

Google's Zero-Shot Video Breakthrough and Cursor's Internal Build Playbook
This week's most valuable AI resources

Hey there! This week brought a breakthrough in how we think about scaling computer-use agents. Reliability comes from smarter selection, not just better models. We also got an open-source multi-agent system that actually works without days of configuration, and video models are doing things they were never trained for. Let
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
• 📄 Papers: Agent scaling methods that actually improve reliability, production-ready multi-agent frameworks, and multimodal models with real-world speech capabilities
• 🎥 Videos: Practical insights from Richard Sutton on AI fundamentals, hands-on prototyping techniques, and why evals matter for product managers
• 📰 Reads: Building modular architectures that scale, understanding LoRA’s real tradeoffs, and why we keep underestimating exponential progress
• 🛠 Tools: Interactive galleries of AI-generated images and complete virtual simulation environments
• 🎓 Learning: Cursor’s internal playbook for building with AI assistance
Preorder my first book — AI for the Rest of Us — today!
If you’ve enjoyed my work, you’ll find incredible value in this book. I promise.
Early preorders make an enormous difference in determining how many bookstores will carry the book, how widely it will be seen, and whether publishers believe there’s demand for accessible AI education.

📄 5 Papers
The Unreasonable Effectiveness of Scaling Agents for Computer Use
