

Google's Viral Paper Banana, How to Systemize Claude Code, and Stanford on Agents & RAG - 📚 The Tokenizer Edition #17
This week's most valuable AI resources

Hey there! This week brought Google’s Paper Banana into the spotlight with its interactive approach to understanding research, a comprehensive system for making Claude Code actually work at scale, and Stanford’s practical take on building agents with RAG. Beyond the headline picks, CodeOCR’s 8x code compression through visual representation and DFlash beating EAGLE-3 by 2.5x suggest we’re seeing real efficiency breakthroughs across the board.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
I’m teaching ML & Generative AI System Design on Feb 28th / March 1st with Packt.
We’ll cover AI systems that use RAG and traditional ML design principles for building solid AI products: making systems reliable, measuring what matters, and designing architectures that work in production.
Through live discussions, guided exercises, and team-based design sprints, you’ll practice solving system-level AI problems and walk away with frameworks you can apply immediately at work.

Questions? Drop a comment or DM me.
TL;DR
What caught my attention this week:
📄 Papers: Code-as-image achieving 8x compression, speculative decoding beating EAGLE-3 by 2.5x, video models learning from YouTube demonstrations, and self-optimizing RL systems
🎥 Videos: Systematic Claude Code workflows from Anthropic users, Stanford on agents and RAG patterns, visual MoE explanations, and vector indexing methods
📰 Reads: Why creativity can’t be interpolated, 10x cheaper tokens through prompt caching, and 12x faster MoE training with Unsloth
🛠 Tools: Language extraction for multilingual text and comprehensive LLM evaluation frameworks
🎓 Learning: Google’s viral Paper Banana for interactive research paper exploration
📄 5 Papers
Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
https://arxiv.org/abs/2602.08439 | GitHub
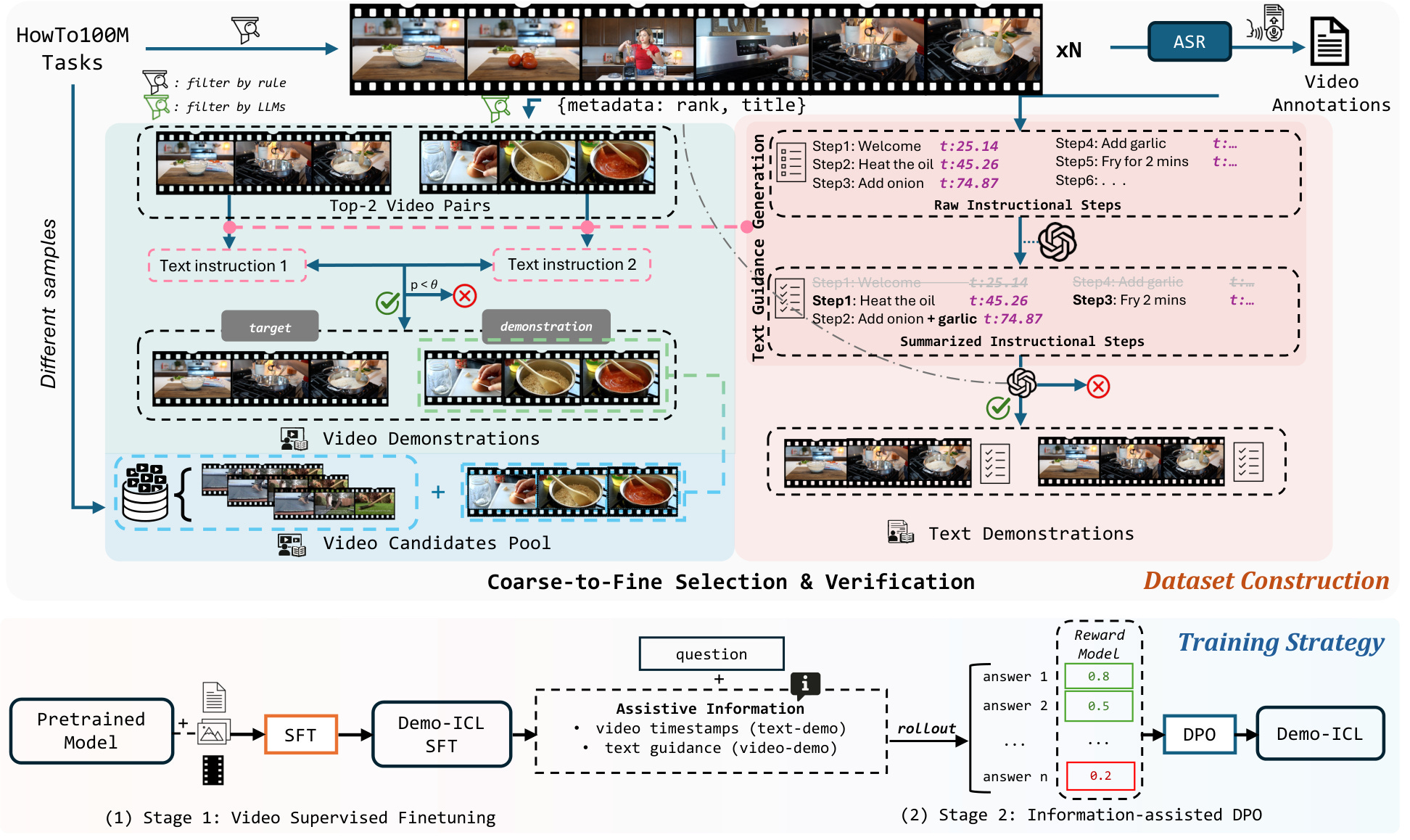
Most video benchmarks test static knowledge rather than whether models can actually learn from demonstrations. Demo-ICL tackles this directly with a benchmark built from 1200 instructional YouTube videos. The system provides models with text or video demonstrations, then asks them to answer questions about target videos by applying what they learned from the examples. The two-stage training approach combines video-supervised fine-tuning with information-assisted preference optimization, improving how models extract and apply procedural knowledge from demonstrations.
