

Karpathy's microGPT, Jeff Dean's Pareto Frontier, and the LLM Course - 📚 The Tokenizer Edition #18
This week's most valuable AI resources

Hey there! While agents crush bug fixes at 74%, they stumble to 11% on actual feature development. Turns out building real features is fundamentally harder than patching code. Meanwhile, passing a task to an agent and actually delegating authority to one turn out to be completely different problems, and Karpathy just distilled an entire GPT into 243 lines of dependency-free Python. These are structural shifts in how we approach autonomy, development, and education.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
I’m teaching ML & Generative AI System Design on Feb 28th / March 1st with Packt.
We’ll cover AI systems that use RAG and traditional ML design principles for building solid AI products: making systems reliable, measuring what matters, and designing architectures that work in production.
Through live discussions, guided exercises, and design sprints, you’ll practice solving system-level AI problems and walk away with frameworks you can apply immediately at work.

What topics/problems would you most want covered in a system design workshop? Drop a comment or DM me.
TL;DR
What caught my attention this week:
• 📄 Papers: Task handoff is not the same as authority transfer, video models tested on physics not aesthetics, memory that evolves without overfitting, gated reasoning that knows when to stop, and feature-level coding benchmarks exposing real agent limitations
• 🎥 Videos: Jeff Dean on AI’s Pareto frontier, comprehensive 2026 state of AI breakdown, building custom dev tools instead of buying SaaS, and practical context engineering for agents
