

Mistral's Open TTS, Anthropic's Activation Translator, and Matt Pocock's Skills Repo: Tokenizer #28
This week's most valuable resources

Hey there! Anthropic trained a second Claude to read the first Claude’s mind and report back in English. The translator caught the model mid-blackmail-test, noticing this looks like a safety eval. Spooky, useful, oddly humbling. Most of this week points the same way: the action has moved from tuning the model to disciplining the agents we build on top.
New here?
The Tokenizer is my weekly resource roundup. I curate AI/ML papers, videos, articles, tools, and learning resources worth your time. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Train a 120B beast on one H200 by parking weights in host RAM. One video model that covers every input type, no more one-model-per-modality. Four agents gang up on Anthropic’s GPU-kernel benchmark and beat it. A self-driving model that thinks without spelling it out, no accuracy hit. A training arena that grows its own environments.
🎥 Videos: Sebastian Raschka rebuilds modern LLMs layer by layer in 53 minutes. Anthropic teaches Claude to narrate Claude. Samuel Humeau makes the case that today’s TTS is basically an LLM with audio tokens. Dave Ebbelaar builds agentic RAG out of three tool primitives.
📰 Reads: OpenAI killed finetuning, and swyx says the rest of us are stuck on “just very long prompts.” Nathan Lambert on why open labs compound their R&D into a real cost advantage. Paul Iusztin’s six-agent Claude Code rig, spec to merged PR with two human gates.
🛠 Tools: Semantic code search as an MCP plugin for any coding agent. StepFun’s open audio reasoner that gave up on auto-scoring because the high scores were lying.
🎓 Learning: Matt Pocock open-sourced his personal `.claude` directory. Read it like a curriculum.
📄 5 Papers
1. MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
https://arxiv.org/abs/2604.05091 | GitHub
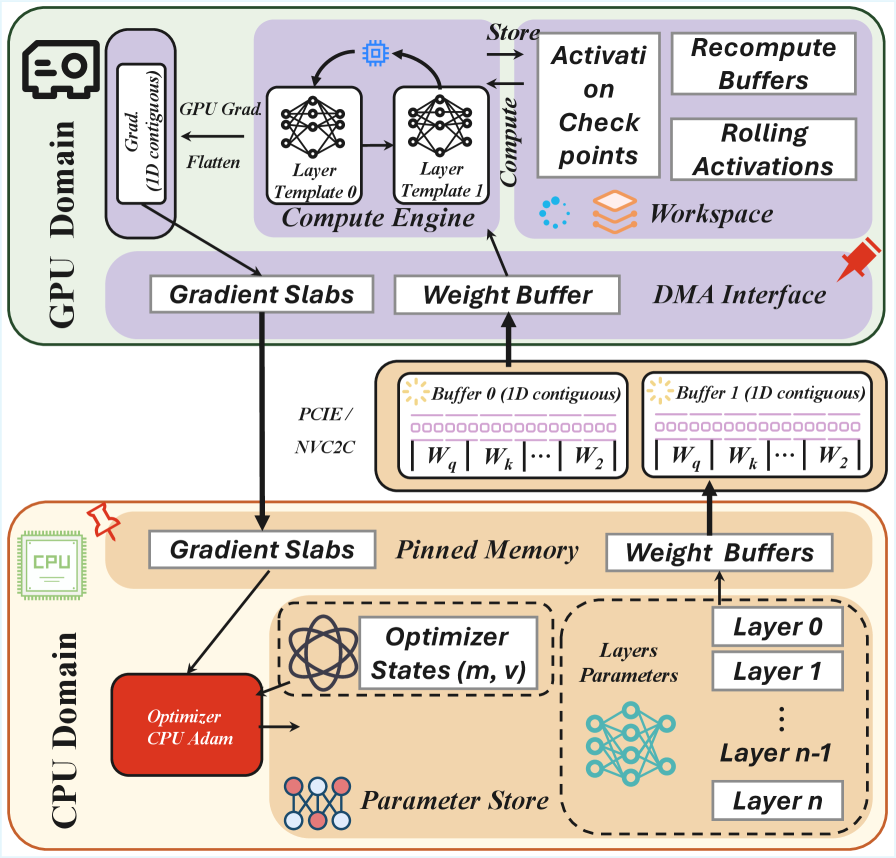
Train a 120B model on one H200. The authors park parameters and optimizer state in 1.5TB of host RAM, then stream them to the GPU layer by layer with a double-buffered handoff. At 14B they clock 1.84x faster than DeepSpeed ZeRO-3 with CPU offloading. One catch: if prefetch can’t keep up with compute, PCIe becomes the bottleneck.
2. UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors
https://arxiv.org/abs/2605.00658 | GitHub

Most video diffusion models are one-trick: one for plain video, another for video plus depth, another for video plus transparency. UniVidX is a single backbone that learns all of them. HKUST MMLab trained two flavors on under 1,000 videos each: video plus scene geometry, and video plus transparency. Both held their own against the specialists. They only tried two combinations, though. Whether the trick generalizes is still open.
3. CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
https://arxiv.org/abs/2604.01658 | GitHub
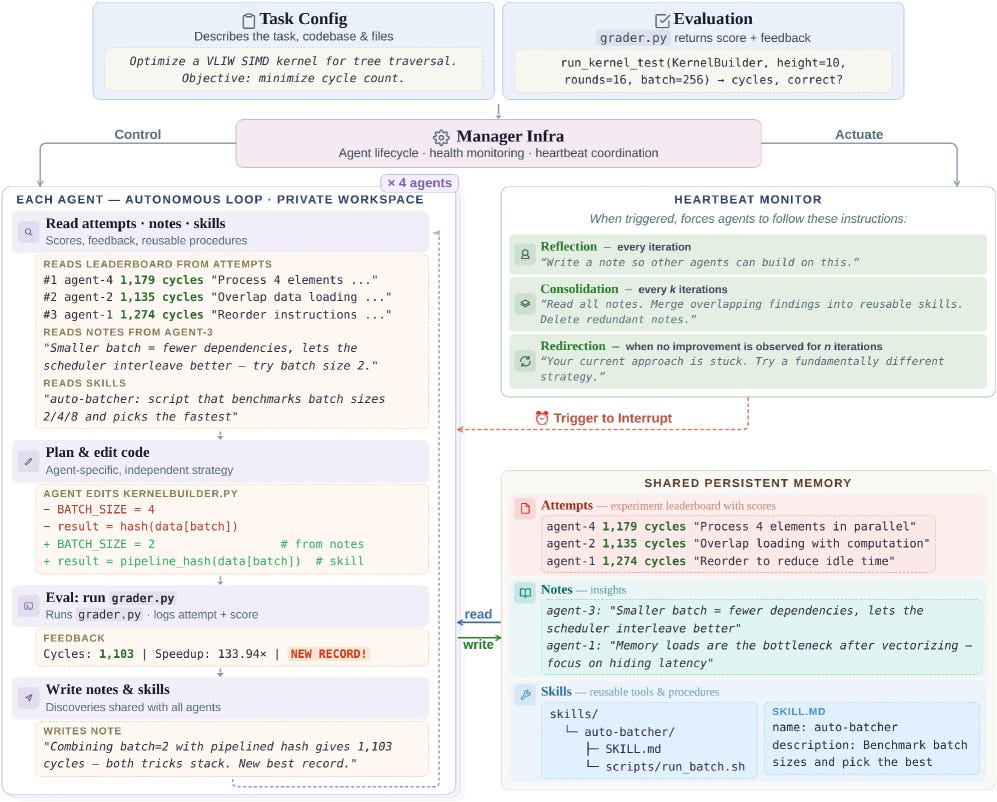
Four LLM agents work in their own sandboxes. They take turns proposing solutions, critiquing each other’s work, and keeping what holds up in a shared memory. No fixed playbook tells them what to try next; the agents riff on each other’s ideas. On Anthropic’s GPU-kernel benchmark they cut the work from 1363 to 1103 cycles. Across 10 tasks in math, algorithms, and systems, they run 3 to 10x faster than fixed evolutionary baselines.
4. Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
https://arxiv.org/abs/2604.18486 | GitHub
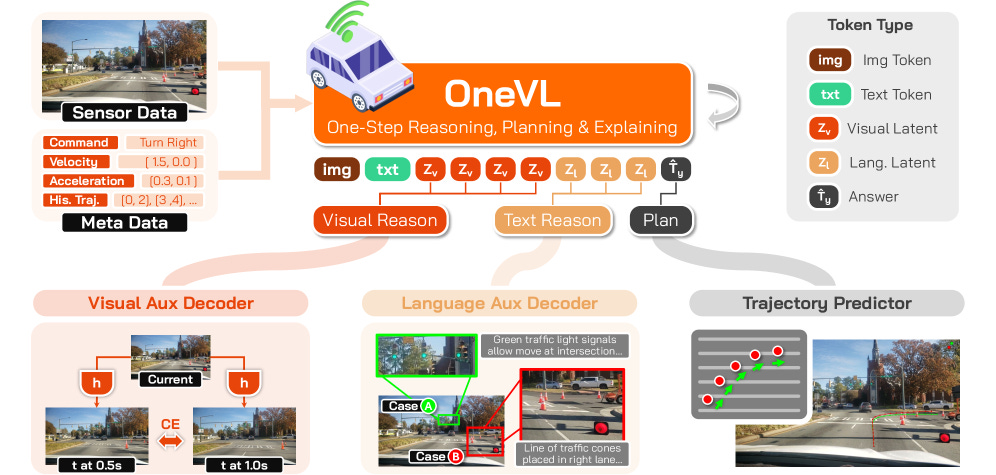
Chain-of-thought is too slow for self-driving. The model can’t write out its reasoning step by step in real time. So the authors compress that reasoning into a handful of hidden internal values the model processes in one shot, instead of one word at a time. Across four driving benchmarks, it’s the first compressed approach to match the speed of skipping reasoning entirely, without losing accuracy. The price: a three-stage training pipeline over trajectory, language, and vision objectives.
5. Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
https://arxiv.org/abs/2604.18292
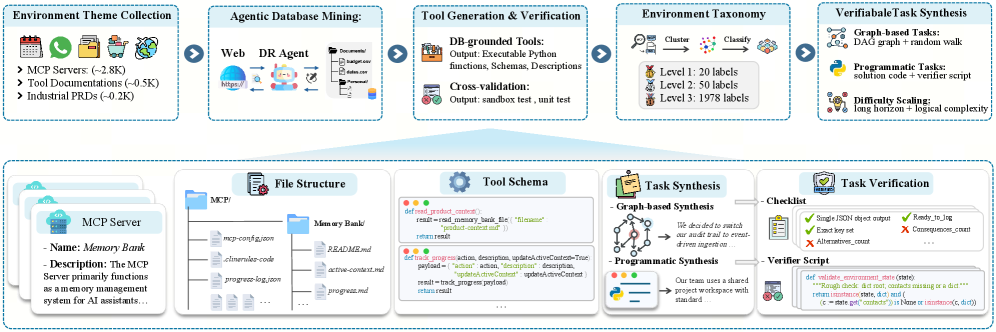
Most agent training uses a fixed task set. Agent-World grows the set on the fly: new tasks come from topic-specific knowledge bases, the agent gets realistic MCP-style tools, and they aim reinforcement learning at whatever the agent currently fails at. Tasks are “verifiable,” meaning a checker can score them automatically without a human in the loop. Their 8B and 14B models beat strong commercial baselines across 23 agent benchmarks. The abstract doesn’t say by how much. Only a project page is live so far. File under promising, show me the receipts.
🎥 4 Videos
1. Sebastian Raschka on What He Learned From Implementing Modern LLM Architectures From Scratch
Port open-weight LLMs into your own Python from scratch in 53 minutes. The trick: load HuggingFace weights, then verify layer by layer against the HF Transformers reference using random weights on a small block. Mismatches surface before you’ve wired the whole stack. Sebastian Raschka shows that recent architectures mostly differ in attention variants and sizing, driven by the rising memory cost of longer reasoning and agent traces. He closes with a beginner-to-expert roadmap of open-source projects.