https://arxiv.org/abs/2510.02250 | GitHub
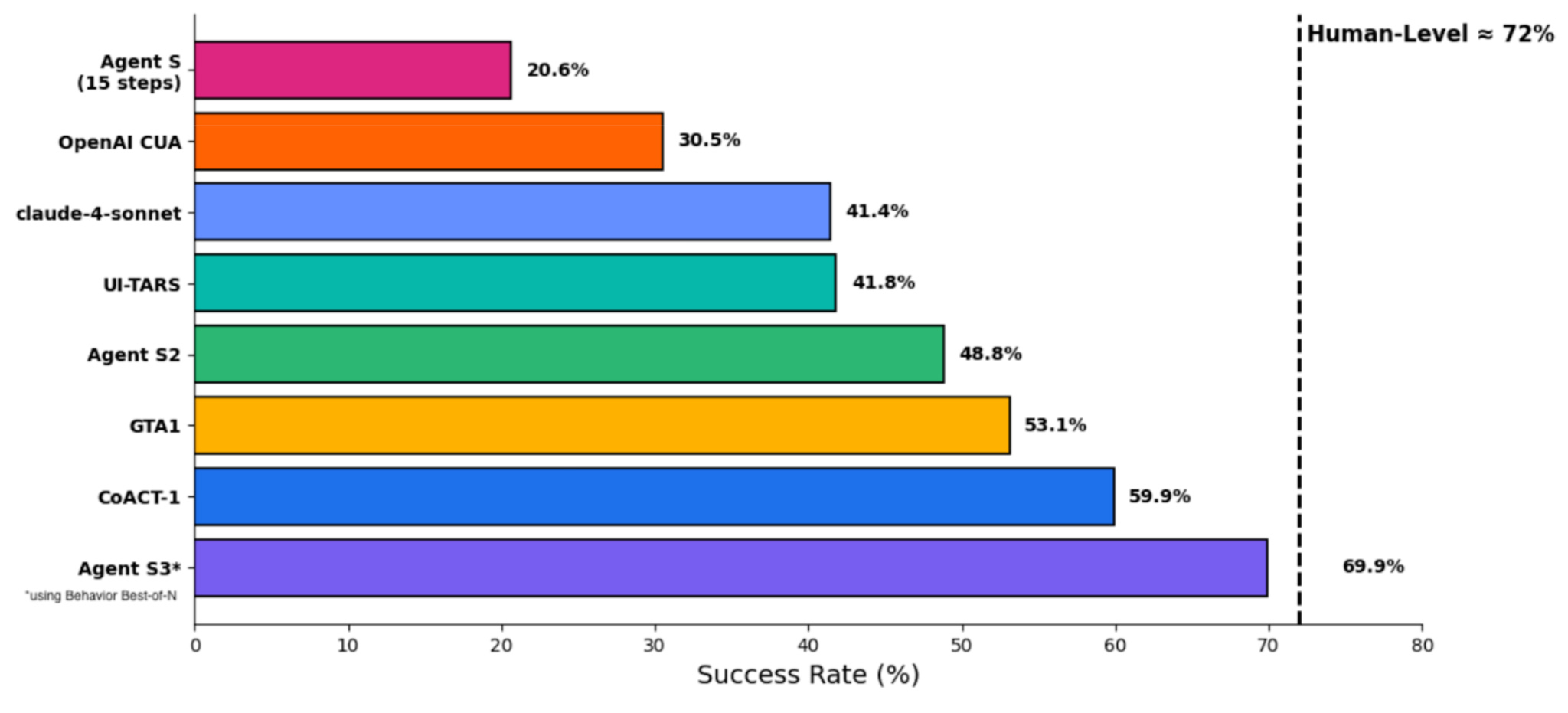
Here’s what changed the game for computer-use agents: generate multiple attempts, then systematically pick the best one. This Behavior Best-of-N method hit 69.9% on OSWorld, nearly matching human performance at 72%. The insight is about structured selection using behavior narratives that describe what the agent actually did, not just scaling compute blindly. This matters because agents that work brilliantly in demos but fail unpredictably in production have been the core blocker for deployment. The approach works across Windows and Android too, which suggests the principle generalizes.
JoyAgent-JDGenie: Technical Report on the GAIA
https://arxiv.org/abs/2510.00510 | GitHub
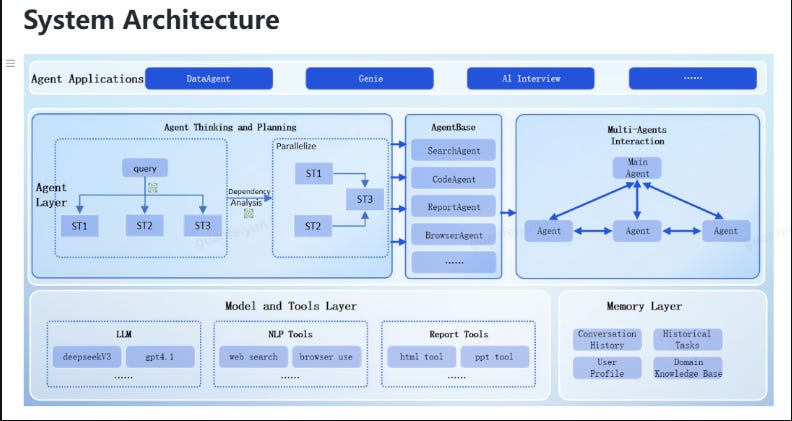
Most agent frameworks hand you building blocks and wish you luck figuring out the architecture. JDGenie gives you the complete system that scores 75.15% on GAIA and runs locally without cloud dependencies. The architecture integrates collective planning with critic voting, hierarchical memory from working to procedural layers, and tools that parse 17 file formats while searching across Google, Bing, DuckDuckGo, GitHub, ArXiv, and Wikipedia. This is the difference between a research prototype and something you can deploy: it works out of the box. If you’ve been waiting for production-ready agents that handle real document processing, code execution, and web search tasks, this delivers.
