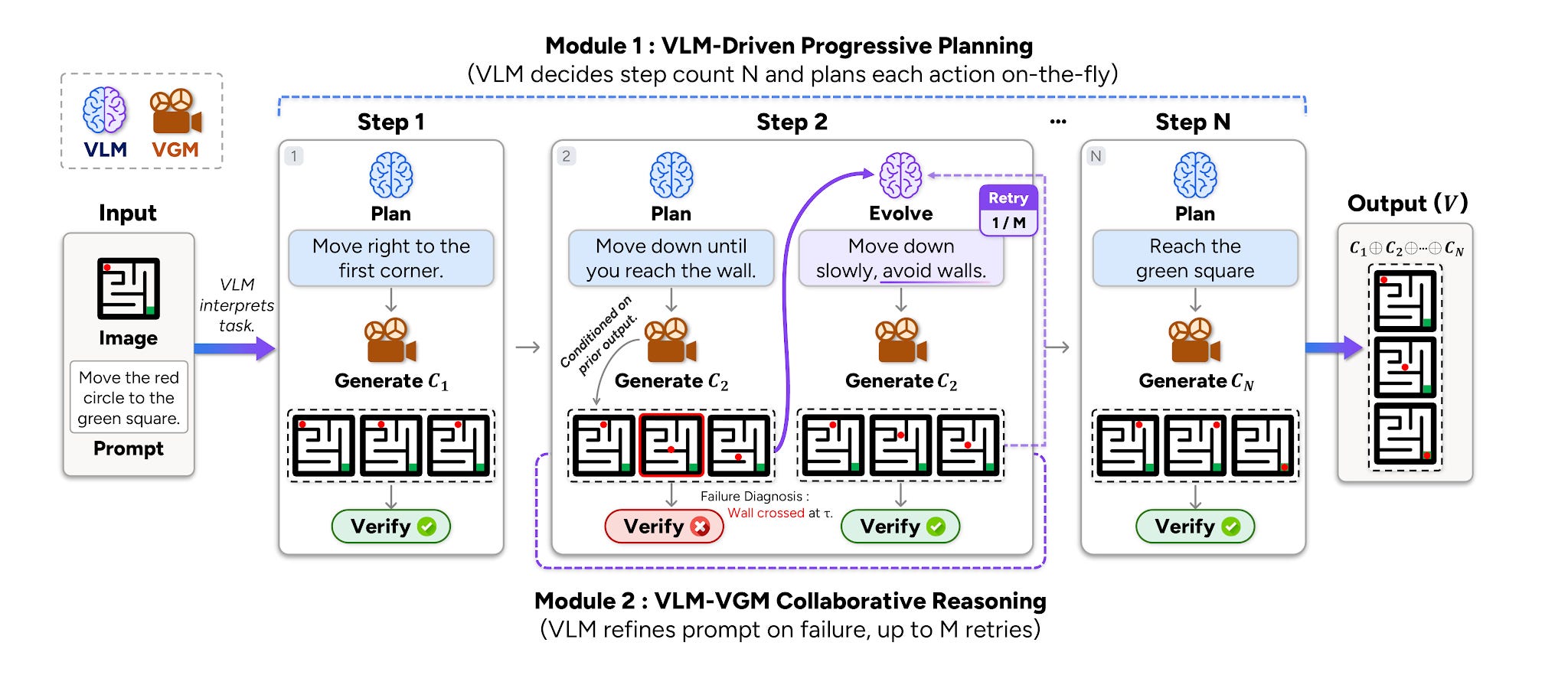
CollabVR pairs a vision-language model with a video generator and makes them check each other at every step. Long video generation tends to drift and compound errors. This closed loop catches the errors early. The model plans actions, inspects each generated clip frame by frame, and sends verification diagnostics back. The system fixes problems at the step level, not the full-sequence level. Progressive Planning adjusts sub-step counts based on task complexity, with the biggest gains on the hardest benchmarks.
4. Sapiens2
https://arxiv.org/abs/2604.21681 | GitHub

Meta released a new family of vision transformers trained on a billion human images. Sapiens2 comes in sizes from 0.4B to 5B parameters. One model handles pose estimation, body-part segmentation, and several other tasks. Against the previous Sapiens generation, the 5B model improves pose accuracy by 4 points and segmentation by 24 points, and cuts surface-normal error by 45.6%. It runs natively at 1K resolution, with bigger variants going up to 4K.
