

Inside OpenAI's No-Review Codebase, the 98% of Claude Code That Isn't the Model, and BMad's Six-Agent Dev Team - 📚 The Tokenizer Edition #25
This week's most valuable email resources

Hey there! A recurring theme this week: the interesting frontier sat outside the model. VILA Lab took Claude Code apart at the source and found 98.4% of the codebase is operational infrastructure, not AI decision logic. OpenAI’s Frontier team shipped a 1M-line codebase at a billion tokens a day with zero human-reviewed code. BMad ships a six-agent dev team (analyst, PM, architect, UX, engineer, tech writer) that installs into your IDE with one command. The through-line: scaffolding is where the gains are hiding.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate high-signal AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: a source-level dissection of Claude Code, a self-evolving agent that argues for information density over context length, ByteDance’s next-generation video model, Tencent Hunyuan’s unified 3D world generator, and a principled recipe for on-policy distillation.
🎥 Videos: the physics behind Flow Matching, running LLMs locally on DGX Spark, engineering RL environments from scratch, and an anonymous operator conversation on AI budgets and code review.
📰 Reads: Hamel Husain on why eval craft belongs to data scientists, Paul Iusztin on harness engineering as the new OS layer around the LLM, and a transcript from inside OpenAI Frontier where a 1M-LOC codebase ships at a billion tokens per day with no human-written code.
🛠 Tools: Microsoft’s new agent framework with Semantic Kernel and AutoGen migration paths, and a Karpathy-style autoresearch loop for GPU kernels.
🎓 Learning: BMAD-METHOD, an open agile framework with six named agents that scaffolds AI-driven teams from brief to deployment.
📄 5 Papers
1. Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems
https://arxiv.org/abs/2604.14228 | GitHub
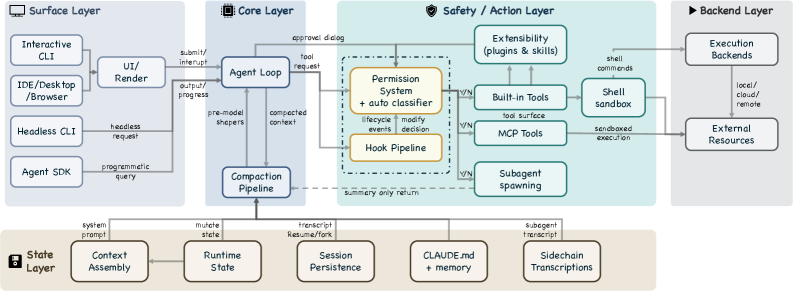