Qwen3-Omni Technical Report
https://arxiv.org/abs/2509.17765 | GitHub
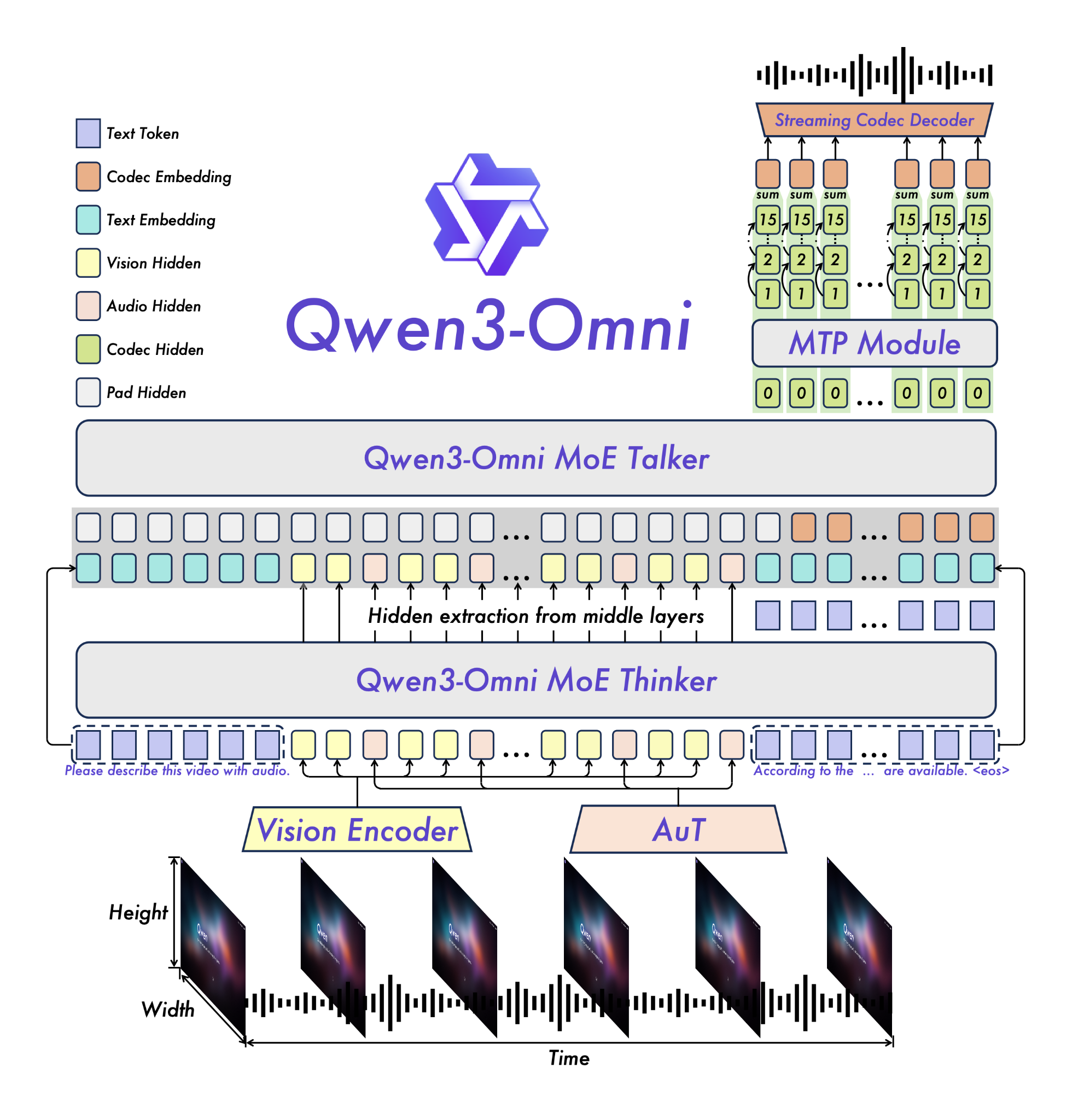
Multimodal models usually trade off performance—great at text but mediocre at audio, or vice versa. Qwen3-Omni’s 30B parameters maintain state-of-the-art across text, images, audio, and video simultaneously. It topped 32 out of 36 audio benchmarks, beating Gemini-2.5-Pro and GPT-4o-Transcribe. The practical advantage shows up in real-time speech: 234ms first-packet latency in cold-start settings, which makes conversational applications actually feel responsive. Works across 19 languages for speech understanding and generates speech in 10. They also released a captioning model for audio that keeps hallucinations low. Released under Apache 2.0, so this level of multimodal capability is now accessible for commercial use without licensing headaches.
