

Ilya on the Scaling Limits, Build DeepSeek From Scratch, and Why Agents Fail 80% of Real Tasks: The Tokenizer Edition #11
This week's most valuable AI resources

Hey there! The gap between what we think AI agents can do and what they actually accomplish just got measured, and the results are humbling. Turns out data agents succeed at realistic enterprise-style data engineering workflows less than 20% of the time. Meanwhile, researchers found a dead-simple attention mechanism tweak that mitigates multiple transformer problems at once. Sometimes progress looks less like breakthroughs and more like finally admitting what doesn’t work.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Comprehensive surveys exposing agent architecture confusion, hidden learning dynamics challenging loss curves, rendering breakthroughs making 3D reconstruction practical, and benchmarks revealing where data agents actually fail
🎥 Videos: Real-world AI engineering wisdom from transformers vs CNNs debates, production codebase strategies that work, and Ilya Sutskever on why we’re shifting from scaling to research
📰 Reads: Model serving fundamentals, nanochat meets HuggingFace, and practical ML interview preparation
🛠 Tools: Debugging research papers systematically, and comprehensive Nano Banana resources
🎓 Learning: Building DeepSeek from scratch in a structured video series
Grab my first book — AI for the Rest of Us — today!
Quick note: If you find the book useful, please leave a review on Amazon. It makes a world of difference. If you have a picture of the book IRL, please share it with me. I really appreciate it.
📄 5 Papers
Agentic AI: A Comprehensive Survey of Architectures, Applications, and Future Directions
https://arxiv.org/abs/2510.25445
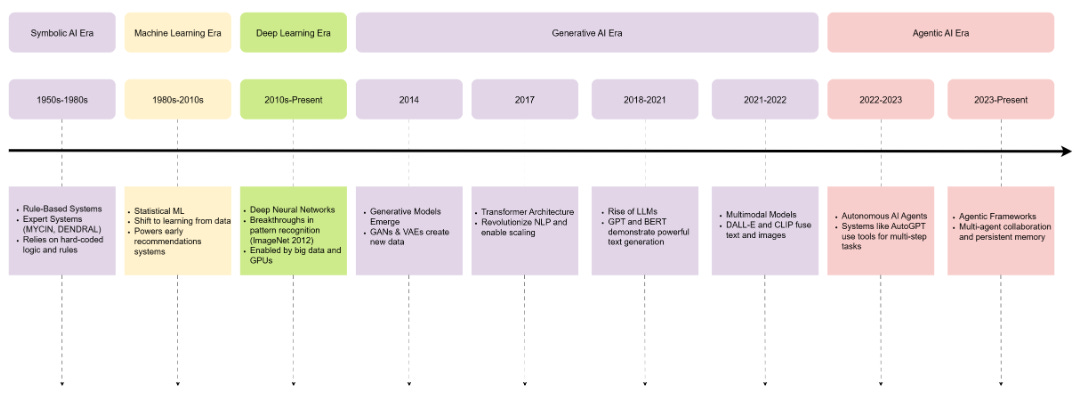
The field keeps retrofitting modern LLM-based agents into outdated symbolic frameworks, creating massive confusion about how these systems actually work. This survey addresses this by introducing a dual-paradigm framework that separates symbolic/classical systems (algorithmic planning, persistent state) from neural/generative ones (stochastic generation, prompt orchestration). Through analyzing 90 studies from 2018 to 2025, the authors reveal how paradigm choice is strategic: symbolic dominates safety-critical healthcare, neural prevails in adaptive finance. The real contribution is identifying critical gaps, including governance deficits for symbolic systems and the pressing need for hybrid neuro-symbolic architectures.
