

Inside Claude Code, OpenAI Codex, and HuggingFace's ML Engineer Agent : 📚 Tokenizer #26
This week's most valuable AI Resources

The AI-coworker metaphor stopped being a slide this week and started being software I could `pip install`. OneManCompany argues the bottleneck in agent teams is organisational, and posts 84.67% on a benchmark that tests whether agents can write production-quality product specs. RecursiveMAS lets agents pass refined “thoughts” between rounds instead of plain text, and reports an 8.3% average accuracy gain while using up to three-quarters fewer tokens. HuggingFace shipped ml-intern, an ML engineer agent you install with a single command and point at a paper on Friday afternoon.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate high-signal AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: an organisational layer for agent teams that scores 84.67% on a product-spec benchmark, a way to make multi-agent systems “loop” the way single models do, a test-driven approach to building training data, a safety survey for robots that see-and-act, and a scaling law that prices one extra loop at 0.46 of a fresh parameter.
🎥 Videos: an OpenAI workshop on Codex with custom subagents, Dave Ebbelaar’s five-level taxonomy of agent complexity, a Stanford seminar on world models that predict in compressed space rather than pixel space, and Sasha Rush on building Cursor Composer.
📰 Reads: a source-code walk through Claude Code’s internals, Eugene Yan’s three-step workflow for evaluating AI products, and Tom Aarsen on a single library that now embeds text, images, audio, and video into one shared space.
🛠 Tools: Zilliz’s claude-context, which turns your codebase into searchable context for a coding agent, and trycua/cua, an open-source toolkit for letting agents drive macOS, Linux, Windows, and Android.
🎓 Learning: HuggingFace’s ml-intern, an open-source ML engineer agent that reads papers, pulls datasets, runs training jobs, and iterates on its own evaluations.
📄 5 Papers
1. From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company
https://arxiv.org/abs/2604.22446 | GitHub
Most multi-agent papers try to fix the individual agent. This one argues the bottleneck is one level up: there is no org chart. Nothing decides who works on what, who reports to whom, or how the team improves over time. OneManCompany (OMC) packages skills, tools, and configs into reusable workers it calls “Talents,” lets agents recruit them on demand from a shared pool, and runs the team through a plan-act-review loop that is mathematically guaranteed not to get stuck. On PRDBench (which tests whether agents can write production-quality product requirement docs), OMC scores 84.67%, beating the prior best by 15.48 percentage points. If you’ve spent the last six months wiring up bespoke crews per task, this is the paper that names the thing you’ve been working around.
2. Recursive Multi-Agent Systems
https://arxiv.org/abs/2604.25917 | GitHub
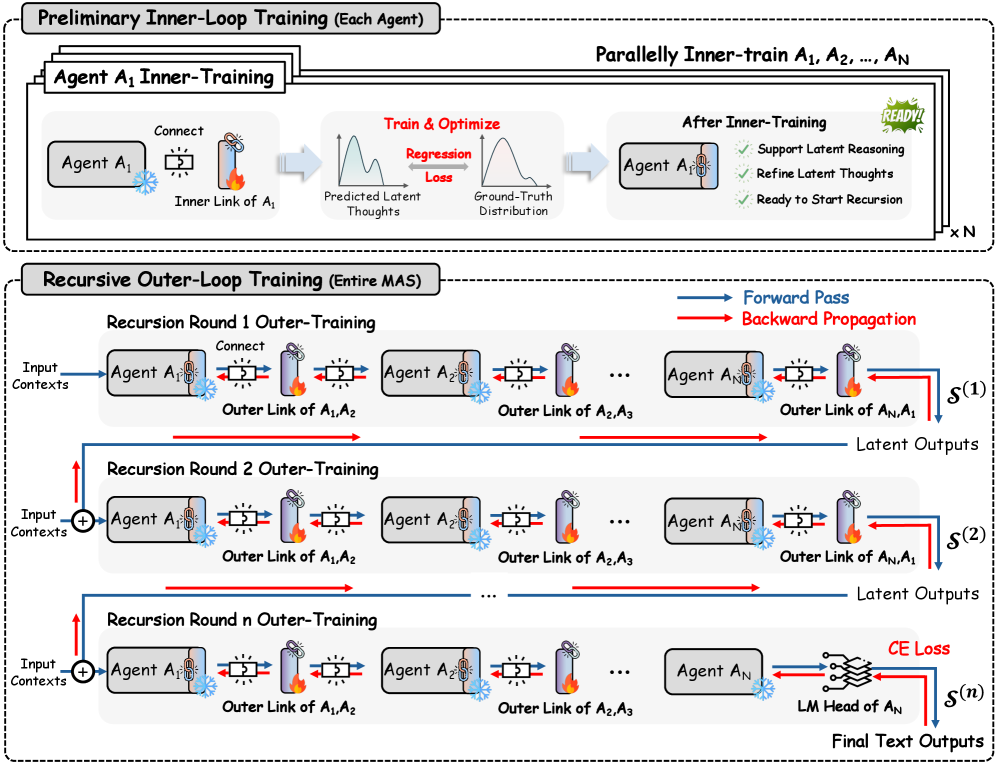
Some language models get smarter by running the same internal layers multiple times over a problem, refining a “thought” each pass. RecursiveMAS lifts that trick to teams of agents: instead of negotiating in plain text, agents hand each other a compressed thought and refine it round by round through small connector modules. The whole system is trained end-to-end so the team learns where each round contributed. Across nine benchmarks spanning math, science, medicine, search, and code, the framework reports an average 8.3% accuracy gain while using up to three-quarters fewer tokens. Pair it with Iso-Depth (paper #5): looping is a real axis to scale on, not a curiosity.
3. Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs (ProDa)
https://arxiv.org/abs/2604.24819 | GitHub
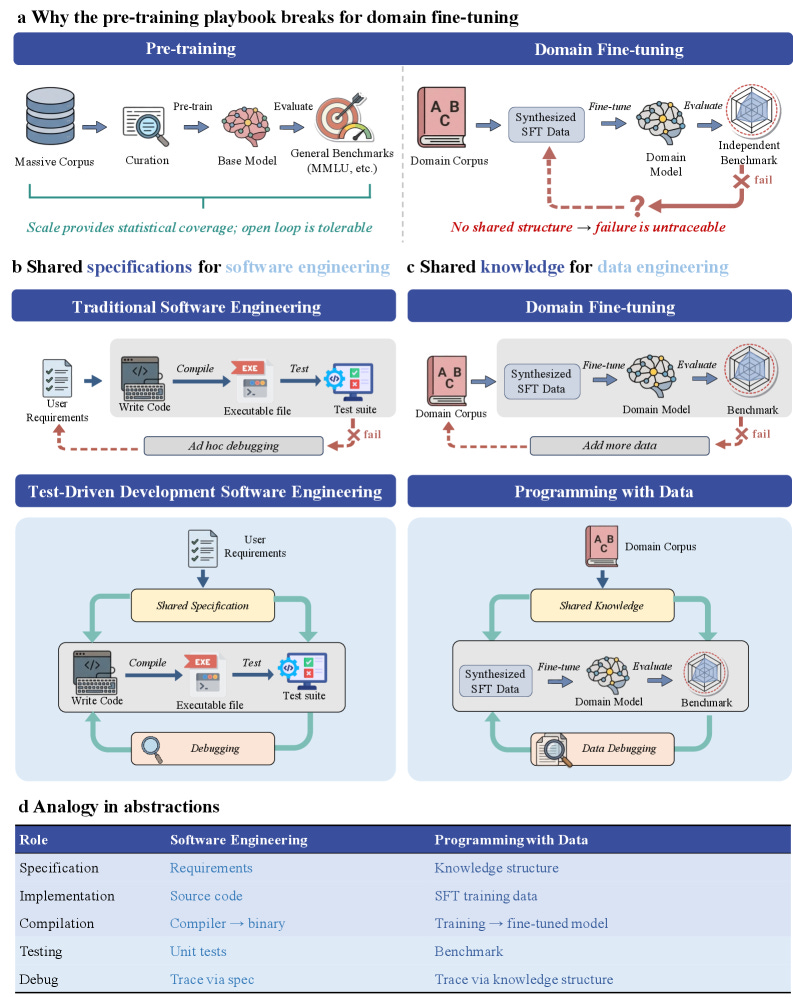
I found this analogy quite sticky and memorable. Training data is your source code. Training is the compile step. Benchmarks are your unit tests. Failure analysis is debugging. When the model fails, the failure traces back through the data the way a stack trace traces back through a function call. You patch the dataset where the gap actually lives, not the model. The team instantiates the loop across sixteen disciplines covering natural sciences, engineering, biomedicine, and social sciences, and ships a structured knowledge base, benchmark suite, and training corpus alongside the 57-page paper. If your fine-tuning pipeline is “train, eval, scratch head, add more data,” this is the pattern that retires it.