Video models are zero-shot learners and reasoners
https://arxiv.org/abs/2509.20328
Google’s Veo 3 exhibits capabilities it was never explicitly trained for: segmenting objects, detecting edges, editing images, understanding physics, recognizing object affordances, simulating tool use, solving mazes. These emerge from the same formula that gave LLMs general-purpose capabilities: large generative models trained on web-scale data. The research suggests video models might be following the same trajectory toward unified vision understanding that LLMs took for language. We’re seeing early forms of visual reasoning already. This pattern—general capabilities emerging from scale rather than task-specific training—keeps showing up across modalities.
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
https://arxiv.org/abs/2510.02283 | GitHub
Long video generation typically degrades as errors compound over time. Self-Forcing++ extends generation to 4+ minutes by having teacher models guide student generation through sampled segments from self-generated videos, scaling 20x beyond what the teacher can produce. The key is exploiting teacher model knowledge without requiring supervision from long-video teachers or retraining on long video datasets. This maintains consistency while avoiding the over-exposure and error accumulation you usually see. You get videos up to 99.9% of the base model’s maximum position embedding span working reliably, without recomputing overlapping frames like previous approaches.
🎥 4 Videos
Richard Sutton - the Bitter Lesson
The father of reinforcement learning discusses his “Bitter Lesson” essay with Dwarkesh Patel. The core argument: AI progress comes from leveraging computation, not encoding human knowledge. Methods that scale with compute consistently beat clever domain expertise, across decades and domains. Sutton explains why researchers keep rediscovering this pattern despite wanting to believe architectural innovation matters more. Watch this if you’re debating whether to bet on scaling laws or novel architectures. His perspective is grounded in watching these cycles repeat for 40 years.
The secret to better AI prototypes
Ravi Mehta and Claire Vo walk through workflows for rapid prototyping with AI tools. The approach prioritizes getting to working prototypes quickly, then refining based on what actually works rather than planning every detail upfront. The video covers common traps that waste time on approaches that won’t scale—useful when you’re building AI features and need to move from concept to demo without getting stuck planning instead of building.
Why AI evals are the hottest new skill for PMs
Hamel and Shreya explain why evaluation frameworks have become essential for product managers working with AI. Traditional product metrics don’t capture whether AI systems are reliable or improving, which makes shipping with confidence nearly impossible. The conversation covers designing meaningful evaluations, picking metrics that actually matter, and using evaluations throughout the development process. As AI features move from experimental to core product experiences, understanding evaluation is what separates PMs who ship confidently from those who guess and hope.
AI Engineer Paris 2025 (Day 2)
Full day of presentations from the AI Engineer conference covering production systems, deployment strategies, and lessons from companies shipping AI products. Day 2 focuses on technical infrastructure, evaluation approaches, and operational challenges that surface when moving from prototype to production. The value here is hearing from engineers running AI systems at scale, not just showing demos. You get the perspective of people dealing with reliability, cost, and performance issues in real deployments.
📰 3 Curated Reads
Modular Manifolds
https://thinkingmachines.ai/blog/modular-manifolds/

How to structure AI systems for flexibility without sacrificing performance. This piece covers practical decisions in system design: when splitting components makes sense, how to define clean interfaces, and where modularity helps versus where it adds unnecessary complexity. The insights come from actual implementation experience, building systems that need to evolve over time. Valuable if you’re architecting AI systems and want to avoid the common trap of either over-engineering modularity or creating monoliths that become unmaintainable.