VILA Lab walked Claude Code’s TypeScript source (v2.1.88) and found that roughly 1.6% of the codebase is AI decision logic. The other 98.4% is operational infrastructure: permissions, context compaction, hooks, subagent isolation, session persistence. They extract five human values and thirteen design principles from that code, then trace them through seven components and five layers using a single running example (fixing a failing test in auth.test.ts). Read it if you’re building an agent and want to see how a production harness answers every design question at once.
2. GenericAgent: A Token-Efficient Self-Evolving LLM Agent via Contextual Information Density Maximization (V1.0)
https://arxiv.org/abs/2604.17091 | GitHub
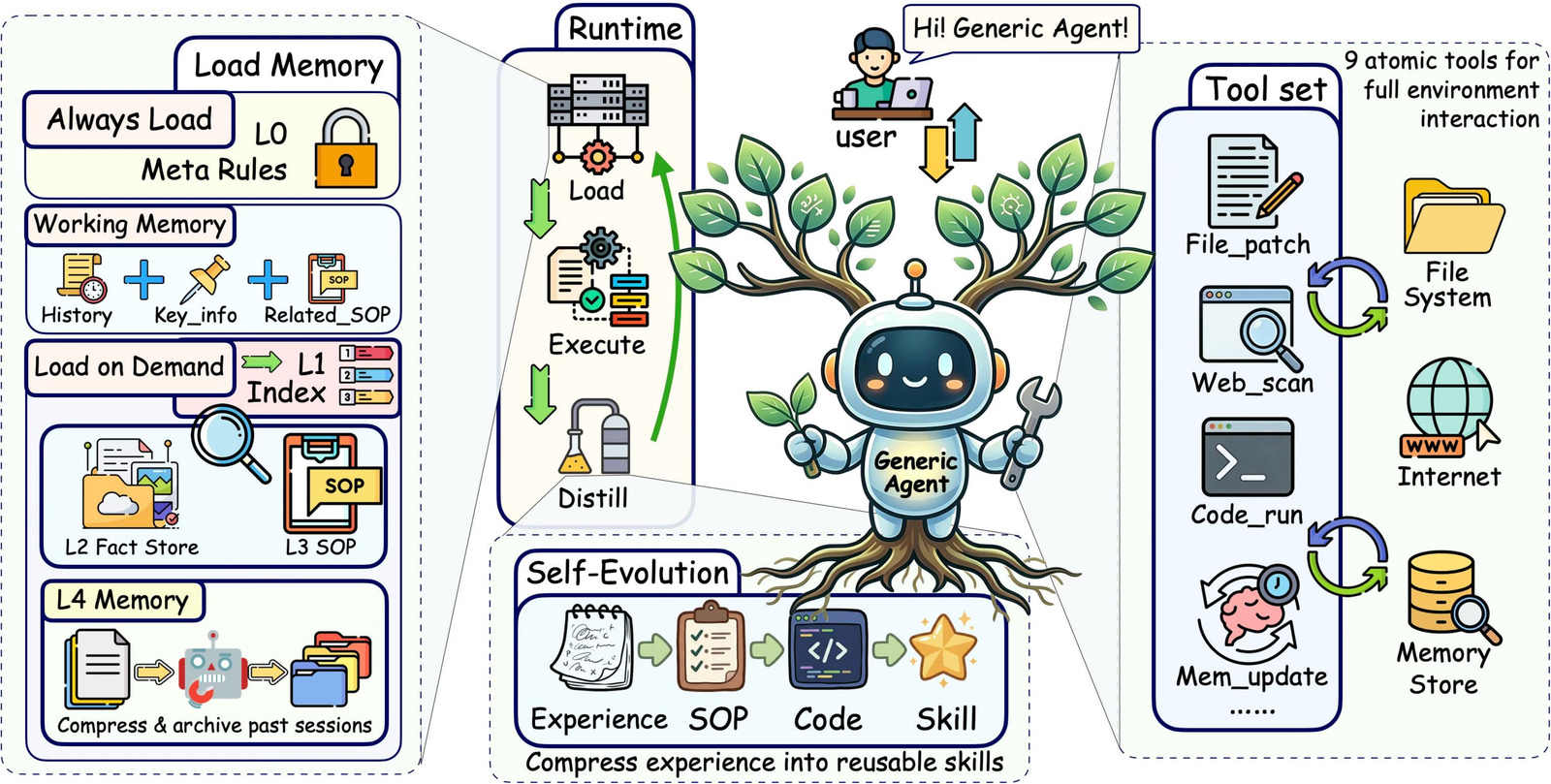
Long-horizon agent performance is bounded by information density inside a finite context window, not by context length itself. GenericAgent builds on four pieces. A minimal atomic tool set. Hierarchical on-demand memory. A self-evolution loop that turns verified trajectories into reusable SOPs and code. A runtime compression layer. The repo reports 188K tokens on long-horizon tasks where Claude Code spends 537K, at equal or better completion rates. Read this before you reach for the next context-length upgrade.
3. Seedance 2.0: Advancing Video Generation for World Complexity
https://arxiv.org/abs/2604.14148
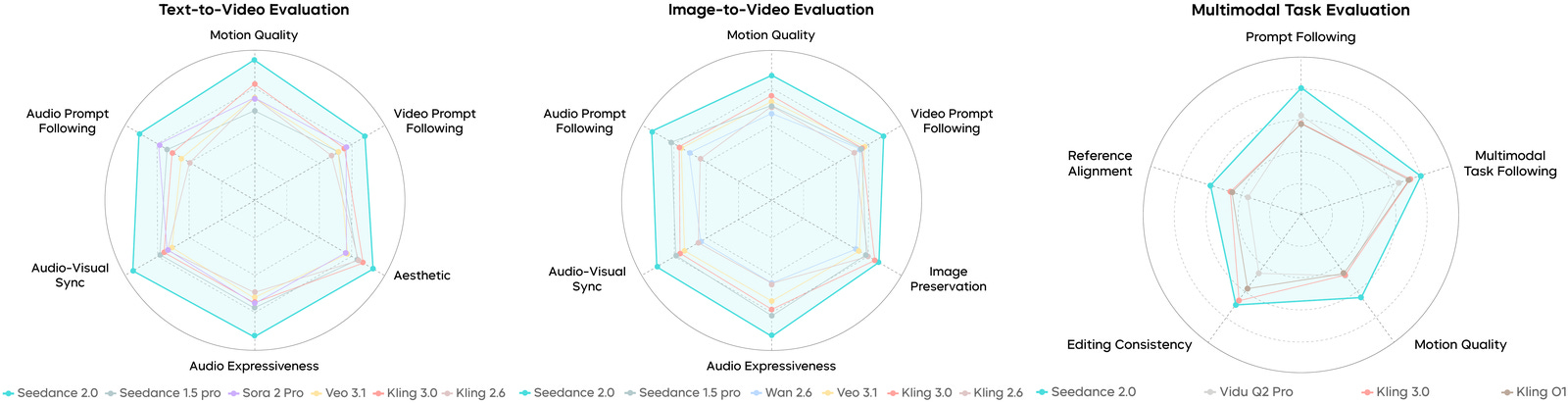
ByteDance Seed’s latest video model takes the #1 spot on both Text-to-Video and Image-to-Video leaderboards on Arena.AI, ahead of veo-3.1-audio-1080p on T2V and grok-imagine-video-720p on I2V. On the team’s own SeedVideoBench 2.0 set (against Kling, Sora, Veo, Wan, and Vidu), it ranks first in 29 of 30 fine-grained motion quality categories. The architectural bet is unified audio-video joint generation with native multi-modal input (text, image, audio, video) and simultaneous multi-track audio output with binaural synthesis. Pull the report if you want to see the current ceiling in open-access video generation.
4. HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
https://arxiv.org/abs/2604.14268 | GitHub

A single pipeline that does both 3D world generation and reconstruction, producing navigable 3D Gaussian Splatting scenes from text or one image alone. Tencent Hunyuan’s four-stage approach covers panorama generation, trajectory planning, camera-guided view generation, and final 3D composition. It reaches state-of-the-art among open-source 3D world models and reports parity with the closed Marble system. All weights and code are public, which matters for a field where most of the good stuff is still locked behind APIs.
5. Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
https://arxiv.org/abs/2604.13016 | GitHub
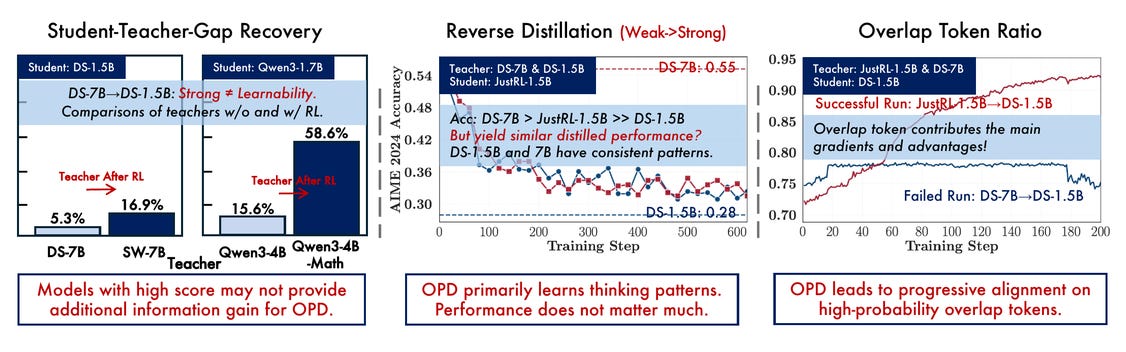
On-policy distillation keeps breaking in counterintuitive ways: a stronger teacher sometimes fails to improve a student while a weaker one succeeds. THUNLP’s team runs controlled experiments across the Qwen3 and DeepSeek families and lands on two governing conditions. Student and teacher need compatible thinking patterns (measurable via token-level overlap ratio), and the teacher needs to offer capabilities the student doesn’t already have (not just a higher benchmark score). They also propose an off-policy cold-start warm-up that recovers distillation in setups where it would otherwise collapse. If your post-training pipeline picks teachers by benchmark score, the overlap-ratio diagnostic here is the first thing to add.
🎥 4 Videos
1. The Physics Behind Flow Matching, Derived from Scratch
Flow Matching built up from the continuity equation and time-variant velocity fields, with the training loss arriving only after continuous normalizing flows are in hand. Julia Turc’s 24-minute walkthrough pairs with a free interactive tutorial at diffusion.fyi. It covers conditional velocity fields in the spot where most explanations either gloss over optimal transport or collapse into notation. Queue this when your current mental model of flow matching has a gap you cannot quite name.
2. Running LLMs Locally: Practical Performance on NVIDIA’s DGX Spark
Serving open-source models from 1.5B to 14B parameters on a single DGX Spark with vLLM, with the throughput, latency, and quantization trade-offs that drop out once you measure them. Mozhgan Kabiri Chimeh from NVIDIA shares a reproducible methodology, NVFP4 performance numbers on Grace Blackwell’s 128GB unified memory, and a framework for local model sizing. A 10-minute talk if you’re deciding whether on-prem compute clears the bar for your workload.
