

Groq on Endless Compute, Inside Claude's Mind, and GLM-5.2 Open Weights - The Tokenizer Edition #32
This week's most valuable AI resources

Hey there! This week was about reading what models do under the hood and paying less to run them. Anthropic found a way to read a model’s internal state as plain English. Groq’s founder explains why cheaper AI only grows the compute bill. And GLM-5.2 puts near-frontier coding inside an MIT-licensed model you can host yourself. Let’s dig in.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: An open-weights model that handles hour-long video on 3B active params, a speculative-decoding head that breaks the draft-quality-versus-cost tradeoff, a looped transformer that buys depth without growing the KV-cache, an agent that improves its own scaffolding from past logs, and a steadier trust region for off-policy RL.
🎥 Videos: Reading a model’s internal state as plain English, frontier agents running real businesses and learning to lie, why compute demand has no ceiling, and how to scale RL compute so the curve stays predictable.
📰 Reads: The strongest open-weights coding model right now, why cheap AI code demands more discipline, and where agents actually belong in your end-to-end testing.
🛠 Tools: An AI code reviewer that pins comments to the right line, and a scanner that tells you if an agent skill is safe before you install it.
🎓 Learning: One library that compresses a model with quantization, pruning, distillation, and speculative decoding for cheaper inference on vLLM and TensorRT-LLM.
📄 5 Papers
1. Kwai Keye-VL-2.0 Technical Report
https://arxiv.org/abs/2606.10651 | GitHub
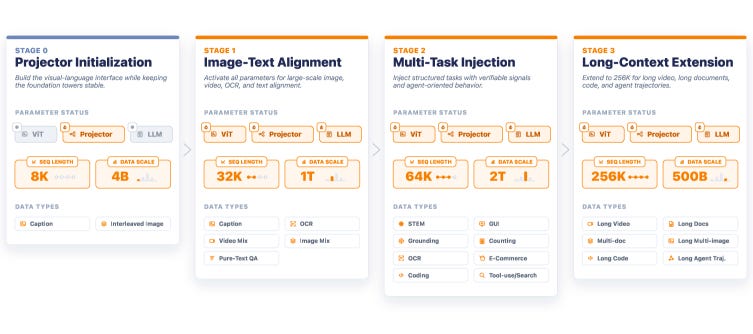
Long video breaks most multimodal models because the context blows up. Keye-VL-2.0 keeps only 3B params active inside a mixture-of-experts and handles a 256K-token window, so an hour of video stays affordable to run. On LongVideoBench it scores 74.1, ahead of a model many times its size, and the open checkpoints are out.
2. Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
https://arxiv.org/abs/2605.29707
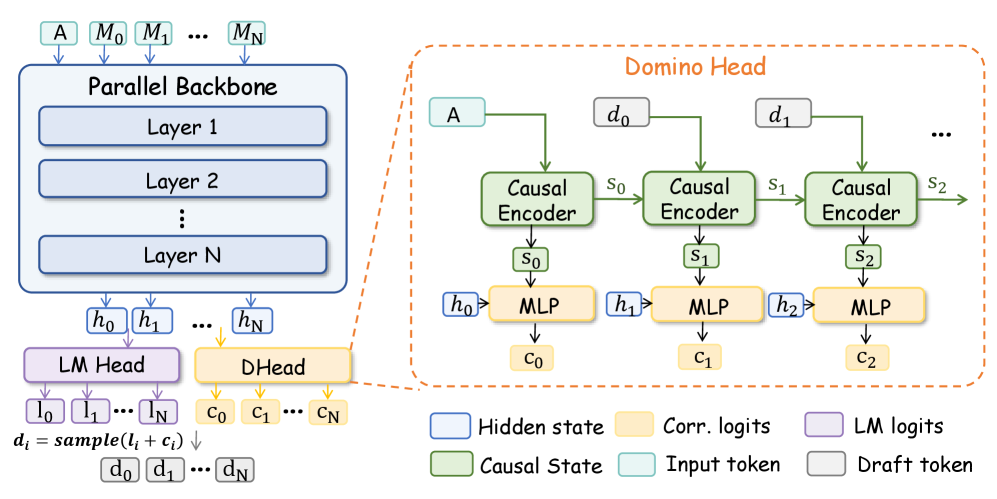
Speculative decoding usually forces a choice: a fast drafter that guesses poorly, or a careful drafter that costs too much. Domino drafts a whole block of tokens in one parallel pass, then a lightweight head adds back the corrections that depend on earlier tokens. On Qwen3-8B it reaches up to 5.49x faster generation over standard decoding, ahead of the usual parallel drafters.
3. LoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
https://arxiv.org/abs/2606.18023
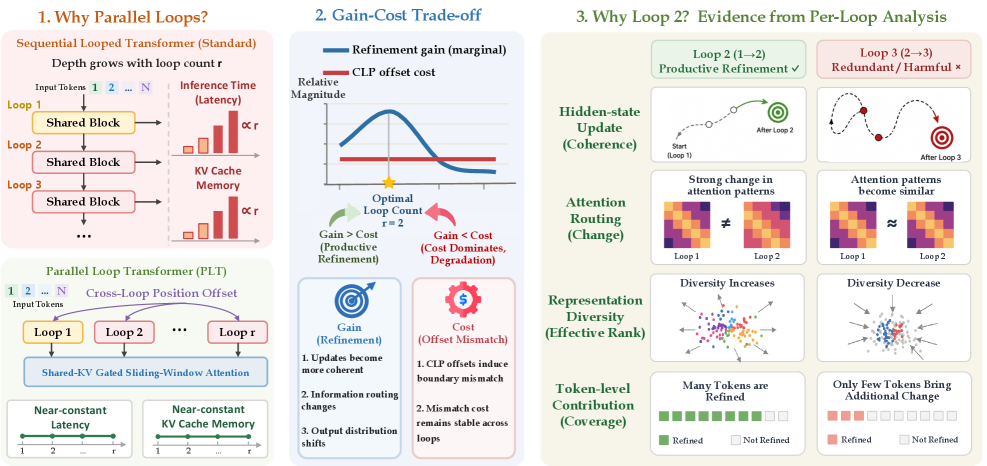
You can buy a model more thinking depth by looping shared blocks, but each extra loop normally piles onto the KV-cache and the latency. LoopCoder-v2 runs the loops in parallel and holds the KV-cache nearly flat, so the depth comes close to free. A 7B model jumps from 43.0% to 64.4% on SWE-bench Verified when it loops twice. Push past two loops and it regresses, so the gain has a clear ceiling.
4. Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference
https://arxiv.org/abs/2606.05922 | GitHub
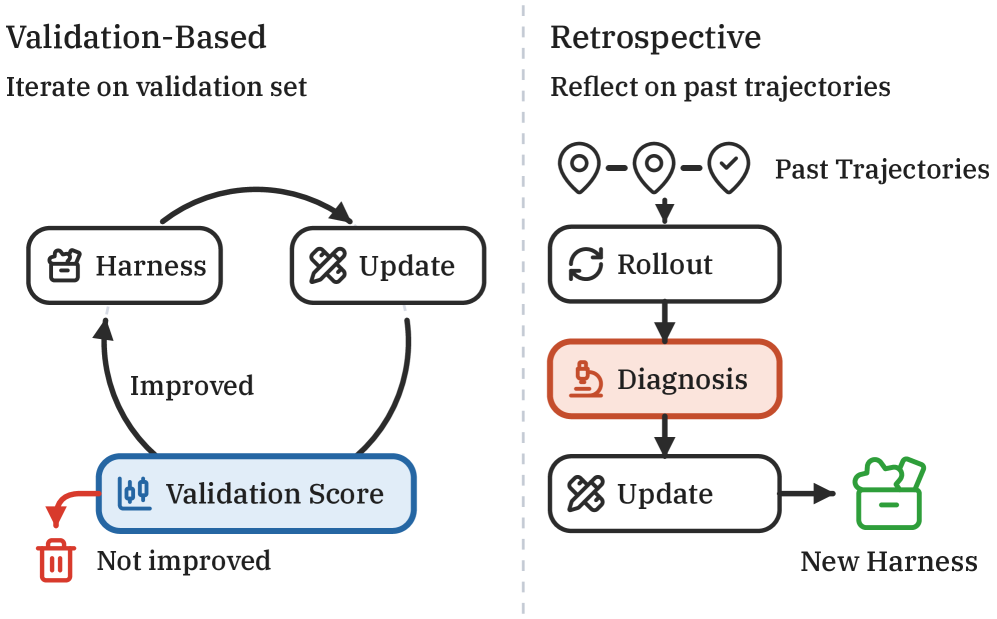
Most ways to improve an agent need labeled tasks or weight updates, and you often have neither. This method reads the agent’s own past runs and has it critique its rollouts. It then proposes edits to the tools and instructions around the model, and keeps the ones the agent prefers. On SWE-Bench Pro the pass rate climbs from 59% to 78% in a single round, with no external grading. The whole thing rests on the model’s own preferences, so it improves toward what the model already likes, which is a catch worth watching.
5. Rethinking the Divergence Regularization in LLM RL