5. Step-Audio-R1.5 Technical Report
https://arxiv.org/abs/2604.25719 | GitHub
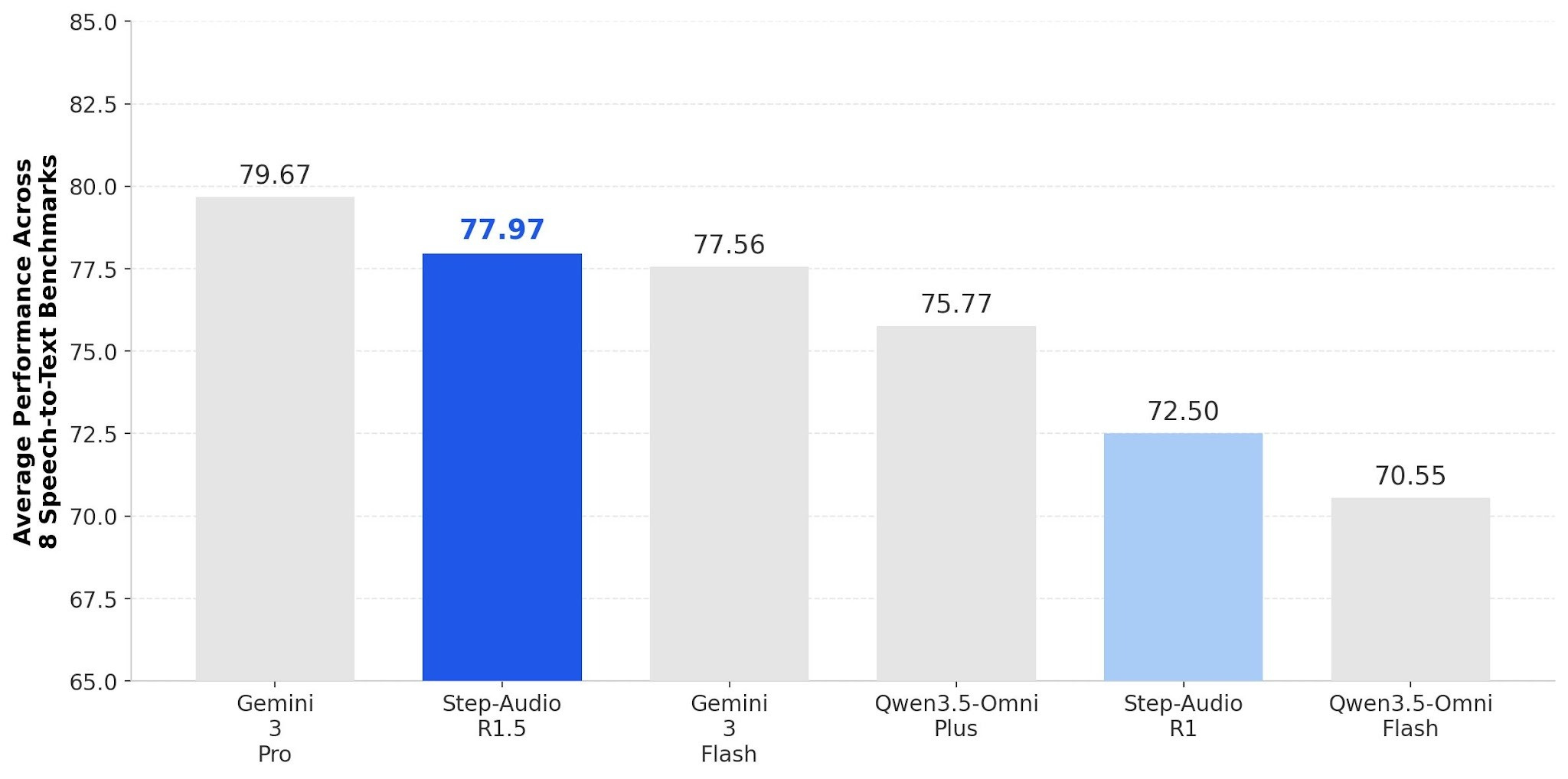
This is chain-of-thought reasoning applied to audio. Step-Audio-R1 used extra compute at inference time to reason through audio tasks. But training it on verifiable rewards hurt conversational quality. R1.5 switches to training from human feedback to balance reasoning with natural dialogue. Problem-solving holds up. Emotional continuity and natural speech rhythm come back in long conversations.
🎥 4 Videos
1. The four strategies of context engineering for reliable AI agents
Every frontier model degrades as input length grows, often well before its stated limit. Marina Wyss (Senior Applied Scientist, Twitch) presents LangChain’s four-part framework for fighting it: Write, Select, Compress, and Isolate. She points to research from Chroma to make it concrete: a model with a 200K-token window can start slipping around 50K, well before its advertised limit. The talk runs about thirty minutes, one strategy per failure mode.