Quiet Feature Learning in Algorithmic Tasks
https://arxiv.org/abs/2505.03997
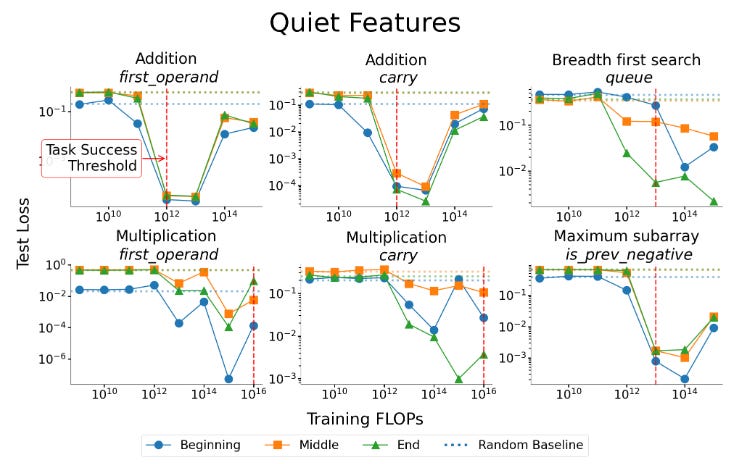
Loss curves lie. Transformers trained on algorithmic tasks show phase transitions where validation loss barely budges across massive compute ranges, then suddenly drops. Probing internal representations reveals quiet features being learned before any loss improvement - intermediate computations causally necessary for performance but invisible to output metrics. Ablation experiments prove individual quiet features are essential, strongly challenging the assumption that cross-entropy reliably tracks learning progress. Substantial representational progress happens beneath flat loss curves, demanding richer diagnostics for monitoring training.
Radiance Meshes for Volumetric Reconstruction
https://arxiv.org/abs/2512.04076 | GitHub
Radiance fields finally get a representation that hardware actually likes. This work uses Delaunay tetrahedralization to create constant-density tetrahedral cells that render using native triangle rasterization instead of complex ray-tracing. The method handles topological discontinuities from optimizing vertex positions with a Zip-NeRF-style backbone, maintaining smooth fields despite topology changes. Real-time view synthesis on consumer hardware with exact volume rendering equation evaluation - faster than all prior radiance field representations at equivalent primitive counts.
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
https://arxiv.org/abs/2505.06708 | GitHub
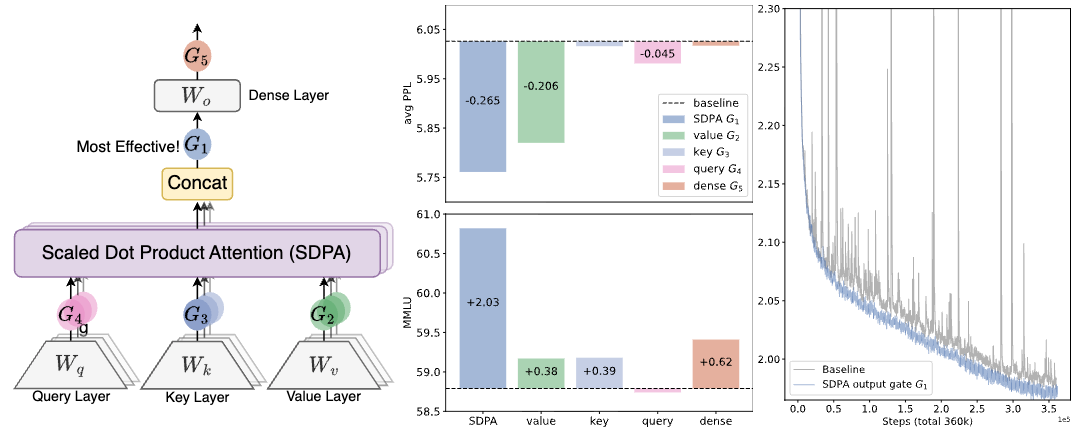
Applying a head-specific sigmoid gate after attention output fixes multiple transformer pathologies simultaneously. Tested across 30 variants of 15B MoE models and 1.7B dense models on 3.5 trillion tokens, this simple modification introduces non-linearity, breaking the low-rank bottleneck while enabling query-dependent sparsity. The sparse gating eliminates attention sink phenomena where early tokens absorb unwanted probability mass, enhances training stability for larger learning rates, and improves long-context extrapolation. The effectiveness comes from two factors: non-linearity on the value-output transformation and input-dependent sparse modulation of attention outputs.
