



One of The Best Ways to Improve Your Machine Learning Skills:
Let me tell you a secret:

Let me tell you a secret:
The single most effective habit that helped accelerate my learning wasn’t just reading papers, books, or watching lectures.
It was actively studying others’ code.
I ran code reviews of other repositories. This allowed me to learn how various algorithms were implemented and pick up best practices to use in my own work. This is how I did it (and so can you!):
Step 1: Implement the Algorithm Yourself
Before jumping in to see how someone else has implemented a model or an algorithm, do it yourself first. It doesn’t need to be perfect. Just write out how you think the algorithm works and test it.
Average case: It works. Best Case: It fails.

Why is that the best case? You will be more open to learning from another repository. If you’re anything like I was, the moment something worked, I’d immediately close my mind to exploring how it could be done better. It wasn’t until much later that I changed my perspective on how writing good code is an endless process.
Step 2: Find Good (and Bad) Examples of the Algorithm
There are a million repositories on GitHub that implement the same thing. How do you find out which ones to learn from? There are 3 simple options I choose from:
Option 1: Use the Official Implementation
In machine learning, often times the algorithm you implement comes from a paper. That naturally means that there is a high chance that the code for the paper was released along with it.
Start there.
You can learn how the authors implemented various parts of the algorithm straight from the source.
Option 2: Look up the Algorithm on Papers With Code
If you can’t find an “official” implementation, the next best bet (and in fact, this should be option 1) is to look at Papers With Code.
This site has a huge collection of papers with various repositories that implement them. For example, if you were looking for the code for the first Vision Transformer, you’d see something like this:
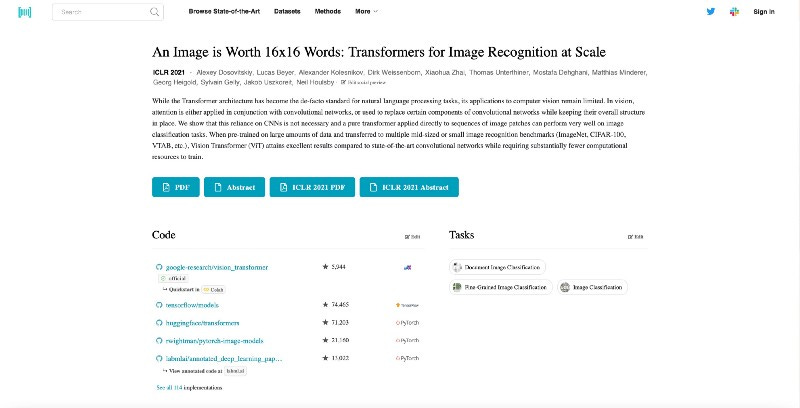
In addition to the paper, you can see the top-ranked repositories that implement this paper.
Option 3: Use the Number of Stars as a Guide
If the authors didn’t release the code (boo!), and you can’t find it on Papers with Code, then the next best bet is to search with the phrase “INSERT NAME OF ALGORITHM HERE GitHub”. Then, use the number of stars the repository has as a guide to choose a starting point. Usually, a repository with a higher number of stars ( > 1000) is a safe option to learn from.
This isn’t a hard and fast rule though.
There are many hidden gems out there that just haven’t gotten the eyeballs on them yet.
Step 3: Learn from the Contrast
You now have the repository (or repositories) you’d like to learn from. The next step is to learn the differences in implementation. Crucially, just focus on the core implementation first.
For example, if you are trying to learn a new model architecture, focus on just the part of the code that implements the architecture.
With the paper at your side, see how each part has been implemented by this repository and contrast it to how you’ve implemented it. This isn’t to say that what you have done is wrong. Rather, observe the contrast in styles, usage of idiomatic code, brevity, and clarity.
Next, take notes on things you don’t understand on the first attempt. Why did they implement it this way? What is this new syntax they’ve used? How are they accounting for X? These are all great questions to think through.
One of my favorite repositories that implement the vision transformer is by Phil Wang. In the image below, look at the highlighted line. When I first came across it, I had no idea what that syntax was. Turns out, it’s something called Einstein Summation, or einsum for short. It’s a super efficient way to manipulate tensors.
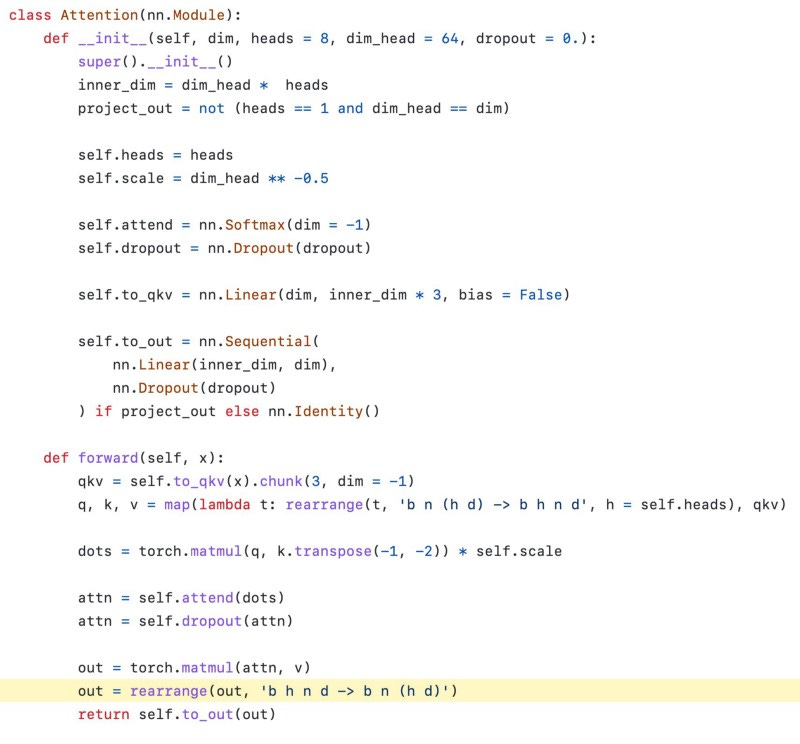
Now, I use this when relevant in my implementations. This is just one of the many things you can do when studying a new repository.
Not All Repositories are Created Equal
Repeat after me. “It’s ok to study poor code”. 🧐
While this might surprise you, look at what a legendary author says about the same thing in another domain:
“Every book you pick up has its own lesson or lessons, and quite often the bad books have more to teach than the good ones.” ~ Stephen King
You can learn a lot from poorly written code. It tells you exactly what not to do, why not to do it, and how not to do it. Bad code helps you clearly identify the pitfalls to avoid and how you can save hours if not days by writing good code in the first place.
Step 4: Expand Your Toolbox
You’ve now done all the hard work of studying and analyzing a set of good and bad implementations. But your job isn’t done. The last step of the process is perhaps the most important.
Reflect on your notes and your learning. Augment your toolbox. In particular:
What are the techniques I can use going forward?
How can I make my implementation more readable and clear?
What are the things I should avoid when implementing this?
The next time you implement something, try to incorporate some of these learnings and see how they work in action.
TL;DR
Implement it yourself
Find Good (and Bad) Implementations to study
Learn from the Contrast
Expand Your Toolbox
I’d love to hear about your experience after trying this idea out.
🤖💪 Want more ideas to be a productive ML practitioner?
Each week, I send out a newsletter with practical tips and resources to level up as a machine learning practitioner. Join here for free →