LoRA without Regret
https://thinkingmachines.ai/blog/lora/
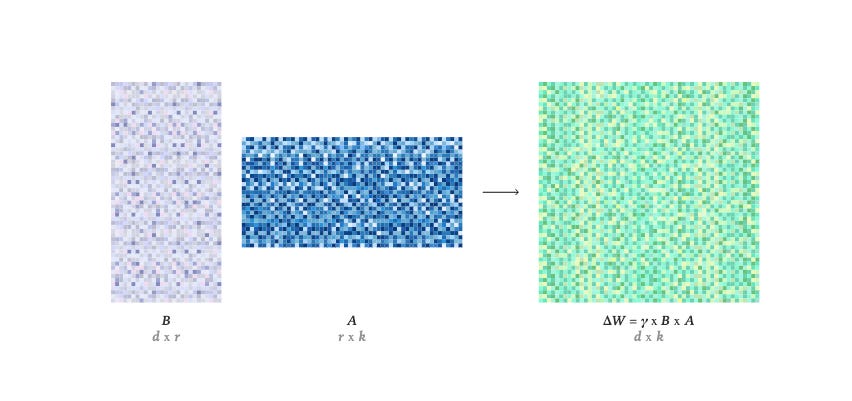
Low-Rank Adaptation has become standard for fine-tuning, but most guides skip the important questions: when does it work well, where does it struggle, and how do you diagnose problems when your fine-tuning isn’t performing? This piece covers the practical tradeoffs with guidance on hyperparameter selection, rank choice, and combining LoRA with other techniques. Read this if you’re fine-tuning models in production and need to understand what you’re actually trading off rather than just following tutorials.
Failing to Understand the Exponential Again
https://www.julian.ac/blog/2025/09/27/failing-to-understand-the-exponential-again/
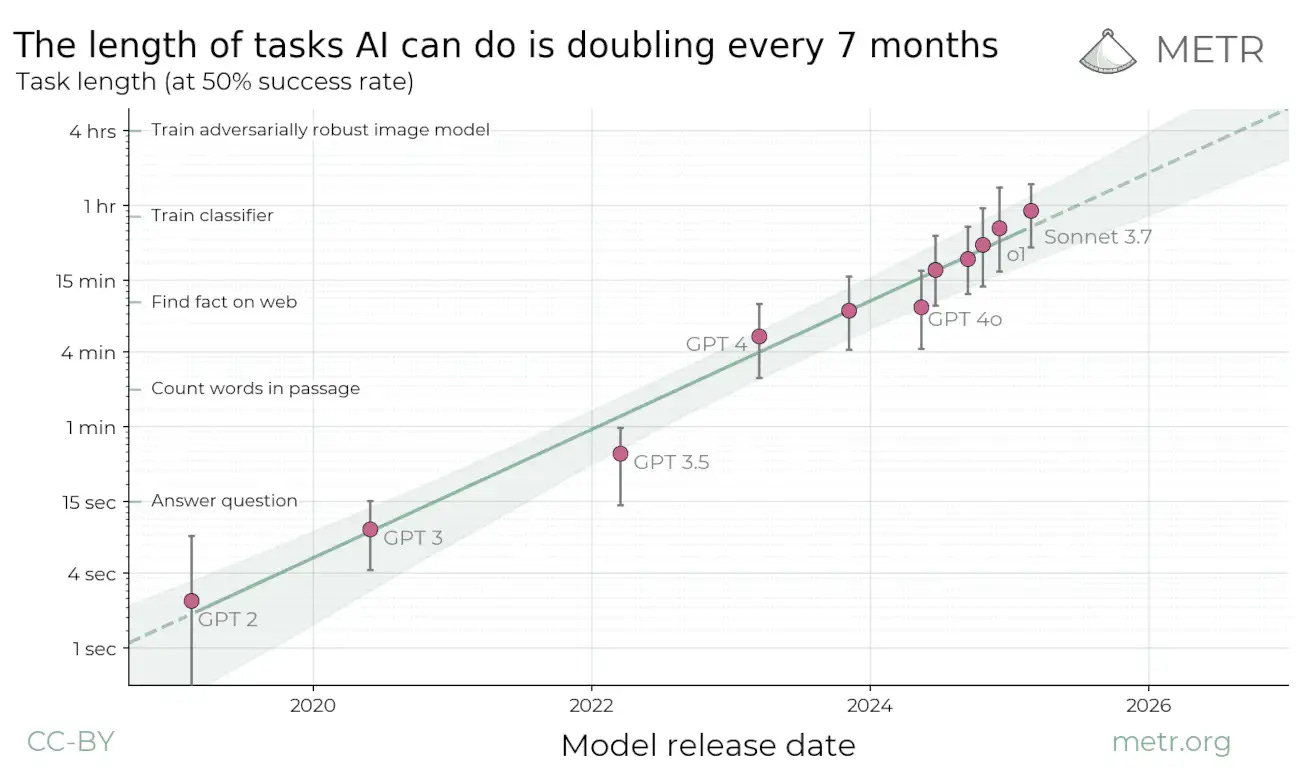
We consistently underestimate exponential progress in AI despite having data showing clear exponential trends. Julian Schrittwieser examines the cognitive biases that cause linear thinking and provides frameworks for thinking about AI progress that account for acceleration rather than extrapolating current capabilities. This matters if you’re planning product roadmaps or trying to anticipate where AI capabilities will be in 6-12 months. Linear projections will leave you unprepared.