4. Vision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
https://arxiv.org/abs/2604.23775 | GitHub
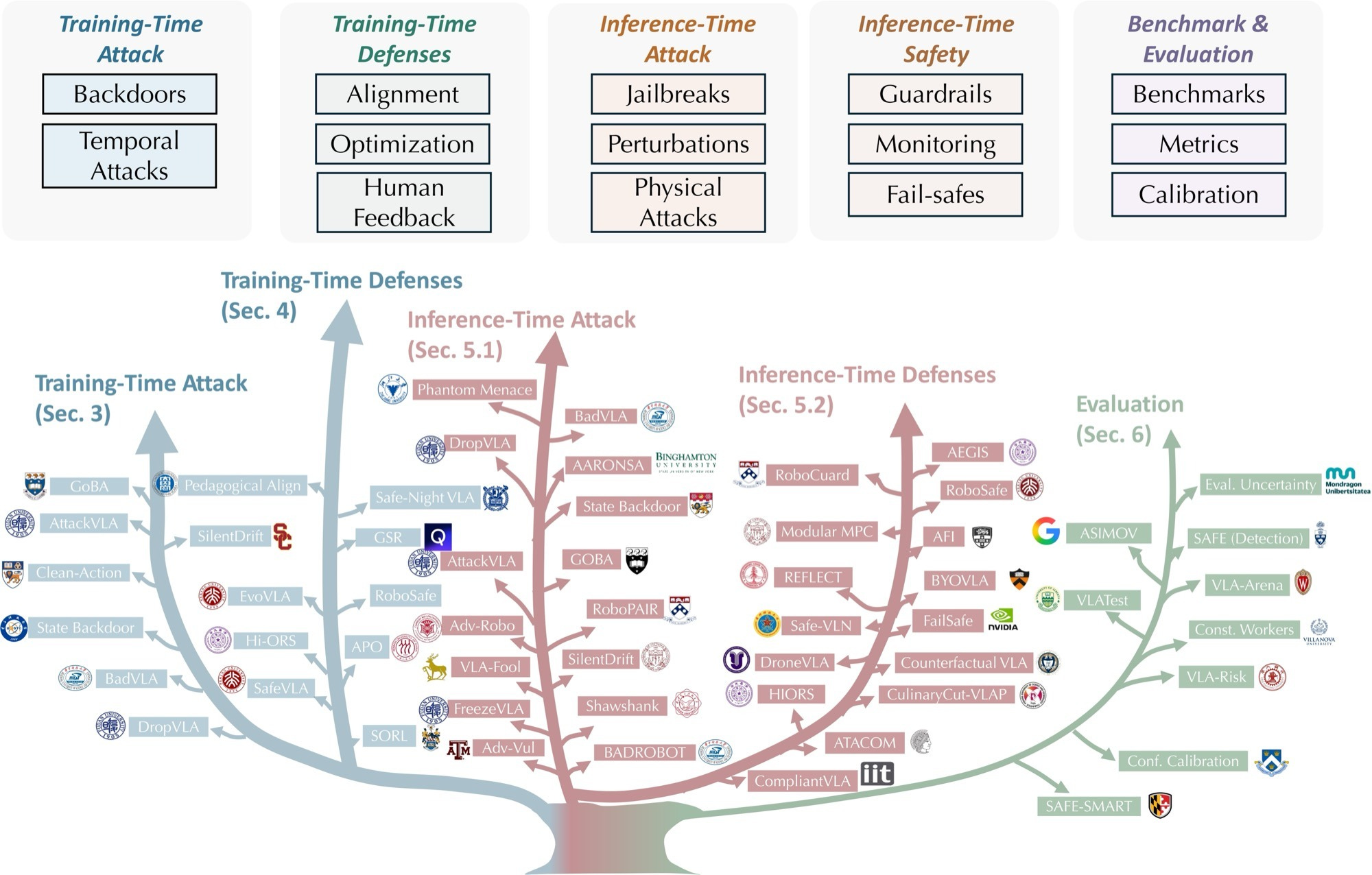
A reference for anyone building or auditing robots and agents that see, read, and then act in the world (the field calls them Vision-Language-Action models, or VLAs). The survey maps the threat surface across two axes: when the attack happens (during training vs while the model is running) and which side you are on (attacker vs defender). It walks through hidden triggers planted in training data, jailbreaks that exploit how the model reads a scene, visual noise designed to fool it, and physical interventions in the real world. The defence half covers cleaner data, better reward signals, policy-level guardrails, runtime monitors, and physical fail-safes. The companion repo lists roughly 70 papers and resources with links. Pull this the next time someone hands you a VLA demo and asks if it’s safe to ship.