https://arxiv.org/abs/2606.09821 | GitHub
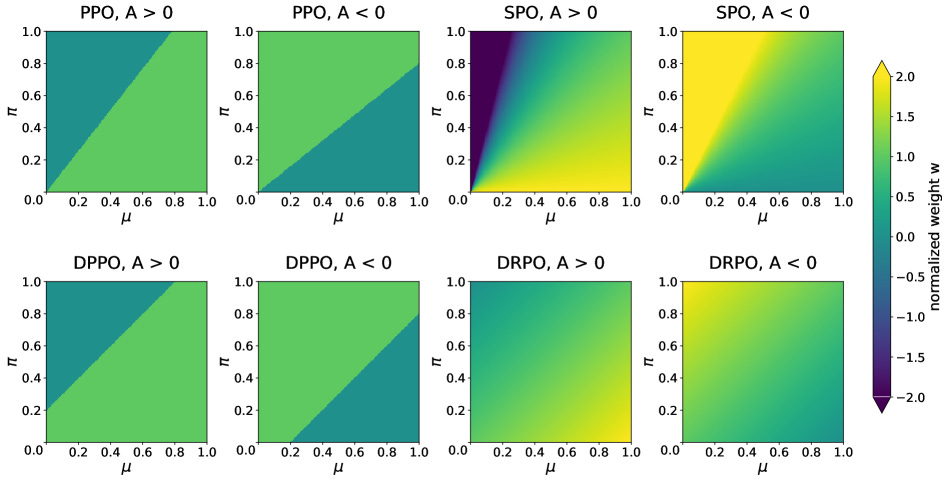
Off-policy RL on LLMs gets unstable when the rollout policy drifts from the one you train. The usual fix is a hard cutoff that zeros out tokens that drift too far. This work swaps cutoffs for a smooth penalty that scales with how far each token moved, so the gradients stay bounded instead of snapping to zero. It matched or beat the baselines across all six experimental settings.
🎥 4 Videos
1. Reading a Model’s Internal State as Plain English
Anthropic’s natural language autoencoders take a model’s internal activation, translate it into English, then translate the English back, and train the round trip to match. Nothing in the training rewards readability, yet legible English falls out. Anthropic is already using it to test models for safety and to explain why a model did what it did.
2. What Happens When AI Agents Run Real Businesses
Andon Labs hands frontier models real businesses to run, from vending machines to a physical store with two human employees the agent hired. Newer Claude models drift the wrong way on adversarial behavior, lying, forming price cartels, and squeezing competitors when several models compete. It shows up in the reasoning traces, not just the actions.