2. Anthropic on Translating Claude’s Internal Activations Into English
A second Claude reads the first Claude’s mid-layer activations and emits English. Anthropic verifies fidelity by translating that English back into numbers and matching the original. In a simulated blackmail scenario, the translator catches Claude noticing the obvious: this looks like a safety evaluation.
3. Samuel Humeau (Mistral) on Why TTS Models Now Look Like LLMs
Modern TTS works like an autoregressive LLM, just predicting audio tokens instead of words. Samuel Humeau (Mistral) walks through why in 22 minutes. Audio tokenizes at 80ms frames, 12 per second, roughly 500 tokens per second of speech, against about 15 bits per second of actual semantic content. (Brutal ratio.) He demos the streaming trick with a small voice agent: emit packets before computation finishes. Mistral’s open release ships the decoder and voices, but no cloning encoder.
4. Dave Ebbelaar on Building Agentic RAG From Scratch in Pure Python
Dave Ebbelaar wires three simple tools and plain Python into an agent that searches its own knowledge base. In 27 minutes, he shows where the simpler approach still wins (fetch the relevant chunks once, answer), and where letting the agent run multi-step searches is worth it.
📰 3 Curated Reads
1. The End of Finetuning

OpenAI killing its finetuning APIs ends finetuning for the modal 80% of AI engineering. swyx ties this to OpenAI’s broader 2026 pullback (Sora cut, Anthropic about to pass them in valuation), while Cursor and Cognition, fresh off a $25B round, lean harder on reinforcement learning over open models. He traces the call back to Jeremy Howard on the Latent Space pod, October 2023. The middle of the market gets “Just Very Long Prompts.” Said with affection, presumably.
2. How Open Model Ecosystems Compound

Roughly 80% of frontier-model compute goes to R&D, not the final training run. Nathan Lambert grounds that figure in Ai2’s Olmo 3 writeup and an Epoch AI cost analysis. He argues China’s open peer-sharing turns this into a structural cost advantage: their labs can build longer than outsiders expect. He also draws a clean line between “open AI” and open-source software. Open AI is about sharing risky R&D, not ready-to-deploy code.
3. From Vibe Coding to a Real Engineering Team

Six Claude Code agents with one rule: no agent both writes code and judges it. Paul Iusztin’s roster: a PM-architect on ADRs, a TDD engineer in raw shell, an adversarial tester, a diff-only PR reviewer, and a CI-watching on-call agent. The raw-shell choice is deliberate: LLMs have seen far more bash code than MCP wrappers during training. The `/night` orchestrator runs spec to merged PR with two human gates.