DAComp: Benchmarking Data Agents across the Full Data Intelligence Lifecycle
https://arxiv.org/abs/2512.04324
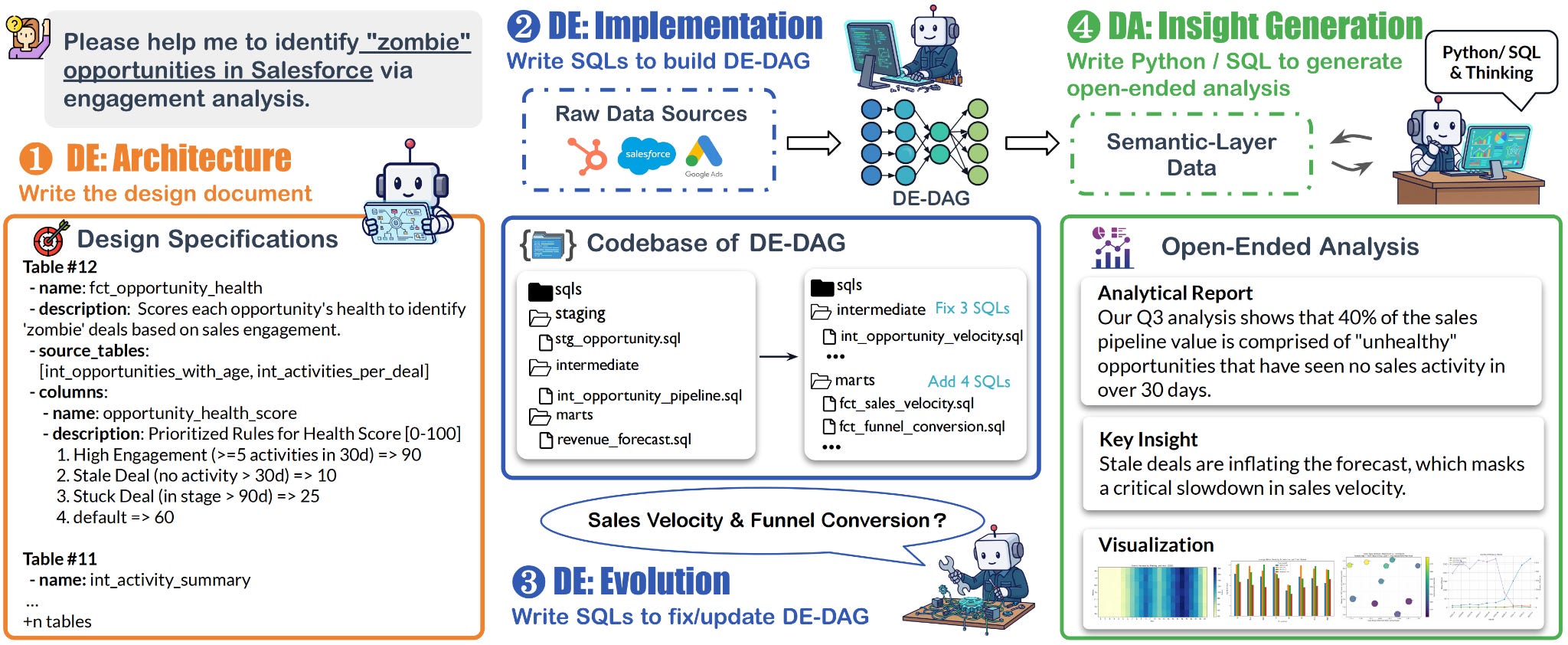
Enterprise data work is a closed loop, not isolated SQL generation. This benchmark of 210 tasks evaluates agents on repository-level data engineering and open-ended analysis that mirrors actual workflows. Data engineering tasks require designing multi-stage SQL pipelines from scratch and evolving systems under changing requirements - often involving 4,000+ lines across 30+ files. State-of-the-art agents achieve under 20% success on engineering tasks, exposing failures in pipeline orchestration, not code generation. Data analysis tasks average below 40%, proving that engineering and analysis require distinct capabilities. The holistic evaluation reveals where autonomous data agents actually break down in production settings.
🎥 4 Videos
Why are Transformers replacing CNNs?
Julie Turc breaks down why transformers classify images differently than ResNets, despite CNNs being explicitly designed for vision. The video compares convolution versus self-attention, explains CNNs’ inductive biases (locality, translation invariance, hierarchical features), and demonstrates why self-attention can be more expressive than convolution. You’ll see how attention can exactly implement convolutional kernels using relative positional encodings, making the transition from CNNs to vision transformers less mysterious and more mechanistically grounded.