DFlash: Block Diffusion for Flash Speculative Decoding
https://arxiv.org/abs/2602.06036 | GitHub
Autoregressive models decode sequentially, creating a latency bottleneck that speculative decoding helps address. DFlash uses a lightweight block diffusion model that generates draft tokens in parallel rather than one at a time. By conditioning the draft model on context features from the target LLM, it maintains high acceptance rates while generating entire blocks simultaneously. The system achieves over 6x lossless acceleration across various tasks, delivering up to 2.5x higher speedup than EAGLE-3.
CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
https://arxiv.org/abs/2602.01785 | GitHub
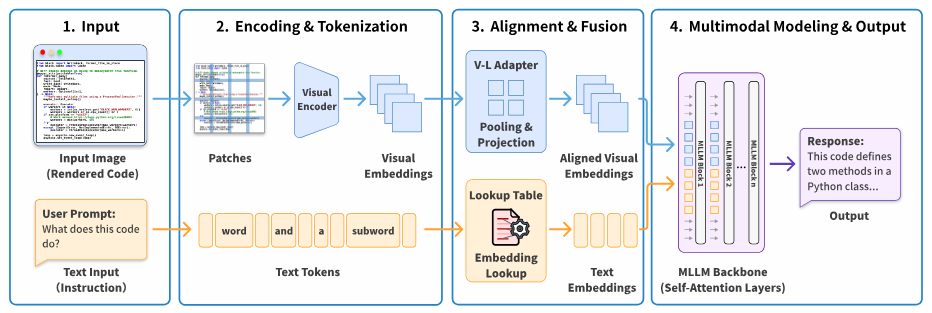
Text-based code processing creates a linear scaling problem as codebases grow. CodeOCR explores representing code as rendered images instead, taking advantage of visual compression capabilities that text lacks. The research shows vision-language models can understand code images at up to 8x compression while maintaining performance. Tasks like clone detection actually improve slightly under compression, and syntax highlighting boosts code completion performance at 4x compression. The approach suggests image-based code representation could fundamentally change how we handle large-scale code understanding.
RLAnything: Forge Environment, Policy, and Reward Model in Completely Dynamic RL System
https://arxiv.org/abs/2602.02488 | GitHub
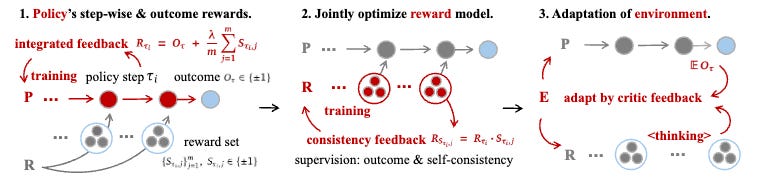
Traditional reinforcement learning keeps environments, policies, and reward models separate. RLAnything makes all three components adapt together through closed-loop optimization. The policy trains on combined step-wise and outcome signals, while the reward model jointly optimizes through consistency feedback. Environment tasks automatically adjust difficulty based on critic feedback from both the policy and reward model. The system delivers substantial gains: 9.1% improvement on OSWorld for Qwen3-VL-8B-Thinking, and 18.7% and 11.9% boosts on AlfWorld and LiveBench for Qwen2.5-7B-Instruct.
Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
https://arxiv.org/abs/2602.07026
Despite progress in multimodal contrastive learning, a persistent geometric anomaly remains: embeddings of different modalities expressing identical semantics occupy systematically offset regions. This modality gap creates alignment challenges that existing approaches handle inefficiently. The research introduces Fixed-frame Modality Gap Theory, which decomposes the gap into stable biases and anisotropic residuals. ReAlign aligns text representations into image distribution space using statistics from unpaired data through anchor, trace, and centroid alignment. Building on this, ReVision enables MLLMs to learn visual representation distribution from unpaired text before visual instruction tuning, reducing dependence on expensive image-text pairs.
🎥 4 Videos
How to Make Claude Code Better Every Time You Use It (Full System)
Stop fighting with Claude Code and start building systematic workflows that compound over time. This comprehensive guide covers setting up persistent context files that Claude references across all sessions, structuring your codebase so Claude understands project architecture from the start, and creating reusable prompt patterns that extract better reasoning. You’ll learn how to build a project-specific knowledge base, manage multiple Claude sessions working on different parts of your code simultaneously without conflicts, and structure requests to get maintainable output instead of throwaway code. The system turns Claude Code from a one-off tool into a genuine development partner.
MoE, Visually Explained
Mixture-of-Experts architectures power many frontier models but remain conceptually opaque. This visual breakdown makes the core mechanics tangible: how router networks decide which experts process each token, why sparse activation improves efficiency without sacrificing performance, and what trade-offs exist between expert count and model capacity. The explanations focus on intuition over equations, making MoE accessible without dumbing down the actual complexity involved.
What is Indexing? Indexing Methods for Vector Retrieval
Vector databases require efficient retrieval mechanisms as collections scale. This overview covers indexing approaches from flat search through hierarchical navigable small worlds (HNSW) and inverted file indexes (IVF). You’ll understand when approximate nearest neighbor search makes sense versus exact matching, how different index types trade off speed against accuracy, and which methods work best for specific retrieval patterns.
Agents, Prompts, and RAG
Stanford’s practical breakdown of building reliable agents using retrieval-augmented generation cuts through the hype. The discussion examines when to use agents versus simpler prompt chains, how to structure RAG systems that agents can query effectively, and debugging approaches when agentic systems fail. The focus stays on production considerations: handling edge cases, managing token budgets, and building systems that degrade gracefully rather than failing catastrophically. Essential viewing for anyone moving beyond toy agent demos to production deployments.
📰 3 Curated Reads
Why Creativity Cannot Be Interpolated
https://archive.mlst.ai/paper/why-creativity-cannot-be-interpolated/
This exploration challenges the assumption that creative breakthroughs emerge from incremental improvements. The argument centers on fundamental limitations of interpolation-based learning: models trained to predict the next token in existing distributions struggle to generate genuinely novel ideas that exist outside their training manifold. The piece examines what this means for AI’s creative capabilities and why certain types of innovation may require fundamentally different approaches than current architectures support.
Prompt caching: 10x cheaper LLM tokens, but how?
https://ngrok.com/blog/prompt-caching/
Prompt caching stores processed prefixes so repeated context doesn’t get recomputed on every request. This technical breakdown explains how caching works under the hood: which parts of prompts get cached, how providers handle cache invalidation, and what billing implications exist. The post provides concrete strategies for structuring prompts to maximize cache hits, quantifies actual cost savings across different use patterns, and identifies scenarios where caching delivers minimal benefit.
Fine-tune MoE Models 12x Faster with Unsloth
https://unsloth.ai/docs/new/faster-moe
Training Mixture-of-Experts models typically requires massive compute due to their architecture. Unsloth achieves up to 12x speedups over Transformers v4 (and roughly 2x over the already-optimized Transformers v5) through custom Triton grouped-GEMM kernels and a Split LoRA approach that also cuts VRAM usage by over 35%. The documentation covers implementation details: how to integrate Unsloth into existing training pipelines, which MoE models are supported (Qwen3, DeepSeek R1/V3, GLM), and how the optimizations maintain full accuracy with zero approximation. Particularly valuable for teams fine-tuning large MoE models on consumer hardware.
🛠 2 Tools & Repos
Langextract
https://github.com/google/langextract
Extracting structured information from unstructured text typically requires custom pipelines for every new domain. Langextract is a Gemini-powered Python library that handles this through LLM-based extraction with precise source grounding, mapping every extracted entity back to its exact location in the source text. Define your extraction schema through a few examples and the tool adapts without fine-tuning, handling long documents through optimized chunking and parallel processing. Particularly useful for domains like clinical notes, radiology reports, and research literature where traceability between extracted data and source material is critical.
Deepeval
https://github.com/confident-ai/deepeval
LLM evaluation needs systematic frameworks rather than ad-hoc testing. Deepeval provides metrics for measuring answer relevancy, factual consistency, and hallucination rates across different model outputs. The framework supports both rule-based and model-based evaluation, enables A/B testing across prompt variations, and tracks performance degradation over time. Particularly useful for teams building production LLM applications that need reliable quality metrics.