2. Inside Hugging Face’s open agent stack: traces, inference routing, and self-training
Hugging Face now routes inference to the fastest or cheapest provider for each model. Agent sessions upload to Datasets, where the Hub auto-tags them as traces and renders them in a viewer for debugging. Merve Noyan (Hugging Face) demos the highlight: Claude Code fine-tuning an OCR model for French documents from a short prompt. The agent picks a suitable base model, handles the setup, and runs the job with light supervision.
3. HTML over Markdown: how Anthropic’s Claude Code team keeps humans in the loop
When agent plans grow into thousands of lines of markdown, humans stop reading. Thariq Shihipar (Anthropic, Claude Code team) explains why his team switched to rendered HTML. The HTML adds structure, interactivity, and visual layout, which pulls humans back into the loop. His team also builds small HTML interfaces for one-time use, then throws them away. Shihipar calls these throwaway micro-UIs. He also introduces the “compute allocator” framing. When an agent can run for 8 hours, the real job is deciding what’s worth spending compute on.
4. Building production RAG from scratch: BM25, embeddings, rank fusion, and re-ranking
Dave Ebbelaar builds a complete hybrid retrieval pipeline in about an hour and scores it at every stage. The pipeline has four parts. BM25 handles keyword retrieval. OpenAI embeddings catch the semantic matches. Reciprocal Rank Fusion combines the two lists. A Cohere re-ranker scores the top results last. The re-ranker lands the highest score of any stage. Full code is on GitHub.
📰 3 Curated Reads
1. Agent Evaluation: A Detailed Guide

Evaluating agents needs different methods than evaluating LLMs. Cameron R. Wolfe (Staff Research Scientist at Netflix) makes the case for Pass^K over the standard Pass@K. With Pass^K, the agent has to succeed on every attempt, not just one. The numbers are sobering. o4-mini hits only 26% Pass^4 on tau-2-bench Telecom. The post covers numerous benchmarks beyond tau-bench, plus a 7-step roadmap and working code for building custom evals.
2. Interaction Models: A Scalable Approach to Human-AI Collaboration
https://thinkingmachines.ai/blog/interaction-models/
Thinking Machines Lab argues that real-time interaction belongs inside the model architecture, not in external components bolted on top. Their TML-Interaction-Small model has 276B parameters, with 12B active at any time. It processes audio in 200-millisecond chunks for continuous back-and-forth. The result is a turn-taking latency of 0.40 seconds. That edges out the closest competitors near 0.57 seconds, and roughly triples the speed of GPT-realtime-2.0 at 1.18 seconds. A second model runs in the background for slower, deeper reasoning.
3. Recent Research on AI Delegation and Long-Horizon Reliability
Microsoft Research tested what happens when frontier models make chained multi-step changes without human checks. Their DELEGATE-52 benchmark found 19-34% quality loss over 20 delegated iterations. Python workflows held up better, with less than 1% loss on average. That split is the key finding. Code holds its integrity where other formats do not. The authors flag this as a diagnostic stress test, not a capability measure. Production systems succeed precisely because of the verification loops the benchmark strips away.