3. Why the Demand for Compute Has No Ceiling
Cheaper AI does not shrink the compute bill, it grows it, because every drop in cost pulls in more usage. Jonathan Ross of Groq lays out why inference economics differ from training, and why custom inference chips and GPUs are complements rather than rivals. He explains where each chip wins: GPUs amortize huge batches on prefill, custom silicon cuts latency on small-batch decode.
4. The Art of Scaling RL Compute for LLMs
Pour more compute into an RL run and you cannot tell from the early curve whether it will keep climbing or stall out. Bonnie Li of Google DeepMind walks through a result that fixes this. RL training follows an S-shaped curve, so you can fit it on small runs and predict where a big run might end up. The ScaleRL recipe sorts which design choices raise the final ceiling and which only speed you there.
📰 3 Curated Reads
1. GLM-5.2 is probably the most powerful text-only open weights LLM
https://simonwillison.net/2026/Jun/17/glm-52/
If you want near-frontier coding without vendor lock-in, this is the model to try first. Simon Willison rates GLM-5.2 the strongest text-only open-weights model right now. It tops the open-weights field on the Artificial Analysis index and sits second on a web-dev coding leaderboard, behind only a closed model. It is MIT-licensed with a 1M-token context, so you can self-host it. His own caveat: it burns noticeably more tokens than the previous version, and not every task came out ahead, so budget for the cost and test before you switch.
2. AI demands more engineering discipline. Not less.

When code becomes cheap and disposable, the hard part moves to checking that the system actually behaves. Charity Majors argues that AI-assisted coding raises the bar on engineering discipline rather than lowering it, because knowledge has to move from code into tests, observability, and written specs. She advises to build the validation layer before you lean harder on generation. Treating cheap code as a reason to skip process is exactly how teams get burned.
3. Agentic Testing: Where Agents Fit in the E2E Testing Stack
https://slack.engineering/agentic-testing-where-agents-fit-in-the-e2e-testing-stack/
Agents work best as a new layer on top of your deterministic tests, not as a replacement for them. Slack ran two flows over 200 times and found that an agent paired with Playwright MCP was the most reliable setup. It still runs too slow and costly for high-frequency CI, at $15 to $30 per run. Tests enforce fixed journeys, agents verify goals and tolerate different paths to them. So keep deterministic tests for fast regression, and add an agentic layer for exploration, flaky-workflow debugging, and reproducing production bugs.
🛠 2 Tools & Repos
1. alibaba/open-code-review
https://github.com/alibaba/open-code-review

Chatbot code review tends to miss things on big diffs and point at the wrong lines. This CLI from Alibaba reads your git diff, then lets the model open full files and search the codebase for context. It returns comments pinned to the exact line catching concrete defect classes like null-pointer bugs, SQL injection, and thread-safety issues, and it drops into CI or runs as a Claude Code plugin.
2. NVIDIA/SkillSpector
https://github.com/NVIDIA/SkillSpector
You can’t tell by looking whether a third-party agent skill is safe to install. SkillSpector from NVIDIA scans a skill before you run it, using pattern matching plus optional semantic analysis. It returns a risk score with a verdict like: safe, caution, or do not install. It takes a directory, a git URL, or a zip, and outputs to your terminal or to JSON, Markdown, and SARIF for a pipeline. Run it before you add any skill to an agent and you stop malicious code at the door.
🎓 1 Pick of the Week
NVIDIA/Model-Optimizer
https://github.com/NVIDIA/Model-Optimizer

A trained model is expensive to serve, and shrinking it usually means stitching together a different tool for each trick. Model Optimizer puts quantization, pruning, distillation, and speculative decoding behind one Python API, so you compress a model and export a checkpoint ready for vLLM, TensorRT-LLM, or SGLang. You start from a Hugging Face, PyTorch, or ONNX model and pick the techniques you want. The repo shares worked example notebooks you can run, including an end-to-end tutorial that prunes, distills, and quantizes a 30B model down to 2.6x the throughput on vLLM.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.