• 📰 Reads: Rubric-based rewards for subjective domains, recursive language models that call themselves like functions, and why taste matters for generative AI
• 🛠 Tools: Reasoning implementations from scratch, comprehensive LLM learning roadmap
• 🎓 Learning: Karpathy’s microGPT strips GPT to its mathematical essence in pure Python
📄 5 Papers
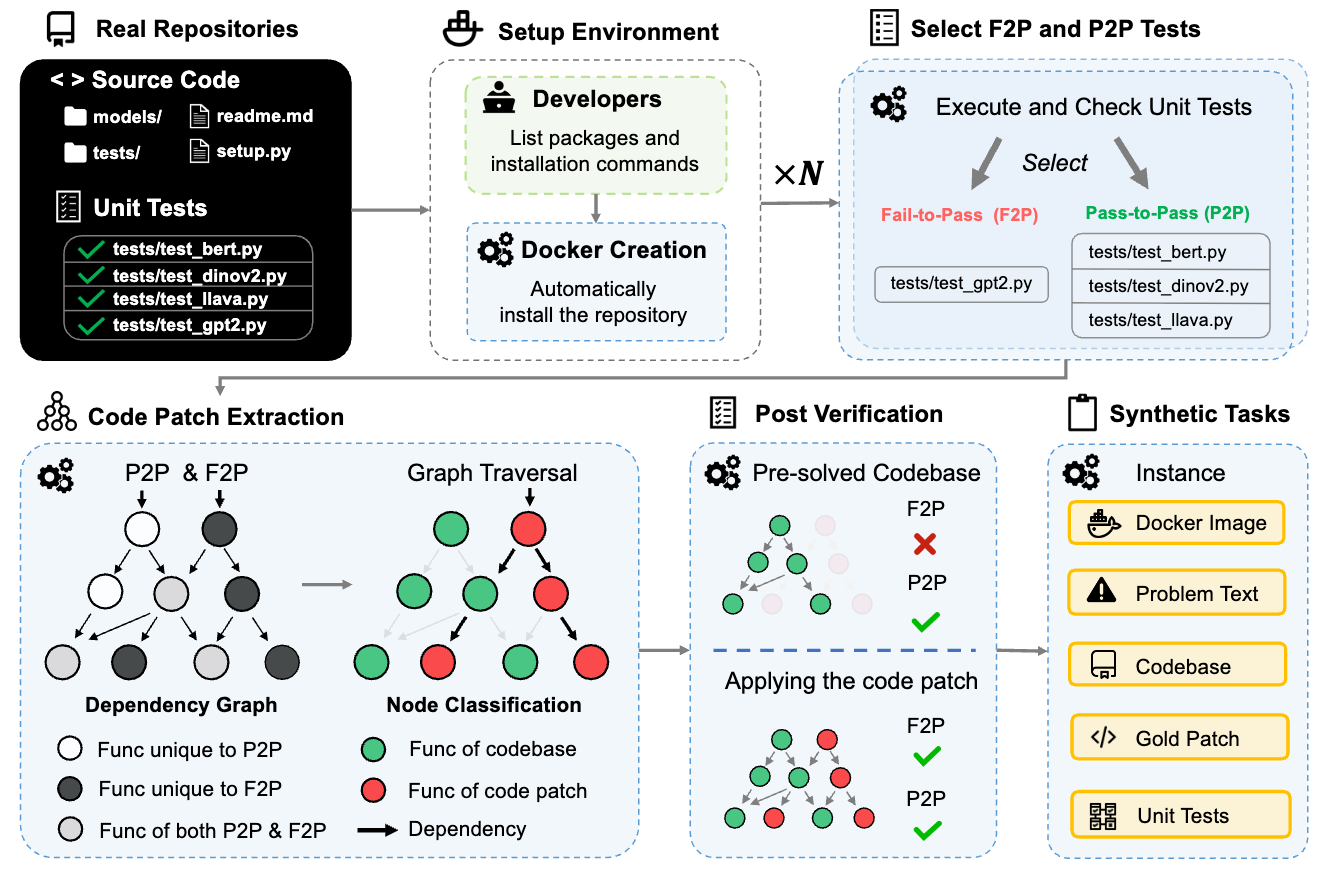
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
https://arxiv.org/abs/2602.10975 | GitHub
Claude 4.5 Opus achieves 74.4% on SWE-bench but drops to 11.0% on FeatureBench. The difference? SWE-bench tests bug fixes within single pull requests, while FeatureBench evaluates end-to-end feature development spanning multiple commits and PRs across development timelines. Using a test-driven method that traces from unit tests along dependency graphs, the benchmark automatically derives 200 feature-level tasks from 24 repositories while ensuring other features remain functional after separation. This exposes the gap between fixing localized issues and actually building new capabilities.
Intelligent AI Delegation
https://arxiv.org/abs/2602.11865
Existing delegation methods run on heuristics that collapse when environments change or sub-agents fail. Intelligent AI Delegation reframes the problem: passing a task is not the same as transferring authority, responsibility, and accountability, and conflating the two is where multi-agent systems break down. The framework draws from principal-agent theory in economics, assumes zero trust at every delegation boundary, and applies to both human and AI delegators across complex agent networks. Misalignment, reward gaming, and deceptive behavior all compound as agents delegate to other agents. The paper is trying to define the protocol layer the agentic web needs before it can safely scale.