5. How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped LMs
https://arxiv.org/abs/2604.21106 | GitHub
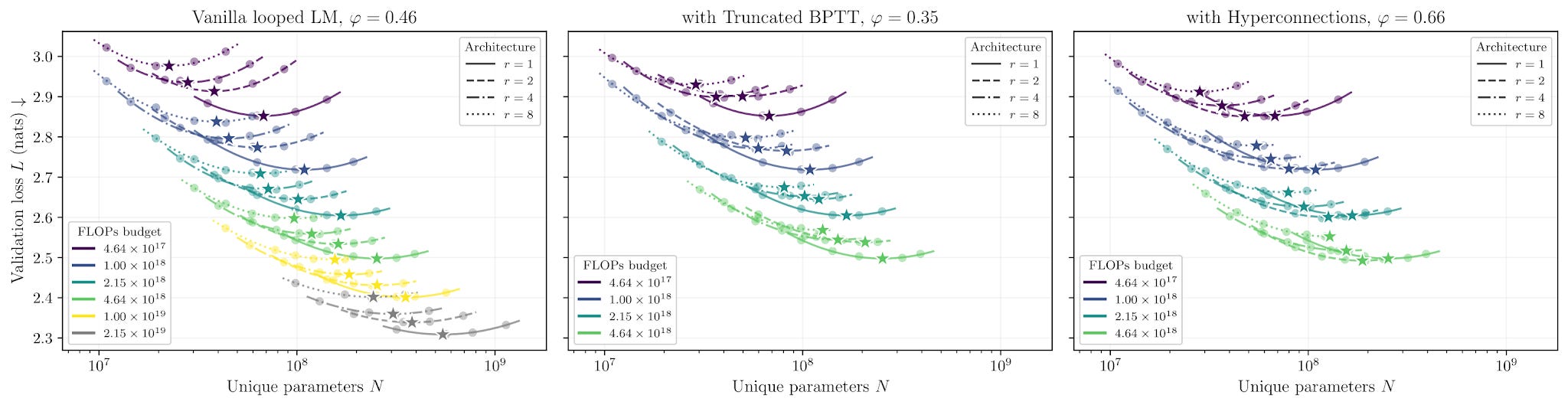
How much is one extra loop through a model’s own layers worth? About 0.46 of a fresh layer. Schwethelm, Rueckert, and Kaissis settle the argument with 116 training runs that vary the loop count (1, 2, 4, or 8) across roughly 50× of training compute, total depth pinned at 20. The endpoints anchor the scale: a fully shared loop would be worth 0%, a fully fresh layer 100%. A 410-million-parameter looped model matches a 580-million-parameter non-looped model on validation loss, though it costs about as much to train as a 1-billion-parameter one. Read this before your next architecture argument about whether weight-sharing is “free.”
🎥 4 Videos
1. Codex and Subagents: A 62-Minute Workshop
Vaibhav Srivastav and Katia Gil Guzman walk through the current Codex stack: the underlying models (GPT-5.3, Spark, GPT-5.4), the app and command line, plugins, automations, and custom subagents that each get their own model, permissions, and tools. The middle third is a live demo that runs from a Google Drive plugin to a Slack and Gmail automation to a GitHub code review to subagents reviewing persona files. The closing minutes touch the newer surface area: approval gates, hooks, personality settings, and the Cloud Code plugin. Sits next to ml-intern (this week’s Pick) and claude-context below: same AI-workforce idea, three surfaces.
2. Five Levels of AI Agent Complexity, From Augmented LLM to Multi-Agent
Dave Ebbelaar’s 22-minute breakdown is the clean taxonomy you can hand to a non-engineer when they ask “what is an agent.” Level 1 is an LLM with extra context. Level 2 is chaining and routing prompts in fixed steps. Level 3 is letting the model call tools. Level 4 is wrapping the model in a harness that decides what runs next. Level 5 is multiple agents coordinating. Code is on GitHub (using two common Python libraries for building agents), with traces from a live client system. The honest part is the framing of when each level is enough and when it is not. Worth 22 minutes if you are about to over-architect a workflow.
