

Google's Generative AI in Search, State of AI 2023, Feedback from LLMs, Code Generation, and more...
Plus doing more ML with less data

Another week has passed, and as usual, the AI juggernaut shows no signs of slowing down. As shared in an earlier edition, today's newsletter will be packed with curated resources and a cheeky illustration of an AI concept. A new deep dive will be out next week. We have a lot to cover, so let's get started!
The Art of Learning with Less:
In most real-world scenarios, having a large, labeled dataset to train a model is a luxury. Even when we have a model performing well in production, new challenges can arise, such as when the system encounters data it has never seen before. In both cases—whether you're lacking enough labeled data to start with or facing unseen data categories later on—data-efficient methods like zero-shot, one-shot, and few-shot learning can be invaluable.
These techniques allow models to make meaningful predictions with next to no labeled data. As the saying goes, "When life gives you lemons, make lemonade." To understand these, let's consider a toy scenario.

Imagine that three painters step up to draw the Mona Lisa. Let’s also assume that these artists have never seen or heard of the original since Instagram and social media weren't invented then (again, toy scenario). All three painters are identical in ability. They went to the same snooty art school, and so forth.
Now, we'll impose different constraints on each painter. Let's see how they fare in recreating the Mona Lisa, given these restrictions.
Zero-shot Learning
The first painter has a blindfold on and can't see the original Mona Lisa. He has to paint his version without any reference. Without ever seeing the Mona Lisa, he relies on whispered descriptions from the crowd—hints about her mysterious smile, the serene background, or her modest attire. The artist then uses this auxiliary information to paint a picture in the "Stick-ism" style since that's what he's been most recently trained on.
The result? An imaginative rendition, capturing the essence, if not the erm, exact details.

This is how zero-shot learning works. It enables models to recognize objects from classes it hasn't seen before by leveraging auxiliary information like textual descriptions or attribute vectors that describe the general characteristics of a class. It's a great way to handle data scarcity, especially when getting labeled examples is next to impossible.
It should be noted that while zero-shot learning offers some advantages in data-scarce scenarios, it generally does not perform as well as methods trained directly on the target classes. Additionally, the quality of the results depends on the quality of the auxiliary information available to the model.
Applications of zero-shot learning include diagnosing "new" diseases from X-rays where the model has not seen examples before and in autonomous vehicles where the car might see something entirely new on the road that it hasn't seen before.
One-shot Learning
The second painter isn't blindfolded, but, and this is a big but, is allowed only one look at the Mona Lisa. He, too, is blindfolded once he has a fleeting glance at the original. Thus, he must quickly internalize her features, the folds of her dress, and the play of light and shadow. Then, relying on that brief look, he must start painting.
In this case, the painter went for the Chiaroscuro look. Light on the details. Dark on the technique.

One-shot learning functions this way, absorbing as much as it can from a limited dataset and trying its best to generalize from it. Specifically, given a single example of a class/category in training, the model must learn to predict a new instance during test time. While one-shot learning also excels in low-data environments, it doesn't perform as well as methods with more labeled data.
Face verification is a popular application for one-shot learning since you might not get many pictures of the same person on a security camera. In this case, Siamese networks are trained to differentiate between pairs of input samples, enabling them to compare new faces effectively based on a single example.
Few-shot Learning
Our final painter picked the longest straw and thus could look at the Mona Lisa a few times. After every few brushstrokes, he pauses, looks again, and refines. Each look offers more clarity, depth, and context. This method allows for more accuracy with every added glance. Thus, he was able to bring in color, textural differences, and a more erm, lifelike appearance in his recreation.
He chose a "Simpsonian" style for his version and rendered a study in ochre. Legend has it that he was told the Smithsonian had great works of art. Somehow, the name morphed into Simpsonian through the grapevine, redirecting him to the artistic city of Springfield.

Few-shot learning is like the middle sibling of one-shot and traditional machine learning. It asks for a few more examples to learn from, striking a balance between data efficiency and performance. This is effective in data-scarce scenarios where zero-shot or one-shot approaches will yield suboptimal results. The primary trade-off in few-shot learning, compared to one-shot and zero-shot learning, is that it requires slightly more data but often delivers improved performance. However, unlike models that learn from many labeled examples, few-shot learning's results are still inferior. There are many applications of few-shot learning, like learning to label a new picture of an animal in the wild given only a few labeled images of it.
In summary, these methods help in scenarios where acquiring labeled data is challenging or impractical. Each of these has its unique trade-offs in terms of data requirements and performance. While one-shot and few-shot learning are somewhat similar, zero-shot learning stands apart due to its ability to handle completely unseen categories. Their applications span across healthcare, agriculture, and other fields.
Resources To Consider:
Find of The Week
Mindstream is a free daily newsletter that helps you stay current on Artificial Intelligence without the information overload. With a well-curated selection of AI news, daily polls, intriguing AI art, and much more, you can expect a comprehensive yet digestible overview of what's happening in the AI space delivered right to your inbox. Once you subscribe, you'll also gain access to an invaluable library of AI resources.
Zero-Shot Generation of NeRFs from Text
Paper: https://arxiv.org/abs/2310.17075
Hyperfields uses a dynamic hypernetwork to learn the mapping from text tokens to a NeRF space. It additionally leverages NeRF distillation to enable a single network to fit over a hundred unique scenes. The approach is 5-10x faster than prior work but faces some challenges when it comes to fine details.