🛠 2 Tools & Repos
1. fff
https://github.com/dmtrKovalenko/fff
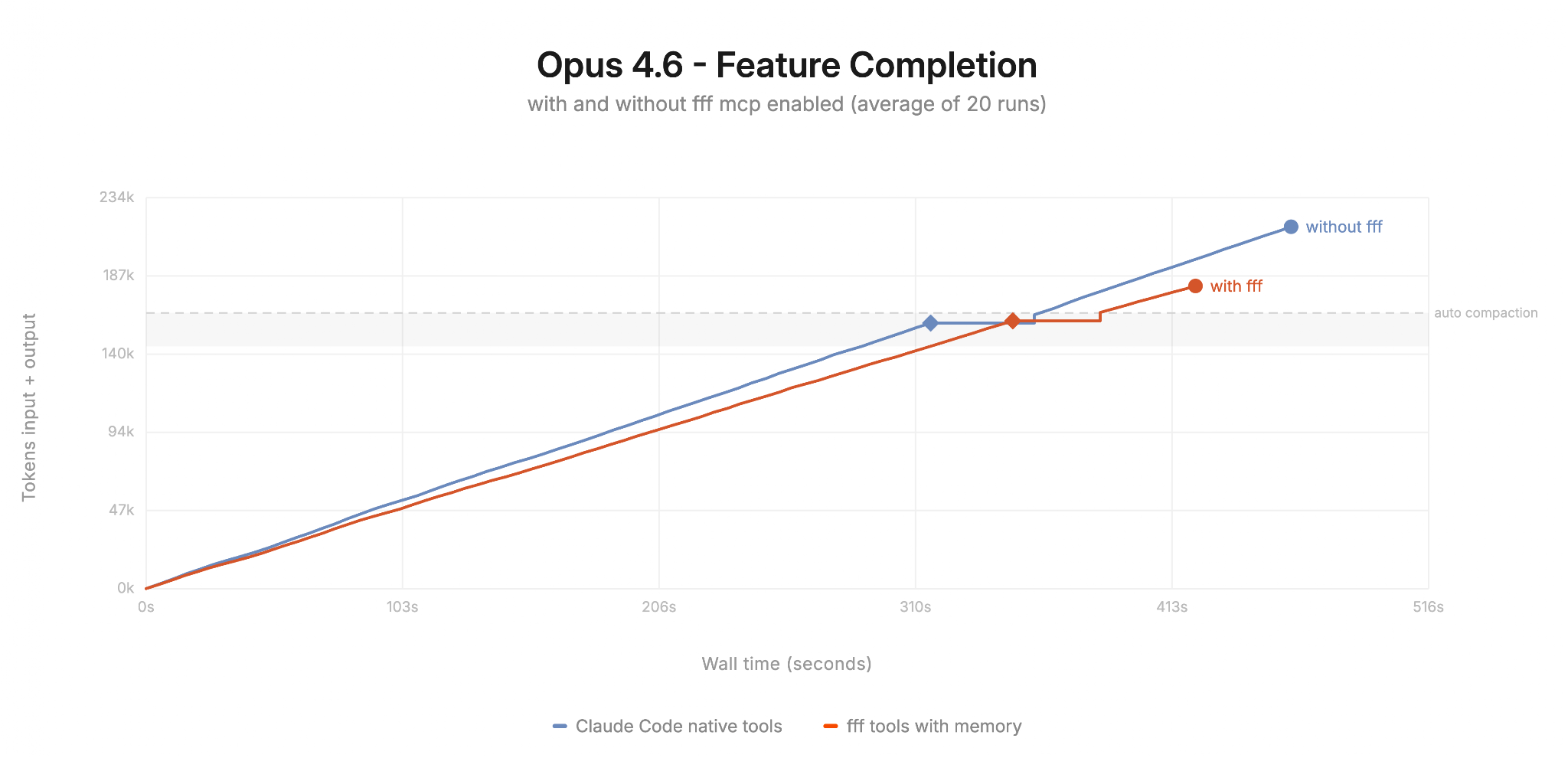
fff is a file search tool for processes that run hundreds of queries per session, like AI agents and editors. Most search tools pay fork overhead on every call, which adds up fast. fff keeps an in-memory index resident instead. On a 500K-file Chromium checkout, that means sub-10ms results. The tool ranks results by how often and how recently you used them. It also handles typos in queries, respects gitignore, and classifies code definitions. Rust powers the core, with bindings for Neovim, C, and Node.js.
2. awesome-design-md
https://github.com/VoltAgent/awesome-design-md

Drop a DESIGN.md file into your project. Your AI coding agent builds pixel-accurate UI without Figma exports or manual design tokens. The repo includes over 70 ready-to-use design specs inspired by brands like Stripe, Apple, Spotify, and Figma. Each spec covers color palettes, typography, component styles, and spacing systems. The agent reads the markdown and generates consistent, branded interfaces.
🎓 1 Pick of the Week
Google Antigravity 2.0 + CLI + SDK
https://antigravity.google/blog/google-io-2026
Google released a full agent ecosystem at I/O 2026. Antigravity 2.0 is a standalone desktop app, not embedded in Chrome or Android. It runs on Gemini 3.5 Flash, which outperforms Gemini 3.1 Pro on Terminal-Bench 2.1 (76.2%). Inside Antigravity, an optimized version runs up to 12x faster than other frontier models (Google’s figure; its general headline number is 4x). The CLI brings agent workflows to the terminal. The SDK lets you build custom agents on the Antigravity harness. Managed agents deploy with a single Gemini API call. Multi-agent orchestration lets Gemini 3.5 Flash run many agents in parallel. The new $100-a-month Google AI Ultra plan gives 5x higher usage limits in Antigravity than the Pro plan.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.