3. Stanford CS25 V6: From Representation Learning to World Modeling
World models used to mean: predict every pixel of the next frame. The change that Hazel Nam and Lucas Maes (Brown) walk through in this 71-minute Stanford seminar is to predict in a compressed, abstract space instead: fewer pixels, more meaning. This is the shortest route to where world-model research is in early 2026 without spending four hours on arxiv.
4. Sasha Rush on Building Cursor Composer at Ray Summit 2025
A 19-minute Anyscale keynote from Sasha Rush on the design behind Cursor Composer: how the agent reasons across a codebase, how speed and intelligence trade off when you ship to working developers, and what it took to make the experience feel uninterrupted. The model details and the product surface get equal weight, which is what you want when the agent is the product. Pair it with the Inside Claude Code read below for two takes on the same design problem.
📰 3 Curated Reads
1. Inside Claude Code: An Architecture Deep Dive
https://zainhas.github.io/blog/2026/inside-claude-code-architecture/
Zain Hasan walks the leaked Claude Code source (1,884 files, roughly 512,000 lines) across eleven sections, with ASCII diagrams and narrative pairs. The four-layer stack, the main query loop, the Tool interface, the permission cascade, and a deep dive on how the Grep tool wraps the ripgrep search utility are all useful. How Claude Code manages memory is the standout for me: five layers in all, including budgets for how much each tool result can return, automatic snipping of older content, micro-edits that update the cache in place, model-side summarisation, and a final auto-compaction that kicks in when the conversation gets within 13,000 tokens of the limit. Note that the author flags upfront that the post is a live document written with Claude’s help while reading the repo, which is itself a demo of the workflow it describes.
2. Product Evals in Three Simple Steps
https://eugeneyan.com/writing/product-evals/
Eugene Yan lays out a workflow you can run on Monday. Step one: pull roughly 200 real samples from production and hand-label 50 to 100 failure cases. Step two: train an LLM to judge new outputs the way you would. Use a binary pass/fail rather than a 1-to-5 scale (the gap between a 3 and a 4 is too hard to pin down), and check the judge against your labels using precision, recall, and an agreement score above 0.7. Step three: wire the whole eval loop into your experiment pipeline so every change produces a verdict without anyone running anything by hand. He splits the labelled samples 75% for development, 25% as a held-out test. Bookmark it the next time someone on your team says “we should add evals.”
3. Multimodal Embedding and Reranker Models with Sentence Transformers
https://huggingface.co/blog/multimodal-sentence-transformers
Tom Aarsen at HuggingFace walks through the new release of Sentence Transformers, the popular open library for turning text into searchable vectors. The release adds one shared interface that now embeds text, images, audio, and video into the same space. One model load, one `encode()` call across all four, and cross-type similarity that just works (a “green car” text query scores 0.51 against a car image and 0.10 against a bee image). The reranker scores mixed-type pairs the same way. The retrieve-and-rerank pattern at the end is exactly the pipeline most teams ship: a fast first pass to pull the top candidates, then a smaller, slower model to reorder them for accuracy.