🛠 2 Tools & Repos
1. zilliztech/claude-context
https://github.com/zilliztech/claude-context
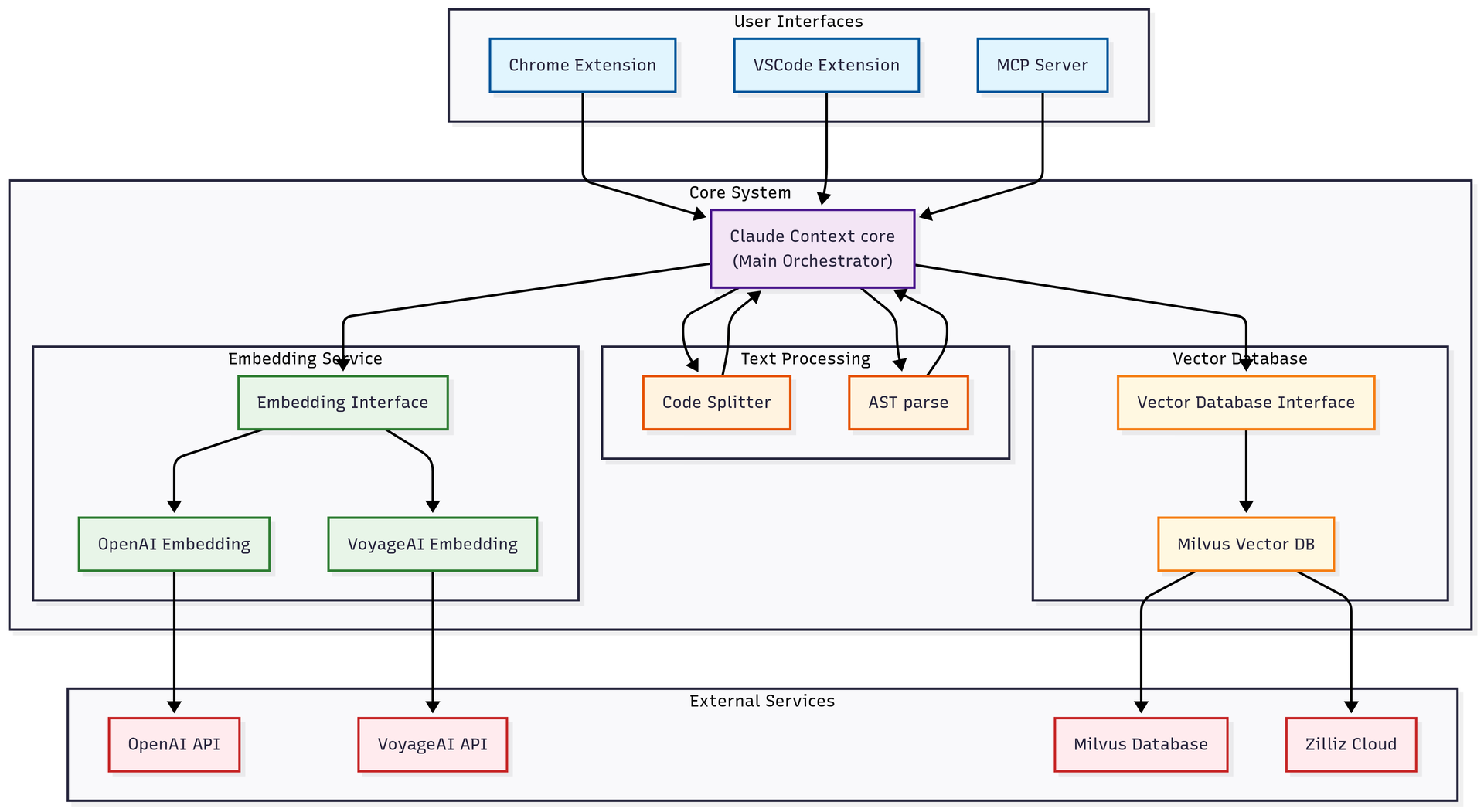
Semantic code search as an MCP plugin for most major coding agents. It indexes your codebase into Zilliz Cloud or self-hosted Milvus, then serves targeted retrievals back into the agent’s context. One `npx` install, an OpenAI key for embeddings, a Milvus endpoint. Zilliz built it, so yes, it funnels you toward their hosted vector DB.