3. Engineering Reinforcement Learning Environments Like Software
RL environments treated as first-class software artifacts, not research scaffolding. Stefano Fiorucci, AI engineer at Deepset, uses the open-source Verifiers library to translate classical RL concepts to language models. He builds single-turn tasks, multi-turn games, and tool-using agents as concrete environments. Watch it before you write your next eval harness. A clean gym spec will save you rebuilding it three weeks in.
4. Stay Sassy and swyx on AI Budgets, Per-Person Token Spend, and Why Code Review Matters More
Per-person token budgets are a management problem, not a provisioning one, and code review gets more important as agents write more code, not less. That is the spine of a 57-minute Latent Space conversation between swyx and Stay Sassy, an anonymous operator with voice modulated for opsec. They cover build-vs-buy, where hand-coding still wins, and how real engineering leaders are allocating AI spend. Closest thing to eavesdropping on the hard numbers right now.
📰 3 Curated Reads
1. The Revenge of the Data Scientist
https://hamel.dev/blog/posts/revenge/

Training a model was never most of a data scientist’s job. The bulk of the work was running experiments to test how well a system generalizes, debugging stochastic behaviour, and designing metrics you can actually trust. Hamel Husain argues that LLM teams who cut data scientists out of the loop are now rediscovering the same five eval pitfalls, from off-the-shelf judge metrics that flatter bad systems to dashboards nobody would ship a classifier against. The piece names the concrete moves (error analysis from real traces, aligning LLM judges against human labels, constructing trust-metrics you would actually stake a launch on) and is the cleanest argument this year for why the old craft is now the new infrastructure.
2. Agentic Harness Engineering

The harness is where production agents actually live: tools, memory, sandboxes, and orchestration that let an LLM recover from failures, bridge context windows, serve multiple interfaces, and hold state across sessions. Paul Iusztin dissects the production harness behind Claude Code and Codex across a handful of components (context engineering, memory, sandboxing, tool layers, orchestration). He walks through how each piece solves a problem the model cannot solve on its own. The thesis: strip RAG pipelines and MCP layers back to plain Python until the harness itself earns the complexity.
3. Extreme Harness Engineering for Token Billionaires

OpenAI’s Frontier team wrote a 1M-line codebase at 1 billion tokens per day with zero human-written code and zero human-reviewed merges. Ryan Lopopolo walks through how they got there. The build system went from Make to Bazel to Turbo to Nx to hit a sub-one-minute loop. Observability was exposed to the agent so it can tell when it is going off track. Dependencies were inlined to remove version drift. Specs were written for the model, not the engineer. The conversation with Swyx and Alessio covers the agent code-review rules, autonomous merging, and why human attention is now the binding constraint. Read it before you argue with anyone about what a production agent harness should look like in 2026.
🛠 2 Tools & Repos
1. Microsoft Agent Framework
https://github.com/microsoft/agent-framework

Microsoft’s unified framework for building and orchestrating AI agents across Python and .NET, with graph-based workflows, streaming, checkpointing, human-in-the-loop, and time-travel. The interesting move is that it ships with explicit migration guides from both Semantic Kernel and AutoGen, positioning itself as the convergence point for Microsoft’s prior agent SDKs. 9,736 stars and active weekly office hours. If you already run Semantic Kernel or AutoGen in production, the migration guides are the fastest read on where Microsoft wants your next agent to live.