CodeFusion: A Diffusion Model for Code Generation
Paper: https://arxiv.org/abs/2310.17680
CodeFusion from Microsoft aims to bridge the gap between natural language and code. Using a blend of an encoder-decoder architecture and diffusion, CodeFusion outshines existing models by generating more syntactically accurate and diverse programs. By iteratively denoising a complete program, it overcomes the limitations of auto-regressive models, marking a significant stride in the realm of natural language to code generation.
Tuna: Instruction Tuning using Feedback from Large Language Models
Paper: https://arxiv.org/abs/2310.13385
Code: https://github.com/microsoft/LMOps
Tuna elevates instruction tuning by utilizing feedback from advanced Large Language Models to refine open-source models like LLaMA. Through probabilistic and contextual ranking, it intelligently improves response quality, surpassing strong baselines across various benchmarks. This innovation paves the way for better alignment of model behaviors with human preferences.
Flash-Decoding for Long Context Inference
Link: https://pytorch.org/blog/flash-decoding/
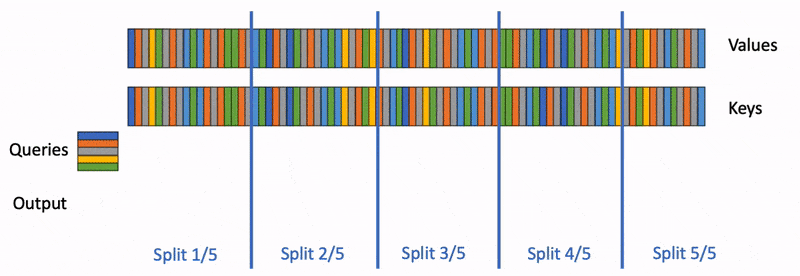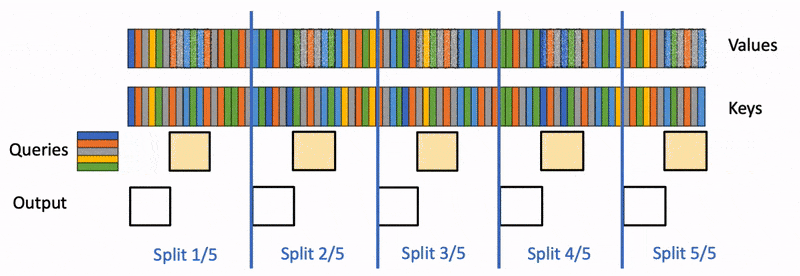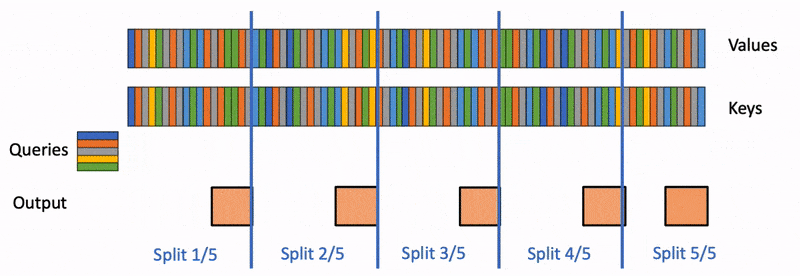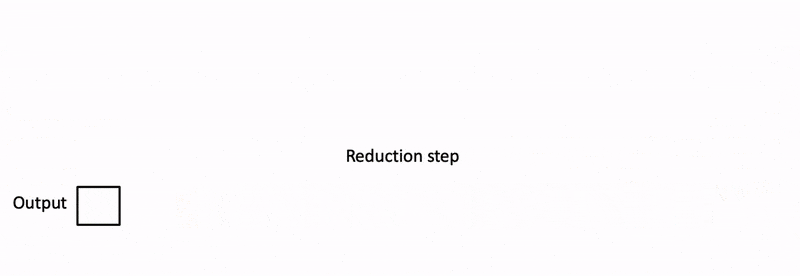
Flash-decoding significantly accelerates attention during inference in Large Language Models, enabling up to 8x faster generation for very long sequences. By loading keys and values in parallel swiftly, then separately rescaling and combining the results, Flash-decoding maintains correct attention outputs. This method is particularly beneficial for LLMs dealing with long contexts, offering a more efficient way to handle attention and inference, which is crucial for various emerging use cases of LLMs like summarization, question answering, and code auto-completion
Google Introduces Generative AI in Search
Blog: https://blog.google/products/search/google-search-generative-ai-october-update/
Google is leveraging generative AI inside Search to "spark" creativity. There are times when we are looking for a specific image. However, finding such an image is easier said than done. In those scenarios, SGE, Google's Gen-AI-powered search, can help you brainstorm ideas for this and more. Check out the blog for more details.
State of AI 2023
Link: https://www.stateof.ai/
The State of AI Report 2023 unveils key AI developments across research, industry, politics, and safety, with a spotlight on GPT-4's supremacy, the rise in compute resources, and a booming investment in generative AI startups. Amid growing global discourse on AI safety and challenges in model evaluation, the report underscores the critical juncture of AI's evolving landscape. This is a must-read and a fantastic piece of work.
DreamCraft3D: Hierarchical 3D Generation
Project Page (Paper, Code, and Demo): https://mrtornado24.github.io/DreamCraft3D/
DreamCraft3D employs a 2D reference image for generating coherent 3D objects, addressing geometry and texture fidelity issues. Using unique distillation techniques and a personalized diffusion model called Dreambooth, it achieves a beneficial optimization between geometry and texture, enhancing 3D content generation.