🛠 2 Tools & Repos
Tiny Worlds (Genie Reimplemented)
https://github.com/AlmondGod/tinyworlds
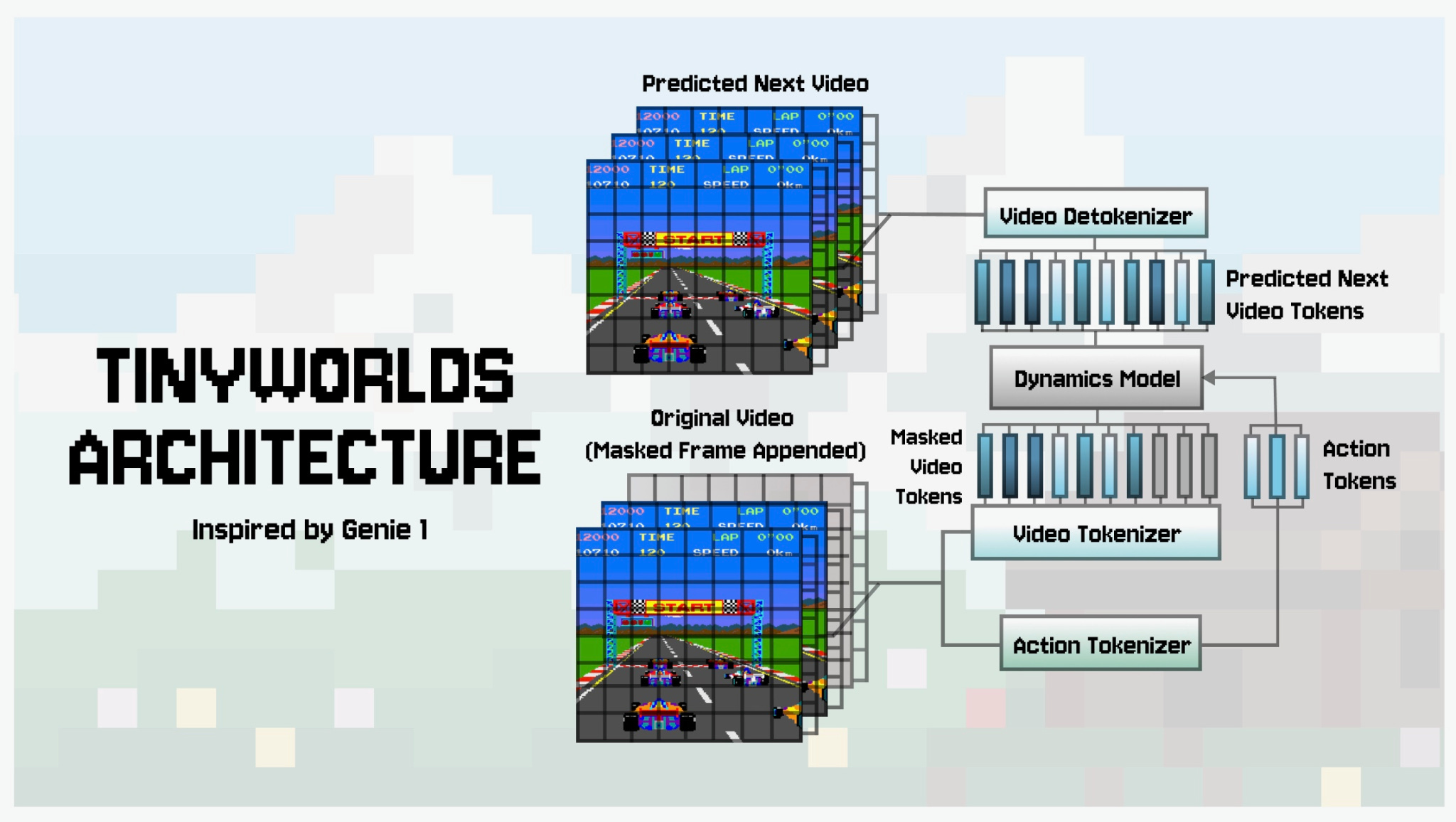
A framework for building miniature simulation environments where AI agents can learn and be evaluated. You create custom worlds with their own physics, rules, and objectives without rebuilding infrastructure from scratch. The modular design makes prototyping new environments practical. This fills the gap between toy problems that are too simple and full robotics simulators that are too complex—useful when you need controlled environments to test agent capabilities without the overhead of complex simulation systems.
Awesome Nano Banana Images
https://github.com/PicoTrex/Awesome-Nano-Banana-images/blob/main/README_en.md
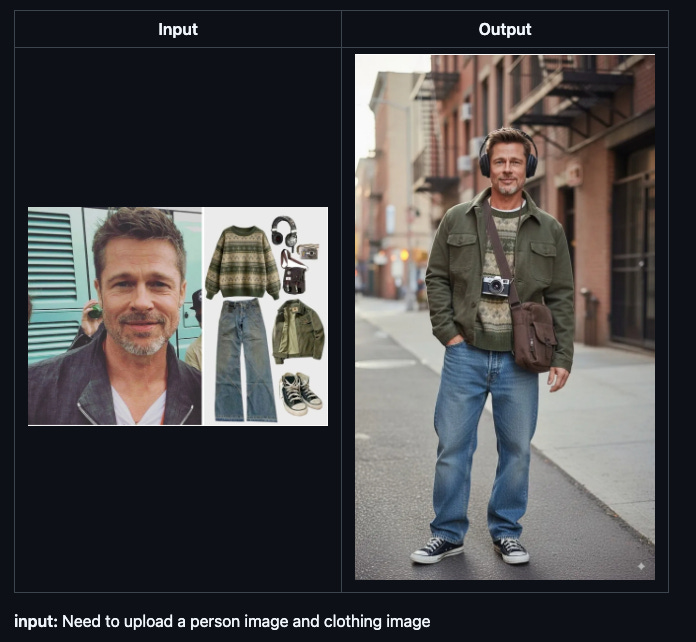
A curated collection showcasing outputs from Google’s Nano Banana image model, now revealed as Gemini 2.5 Flash Image. The repository demonstrates capabilities across diverse prompts with particular focus on character consistency across multiple generations. This serves as both inspiration for prompting strategies and a practical reference for understanding what current image models can actually achieve. The value is seeing real examples across varied use cases rather than the cherry-picked shots you typically see in marketing materials.
🎓 1 Pick of the Week
Building with Cursor
https://www.notion.so/cursorai/Building-with-Cursor-public-273da74ef0458051bf22e86a1a0a5c7d
Cursor’s internal documentation on how their GTM and non-engineering hires actually build with AI assistance. You’ll learn when to use different Cursor features, how to structure context for better results, and debugging strategies when AI-generated code has issues. Most AI coding guides focus on demos and best-case scenarios. This shows what daily development actually looks like when you’re using AI assistance seriously, from a team that lives in this workflow.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.