🎓 1 Pick of the Week
Paper Banana
https://dwzhu-pku.github.io/PaperBanana/
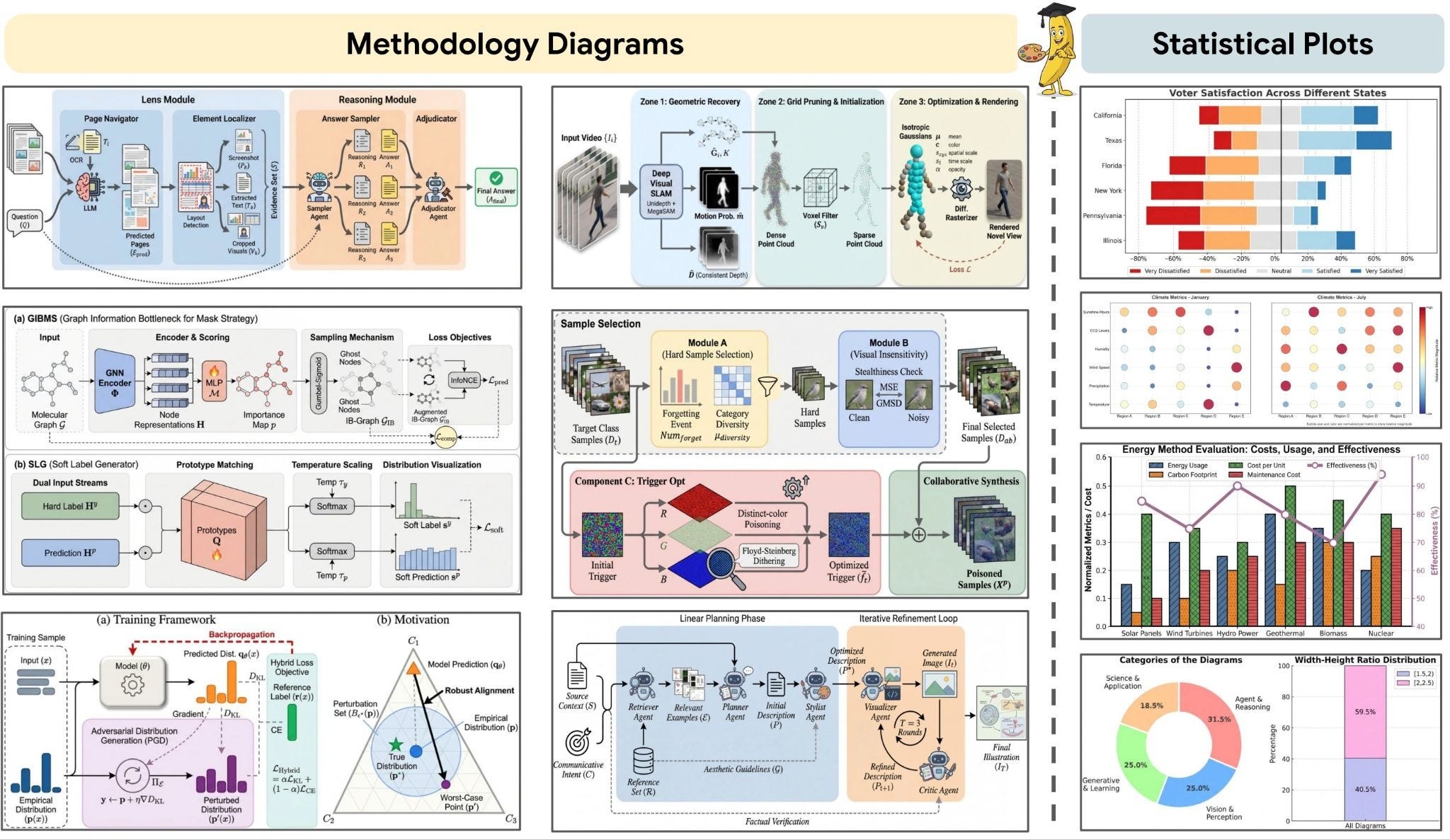
Google’s Paper Banana went viral for good reason: it fundamentally changes how researchers produce academic illustrations. Instead of spending hours manually crafting methodology diagrams and statistical plots, Paper Banana orchestrates five specialized AI agents (Retriever, Planner, Stylist, Visualizer, and Critic) to generate publication-ready visuals from paper text. The system handles everything from architecture diagrams to data visualizations, with the Critic agent running multiple refinement rounds to catch factual errors and visual glitches. In blind human evaluation, its outputs achieved a 72.7% win rate against baseline AI models. For researchers drowning in illustration work or trying to produce consistent, high-quality figures across papers, this approach delivers production value that manual tools struggle to match. The viral response reflects how badly the research community needed a better way to handle the illustration burden.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.