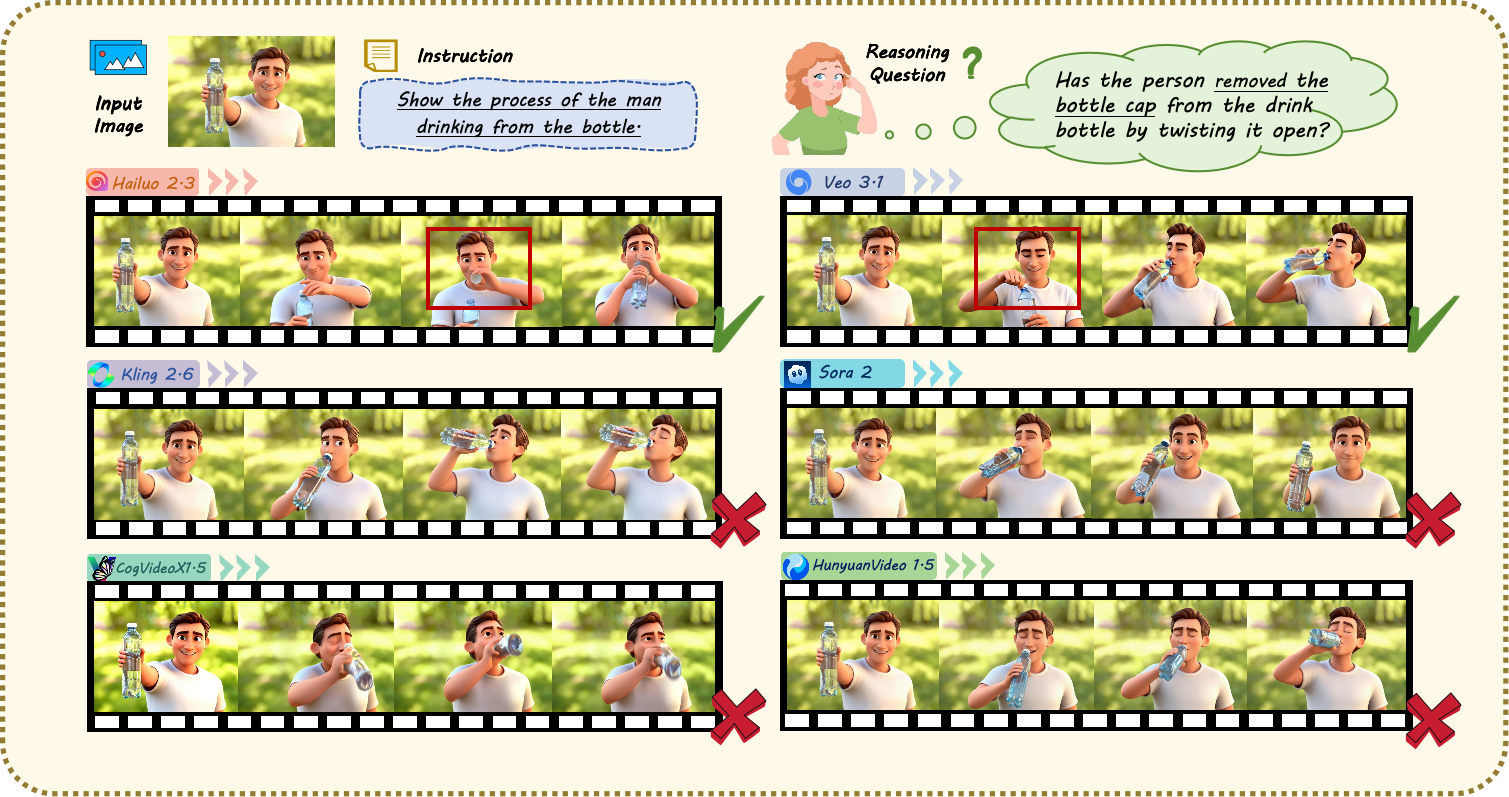
RISE-Video: Can Video Generators Decode Implicit World Rules?
https://arxiv.org/abs/2602.05986 | GitHub
Video models produce visually impressive outputs, but can they reason about physics? RISE-Video shifts evaluation from aesthetics to cognitive understanding with 467 human-annotated samples spanning eight categories. The benchmark tests whether models grasp implicit constraints like spatial dynamics, temporal consistency, physical rationality, and causality. Testing 11 state-of-the-art models revealed pervasive failures when simulating complex scenarios under implicit rules, exposing the gap between visual fidelity and genuine world understanding.
