

How to Deconstruct Machine Learning Papers to Implement them:
Reading ML papers is really important for your growth as a practitioner. In fact, I’ve made a video explaining how you can read these…

Reading ML papers is really important for your growth as a practitioner. In fact, I’ve made a video explaining how you can read these papers effectively. But, what’s really important is knowing how to map these papers into code when you need to. This may be either because you’re assigned a paper to implement as homework, or maybe you need it for a work project, or maybe you’re really excited about learning to implement it.
Whatever the reason, here is an effective strategy that works for me time and time again when I need to implement papers.
Step 1: Progressively summarize the paper
In order to implement a paper and validate its claims, you’ll need to know the TL;DR of the paper. Specifically, read the paper and progressively summarize it in your own words. At the end of this step, you want to have the following information at your fingertips:
What are the main claims — “We achieve X results”, “We improve on Y previous work”, etc.
What are the new proposals — “We propose ABC architecture”, “We use C instead of D”, and so on
What are the hyperparameters — “We use the Adam Optimizer with a learning rate of …”, “We use a batch size..”, etc.
What are the hardware requirements — “We use 1000 GPUs and 500 TPUs” 😂
What are the target tasks and datasets — “We evaluate our method on DEF dataset” and so on
Identifying these first will help you build a mental landscape of what to expect, what’s different from things you’ve previously implemented, and help you decide if you can re-implement the paper as is. Sometimes, the size of the model you need to implement, or the hardware requirements might prohibit you from replicating the work. In those cases, you’d need to scale down the method or abandon the pursuit altogether if you don’t have the compute needed to run the algorithm.
This step will help you avoid a lot of wasted effort and mentally prepares you for the actual coding part!
Step 2: Identify the core algorithm(s) in the paper
The next step is to find what you need to implement in the paper. One of the many challenges new practitioners face when reading these papers is that there is a lot of math not directly related to what they need in order to implement the paper.
This can both confuse and discourage practitioners from trying to implement these papers. Most of this math is usually something that serves as a theoretical proof of the method, or some adjacent theory needed to really understand the foundations of the paper.
Give permission to yourself to skip these equations! Please. It will save you a lot of pain.
Here’s what you need — The flowchart or the main method which most papers have. Let’s take an example. The image below is from the paper that proposed the Adam Optimizer (You don’t need to implement this algorithm these days).
This table in the paper summarizes everything you need to implement Adam on your own:

There’s a LOT of math in the paper other than this and if you get sucked into reading and understanding that (not a bad thing but unnecessary to implement), you’ll never implement it.
If the paper you’re reading doesn’t have this, try to identify the core equations and write down a flowchart like this on your own. Usually, you can find the “main” equations in the methods section of the paper. Extracting this from the paper will reduce the back and forth you need to implement it. This is also good practice to build your equation-to-code muscles for the future.
Step 3: Audit and Simplify
While it might be tempting to jump into coding right away, avoid that temptation, and do this next. Go line by line through the flowchart you’ve created or identified and audit all the things you need to implement. Auditing here means finding out if you need to write something in code yourself, or if can borrow an existing implementation.
Most of the code you need to write is usually already available as functions from your favorite libraries (Pytorch, Tensorflow, etc.) or boils down to high school math. Seriously.
Let’s take the example from above. Here’s what the equations look like without the flowchart:
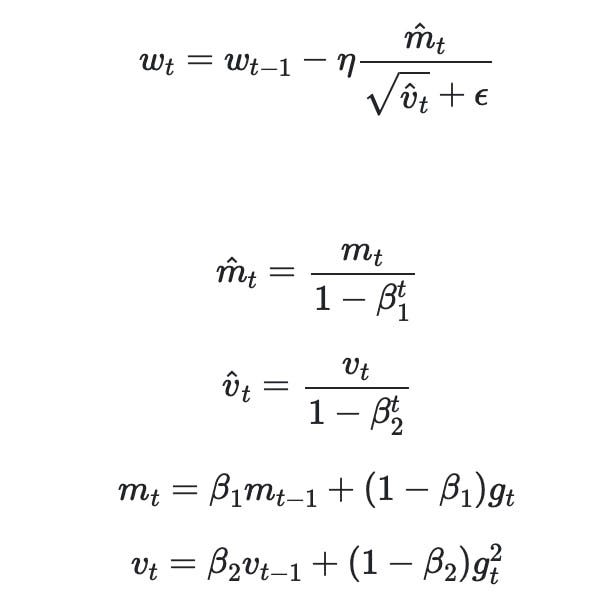
This might look scary. So, replace each of these fancy squigglies with the English alphabet as follows:
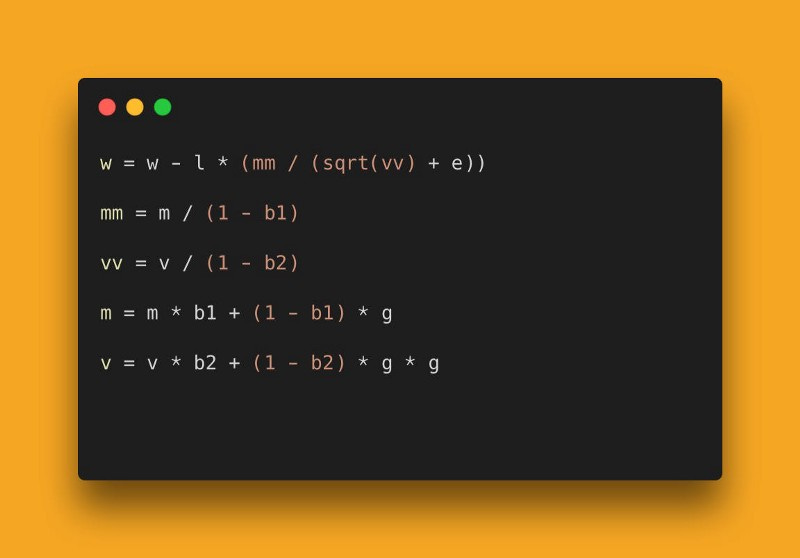
This doesn’t look as menacing. Essentially, you need to do some addition, subtraction, multiplication, and division. The most complicated thing in this is taking a square root! You might ask me, “Well what about the t and t-1 in the subscripts?”. That’s simply to denote the iteration. You just need to do these steps in a loop and overwrite the values in these variables accordingly.
While there will be papers with more complicated equations, the principles remain the same. Remember, these equations are just supposed to be concise ways to represent ideas. They always boil down to high school math.
Now, you’re ready to code and test out the paper’s claims.
I hope you try this method out on the next paper you implement. Let me know how it works for you.
🤖💪 Want more ideas to be a productive ML practitioner?
Each week, I send out a newsletter with practical tips and resources to level up as a machine learning practitioner. Join here for free →