🛠 2 Tools & Repos
1. zilliztech/claude-context
https://github.com/zilliztech/claude-context
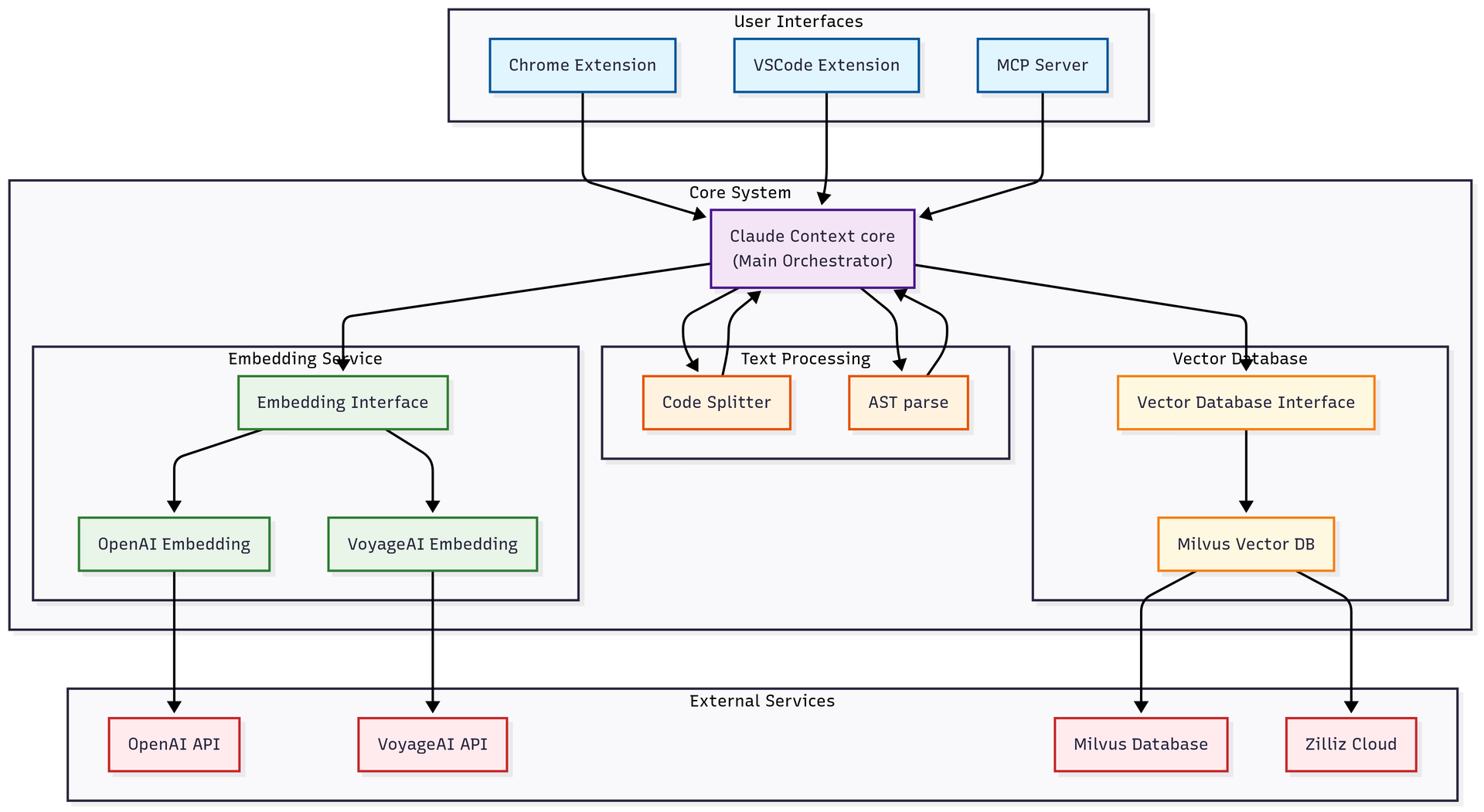
This is an MCP plug-in from the Zilliz team that turns your codebase into searchable context for a coding agent. It splits code into chunks based on the actual code structure, re-indexes only the files that changed since last time, and runs a hybrid search that combines classic keyword matching with vector similarity (the same combo that powers most modern search engines). They report roughly 40% fewer tokens compared to dumping whole directories into context. If you have been hand-feeding your coding agent files, this might be the install that ends that habit.
2. trycua/cua
Cua ships four pieces: a driver that automates native macOS apps in the background without hijacking your cursor, a sandbox that gives agents one common interface to virtual machines and containers across macOS, Linux, Windows, and Android, a desktop sandbox command line for coding agents with video streaming and a shared clipboard, and a benchmark suite for measuring how well an agent actually performs on common desktop tasks. If you are building a computer-use agent and want infrastructure you can actually inspect, this is where to start.
🎓 1 Pick of the Week
huggingface/ml-intern: An Installable ML Engineer Agent
https://github.com/huggingface/ml-intern
ml-intern is an agent that “autonomously researches, writes, and ships good quality ML related code using the Hugging Face ecosystem.” It reads papers, follows citations, pulls datasets from the HuggingFace Hub, runs training jobs, and iterates on its own evaluations. Two ways to run it: type `ml-intern` for an interactive session, or `ml-intern “your prompt”` for a hands-off run that auto-approves its own steps. Works with Anthropic or OpenAI behind it; needs HuggingFace and GitHub API keys. Hand it a paper you have been meaning to reproduce and see what the next morning looks like.
That’s the twenty-sixth Tokenizer. The interesting question for next week: which of these you actually install on Friday, and whether Monday’s repo looks different because of it. The long-form work continues at Gradient Ascent.