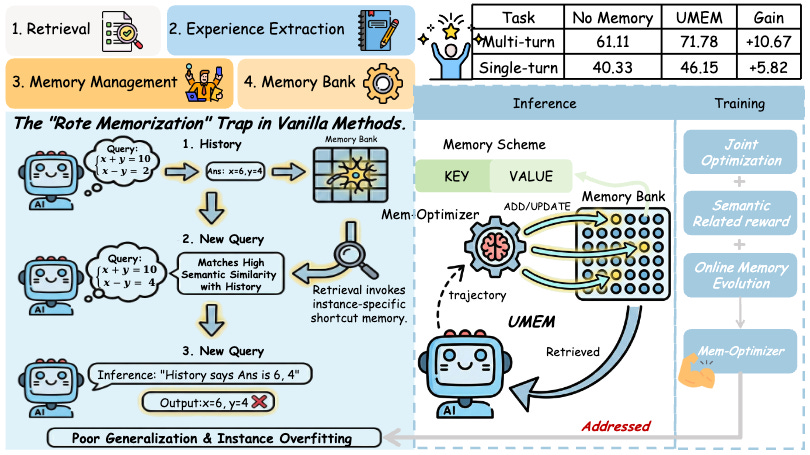
UMEM: Unified Memory Extraction and Management Framework for Generalizable Memory
https://arxiv.org/abs/2602.10652 | GitHub
Memory-enabled agents typically optimize management while treating extraction as static, accumulating instance-specific noise rather than robust insights. UMEM jointly optimizes both through Semantic Neighborhood Modeling, evaluating memory utility across clusters of semantically related queries rather than individual instances. Trained with neighborhood-level marginal utility rewards via GRPO, the approach achieves up to 10.67% improvement on multi-turn tasks while maintaining monotonic growth during continuous evolution. Agents that actually learn from experience rather than just retrieve logs.
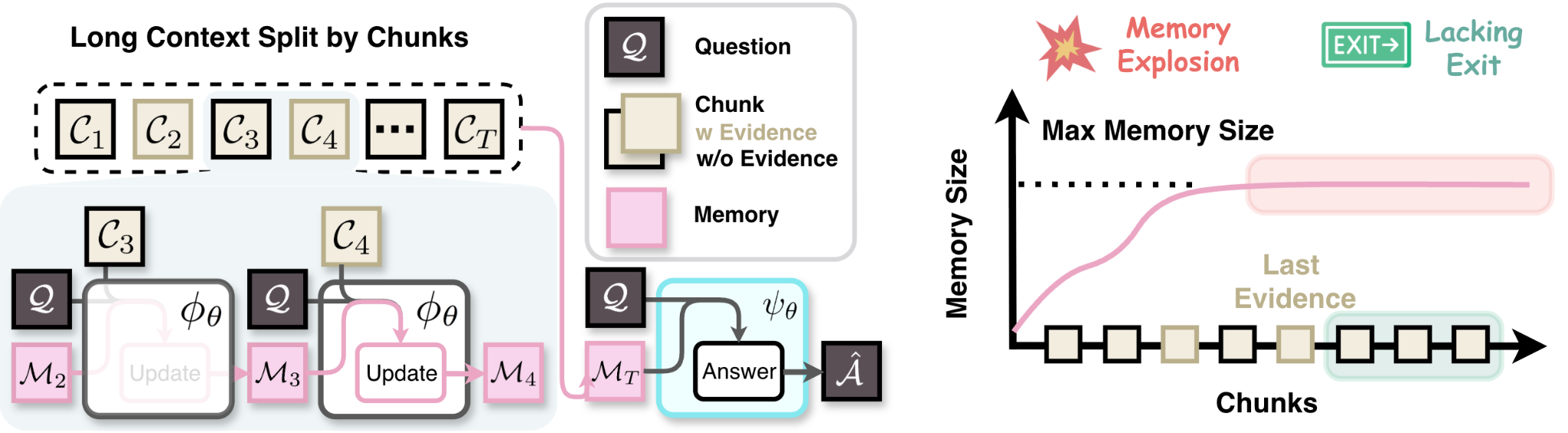
When to Memorize and When to Stop: Gated Recurrent Memory for Long-Context Reasoning
https://arxiv.org/abs/2602.10560
Long-context reasoning faces critical issues: memory explodes from indiscriminate updates on evidence-free chunks, and loops continue unnecessarily after gathering sufficient evidence. GRU-Mem introduces update and exit gates controlled by text. Memory updates only when the update gate opens, and the loop terminates immediately when the exit gate opens. Trained with end-to-end RL using separate rewards for correct updating and exiting behaviors, GRU-Mem outperforms vanilla MemAgent with up to 4x inference speed acceleration.