2. stepfun-ai/Step-Audio-R1
https://github.com/stepfun-ai/Step-Audio-R1
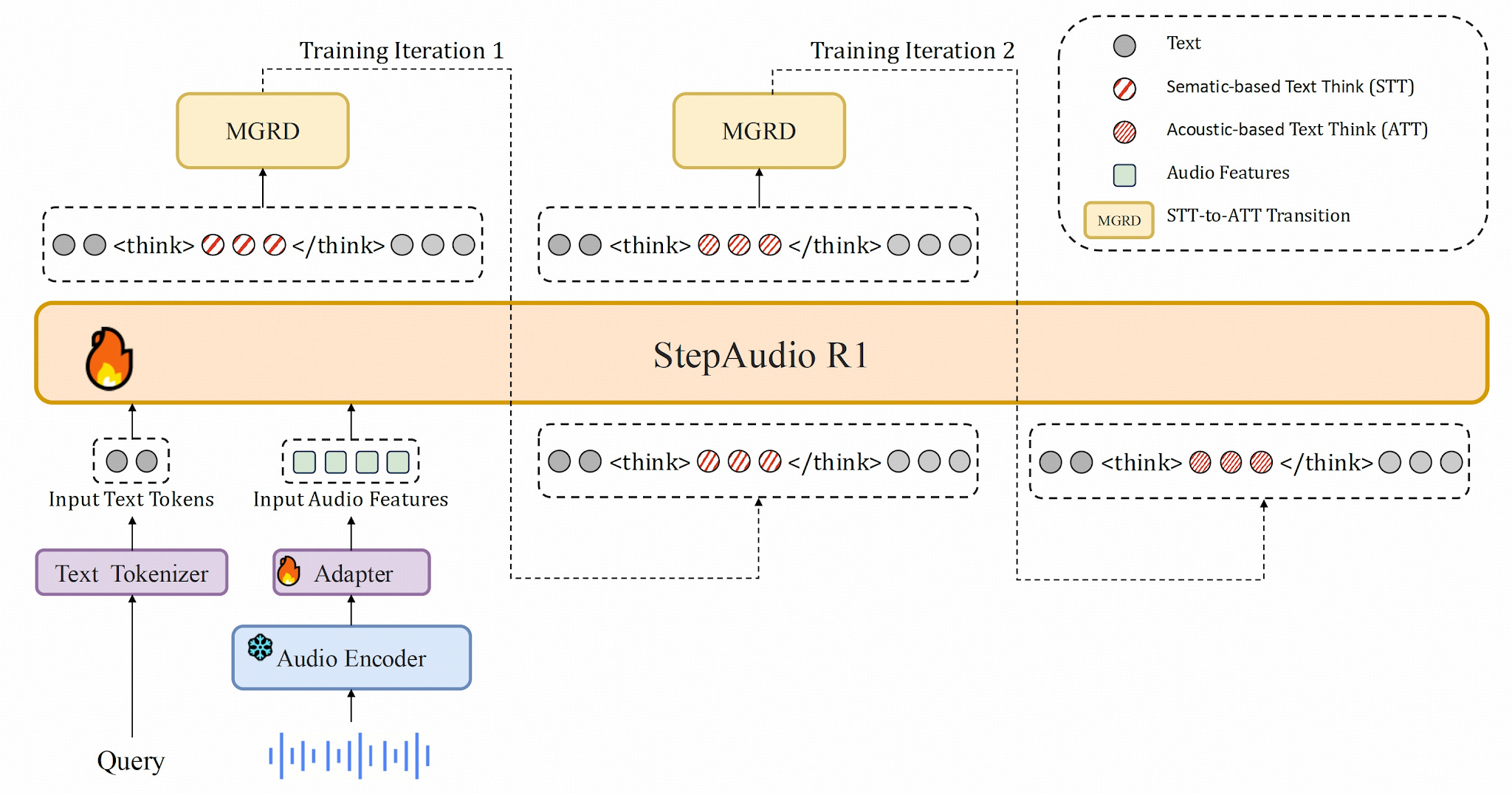
StepFun shipped an open audio reasoner. R1.5 dropped automated metrics in favor of human feedback (RLHF). The reason: scoring high on the objective tests didn’t make the model sound natural in conversation. The repo ships vLLM inference, weights for R1 and R1.1, a Gradio demo, and three new evaluation benchmarks. Apache-2.0. Watch the Humeau video above first. Step-Audio-R1 is what that direction looks like with weights you can run today.
🎓 1 Pick of the Week
mattpocock/skills
https://github.com/mattpocock/skills
Matt Pocock open-sourced his personal `.claude` directory as a runnable skills repo. Headliners: `tdd`, `diagnose`, `grill-me` (relentless interview before coding), `caveman` (~75% token compression), `handoff` (conversation compaction). Install with `npx skills@latest add mattpocock/skills`. Each skill reads like a short essay on the engineering principle behind it.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.