2. AutoKernel: Autoresearch for GPU Kernels
https://github.com/RightNow-AI/autokernel
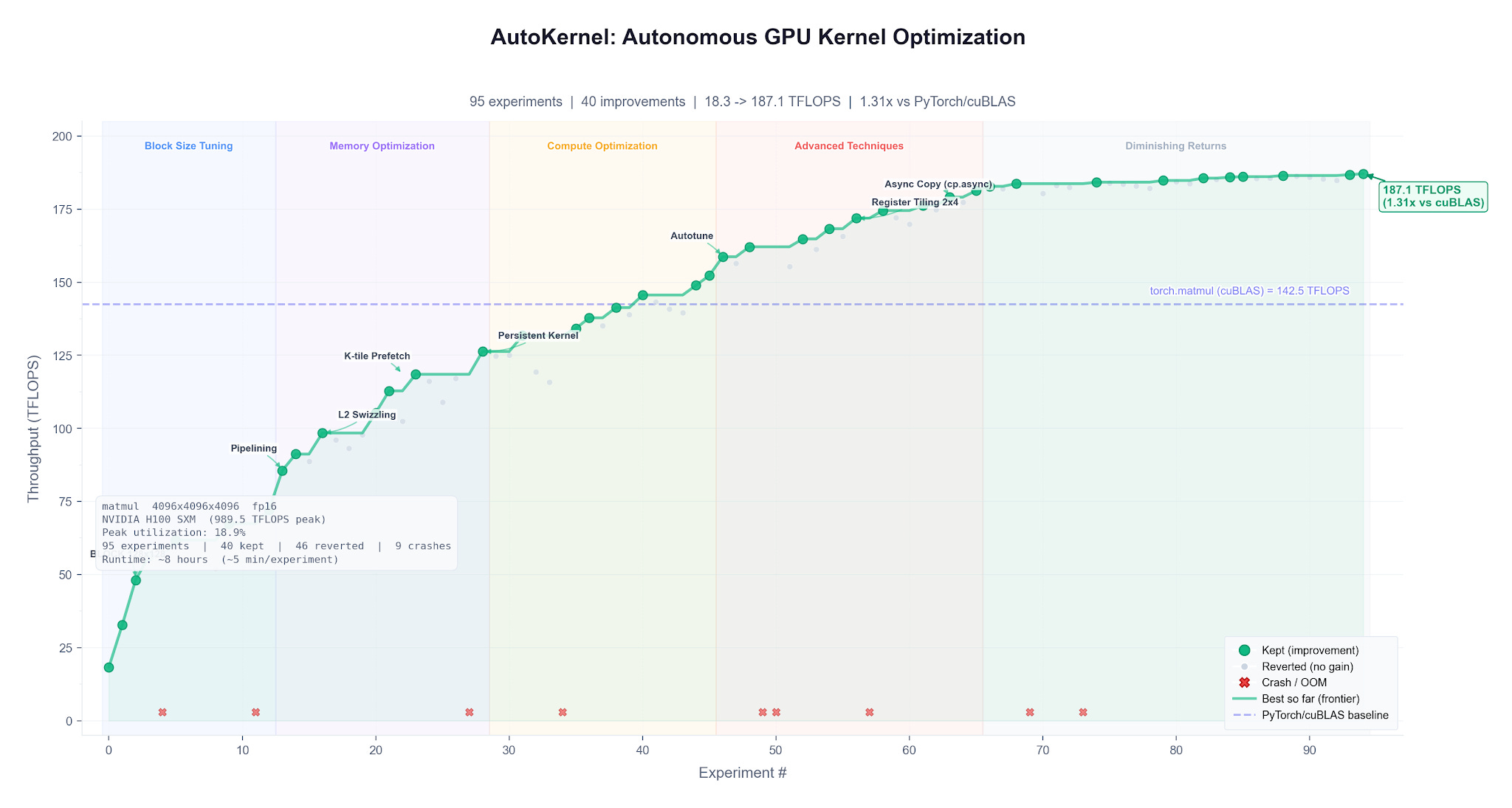
Karpathy-inspired autonomous loop that takes any PyTorch model, profiles it, extracts bottleneck kernels into standalone Triton or CUDA C++, and optimizes them one at a time in a keep-or-revert loop. Each experiment runs in about 90 seconds, roughly 40 per hour, 320 overnight. The orchestrator picks the next kernel using Amdahl’s law. 1,295 stars. Point it at a model you care about before bed and wake up to a speedup report.
🎓 1 Pick of the Week
BMAD-METHOD: Breakthrough Method for Agile AI Driven Development
https://github.com/bmad-code-org/BMAD-METHOD

BMAD-METHOD is an MIT-licensed framework that installs a full agile team of named AI agents into your IDE. You get six roles: Mary (business analyst), John (PM), Winston (architect), Sally (UX), Amelia (senior engineer), and Paige (tech writer). Each carries a consistent persona, a defined skill set, and a handoff point to the next. The core module ships 34+ workflows across brainstorming, PRD drafting, architecture, sprint planning, and code review. A solo developer can run a structured delivery loop without a real team. Install is one command (`npx bmad-method install`), and the framework picks up Claude Code, Cursor, and other IDEs on first run. 45K+ stars, actively maintained. Pick it up if you have been reaching for individu coding agents and find the scaffolding thinner than the model itself.
That’s the twenty-fifth Tokenizer. If one of these fifteen resources changes what you’re building this week, forward the edition to whoever should see it next, and come find the long-form work at Gradient Ascent.