No Vibes Allowed: Solving Hard Problems in Complex Codebases
Dex Horthy addresses the productivity paradox where AI coding tools excel at new projects but often make developers less productive in large, established codebases. The solution isn’t waiting for smarter models - it’s context engineering. This talk demonstrates techniques for getting Claude Code to handle 300k LOC Rust codebases and ship a week’s work in a day while maintaining code quality. The “frequent intentional compaction” family of techniques systematically structures how you feed context throughout development, making agents effective in real production environments.
VoiceVision RAG - Integrating Visual Document Intelligence with Voice Response
Suman Debnath demonstrates integrating Colpali’s vision-based retrieval with voice synthesis for next-generation RAG systems. Colpali generates multi-vector embeddings directly from document images, bypassing OCR and complex preprocessing while handling mixed textual and visual information. Adding voice output creates more intuitive and accessible user experiences. The workshop shows how this combination handles documents traditional RAG struggles with, leading to more efficient retrieval with natural voice responses.
We’re moving from the age of scaling to the age of research
Ilya Sutskever and Dwarkesh Patel discuss SSI’s strategy and the fundamental shift in AI development. Ilya explains problems with current pre-training approaches, how to improve model generalization, and ensuring AGI development goes well. The conversation covers why simple scaling has limitations and what research-focused approaches might unlock next. Essential viewing for understanding how leading researchers think about the transition from brute-force scaling to more sophisticated development strategies.
📰 3 Curated Reads
Model Serving Engineering: A Primer

Samuel Flender covers the engineering fundamentals of serving ML models in production. The piece addresses infrastructure design, latency optimization, scaling strategies, and reliability patterns that matter when your model faces real traffic. Helpful for practitioners moving from research to deployment who need to understand the operational layer between training and user-facing applications.
Porting nanochat to Transformers: an AI modeling history lesson
https://huggingface.co/spaces/nanochat-students/transformers#what-is-nanochat

The HuggingFace team walks through porting nanochat to the Transformers library, using the exercise to explain transformer architecture evolution and implementation decisions. You’ll see how historical choices in model design translate to modern library conventions, making the abstraction layers more transparent. Good for understanding what’s actually happening under the hood when you call a transformers model.
Interview Prep: The ML Grind
https://twopug.com/interview-prep-ml-grind/
Jenya provides practical guidance for ML interview preparation covering the technical foundations, coding patterns, and system design knowledge companies actually test. The resource focuses on what works for getting through technical screens rather than comprehensive ML education, making it useful if you’re actively interviewing or want to identify gaps in applied knowledge.
🛠 2 Tools & Repos
Paper Debugger
https://github.com/PaperDebugger/PaperDebugger
This tool helps you systematically debug research papers by identifying inconsistencies, verifying claims, and tracking experimental setups. When reproducing results or implementing papers, it provides structure for catching errors and understanding discrepancies between what’s written and what actually works. Useful for researchers implementing papers who’ve encountered the gap between description and reality.
Awesome Nano Banana Pro
https://github.com/ZeroLu/awesome-nanobanana-pro

A curated collection of resources for Google’s Nano Banana image generation model (revealed as Gemini 2.5 Flash Image). The repo aggregates tutorials, implementation examples, and community contributions around the model that topped LMArena rankings. Helpful for anyone exploring Gemini’s image capabilities or character consistency features in their projects.
🎓 1 Pick of the Week
Build DeepSeek from Scratch
https://youtube.com/playlist?list=PLPTV0NXA_ZSiOpKKlHCyOq9lnp-dLvlms
Vizuara’s video series takes you through implementing DeepSeek from foundational concepts to working code. Rather than just explaining what DeepSeek does, you’ll build the architecture piece by piece, understanding each design decision. The structured approach makes complex model architectures concrete through implementation, helping you move from conceptual understanding to actual capability building.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.
Regarding the topic of the article, what if admitting current AI limitaitons is the actual breakthrough moment for developing truly robust systems?
That 20% success rate on data engineering workflows is brutal but honestly not surprising. The gap between generating SQL snippets and actually orchestrating a full pipeline with dependencies is huge. Most agents bomb when they have to maintain state across multiple steps or handle edge cases that weren't in the training data. Would love to see more focus on these end-to-end benchmarks instead of just isolated code gen metrics.