🎥 4 Videos
Owning the AI Pareto Frontier — Jeff Dean
Jeff Dean unpacks the Pareto frontier in AI scaling, balancing compute, energy efficiency and model performance. Google’s Chief AI Scientist discusses the unification of their AI teams and why distillation is becoming the engine behind efficient models. Essential viewing for understanding the tradeoffs between model capability and practical deployment constraints.
State of AI in 2026: LLMs, Coding, Scaling Laws & Agents
Nathan Lambert and Sebastian Raschka join Lex Fridman to break down where we actually stand. They cover the reality of coding agents (echoing FeatureBench findings), scaling laws beyond just “more compute,” and practical challenges of building reasoning models. Two of the best technical communicators in AI deliver a comprehensive status report on 2026’s landscape.
DIY Dev Tools: The Shift to “Build” Over “Buy”
CJ Hess demonstrates “Flowy,” a custom tool he built to visualize coding plans. Instead of relying on static Markdown or finicky diagrams, he created a system where Claude generates JSON that renders into interactive flowcharts and UI mockups. When AI can write the code, building bespoke internal tools optimized for your specific workflow is often faster and better than buying generic SaaS.
Effective Context Engineering for AI Agents
Dave Ebbelaar explains why agents fail not from bad instructions but from poor context management. In short, context engineering is king. He offers practical strategies for structuring workflows and managing the context window as a limited resource rather than a magic bucket.
📰 3 Curated Reads
Rubric-Based Rewards for RL

Cameron Wolfe explains that while RL has excelled in domains with clear answers like math and code, Rubric-Based RL uses LLMs as judges with strict rubrics to provide reward signals in subjective domains. This bridges the gap that could allow training reasoning models for writing, creativity, and strategy rather than just problems with verifiable solutions.
Recursive Language Models: To the Rescue

What if an LLM could call itself like a function? Recursive Language Models decompose complex prompts and recursively generate their own context. This architectural shift treats models less like text predictors and more like computer programs with call stacks, handling complexity through recursion rather than scale.
Taste for Makers
https://paulgraham.com/taste.html
Paul Graham breaks down the universal principles of good design across disciplines like math, coding, and architecture. For anyone building AI products today, treating “quality” as an objective, engineerable standard rather than a vague feeling is a massive competitive advantage.
🛠 2 Tools & Repos
Reasoning from Scratch (Chapter 7 Code)
https://github.com/rasbt/reasoning-from-scratch/blob/main/ch07/01_main-chapter-code/ch07_main.ipynb
Sebastian Raschka’s notebook implements Reinforcement Learning with Group Relative Policy Optimization (GRPO) from scratch. If you want to understand how models like DeepSeek-R1 work under the hood, this walks through the actual mechanics rather than hiding behind abstractions. Essential for anyone implementing reasoning capabilities.
LLM Course Roadmap
https://github.com/mlabonne/llm-course
Maxime Labonne’s repository remains the gold standard for self-learning. This curated roadmap takes you from fundamentals to fine-tuning your own models, recently updated with sections on agentic workflows and evaluation. The curriculum balances theoretical explanations with practical notebooks and hands-on projects mirroring real-world applications.
🎓 1 Pick of the Week
microGPT
https://karpathy.github.io/2026/02/12/microgpt/
Andrej Karpathy stripped GPT to its absolute core: 243 lines of pure Python with zero dependencies. No PyTorch, no NumPy, no frameworks. Just the full algorithmic content needed for training and inference: dataset handling, tokenizer, autograd engine, GPT-2-like architecture, Adam optimizer, training loop, and inference loop. The code fits perfectly across three columns and represents a decade-long obsession to simplify LLMs to bare essentials. Run it from a single file, understand every mathematical operation, see exactly how attention works without abstraction layers hiding the mechanics. For anyone who wants to truly understand transformers rather than just use them, this is the definitive resource.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.