

OpenAI's Agent RL Secrets, Learn RAG From Scratch, and How 1% Fake Data Replaces 28% of ImageNet: The Tokenizer Edition #12
This week's most valuable AI resources

Hey there! Remember when everyone said adding more agents would solve everything? Turns out they make systems 17x worse at propagating errors. Meanwhile, researchers are training vision models on data that literally isn’t images (and it works better than you’d think), and Nathan Lambert finally pulled back the curtain on how AI2 actually built a competitive reasoning model. The gap between what works in demos versus production keeps getting more interesting.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Teacher-free parallel reasoning with 4.6x speedups, self-supervised 3D vision that surpasses supervised baselines, quantitative scaling principles for agent architectures, procedural pretraining that replaces 28% of ImageNet data, and evidence that neural networks converge to universal weight subspaces
🎥 Videos: Nathan Lambert’s complete walkthrough of building OLMo 3 Think, OpenAI’s reinforcement fine-tuning approach for agents, comprehensive RAG from scratch, and an entire JAX AI stack masterclass
📰 Reads: Waymo’s approach to demonstrably safe autonomous driving, continuous batching for LLM serving, and choosing the right GPUs for your AI workloads
🛠 Tools: Made with ML’s production-grade machine learning course and a comprehensive AI engineering toolkit
🎓 Learning: Stanford’s updated deep reinforcement learning course with fresh 2025 content
Grab my first book — AI for the Rest of Us — today!
Quick note: If you find the book useful, please leave a review on Amazon. It makes a world of difference. If you have a picture of the book IRL, please share it with me. I really appreciate it.
📄 5 Papers
Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
https://arxiv.org/abs/2512.07461 | GitHub
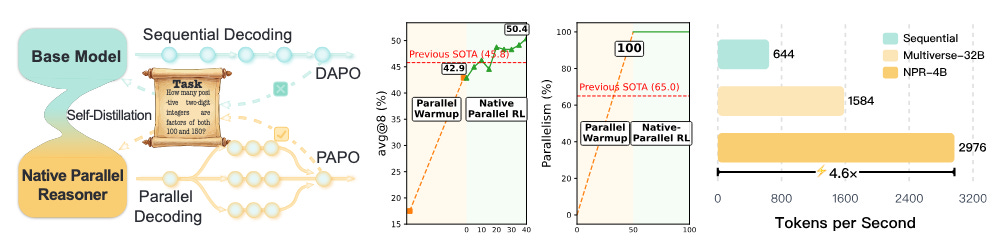
Models that reason sequentially hit performance ceilings because early mistakes lock them into suboptimal paths. Native Parallel Reasoner teaches Qwen3-4B to explore multiple reasoning branches simultaneously without relying on teacher models. The system achieves performance gains up to 24.5% and inference speedups up to 4.6x across eight reasoning benchmarks through a self-distilled training pipeline that learns adaptive decomposition directly from experience. Unlike previous approaches that fall back to sequential generation when things get complex, NPR demonstrates 100% genuine parallel execution, establishing that models can learn to think in parallel rather than just simulating it.
E-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
https://arxiv.org/abs/2512.10950 | GitHub
Self-supervised learning transformed language models and 2D vision, but 3D understanding from multi-view images remained largely supervised. E-RayZer changes this by learning truly 3D-aware representations from unlabeled images, operating directly in 3D space with explicit Gaussian splatting rather than inferring 3D indirectly through view synthesis. The approach matches or surpasses fully supervised reconstruction models while significantly outperforming leading visual pre-training methods like DINOv3 and VideoMAE V2 on 3D downstream tasks. The key breakthrough is a fine-grained learning curriculum that organizes training from high-overlap views to general 3D understanding, solving the convergence challenges that plagued previous explicit 3D approaches.
Towards a Science of Scaling Agent Systems
https://arxiv.org/abs/2512.08296
Adding more agents to a system often makes it worse, not better. This research derives quantitative scaling principles by evaluating 180 configurations across four benchmarks using five canonical architectures. The findings are sobering: independent agents amplify errors 17.2x through unchecked propagation, tool-heavy tasks suffer disproportionately from multi-agent overhead, and coordination yields diminishing returns once single-agent baselines exceed 45% success rates. The derived predictive model correctly identifies optimal coordination strategies for 87% of held-out configurations, turning agent architecture from guesswork into engineering. The lesson is clear: measure coordination efficiency, overhead, error amplification, and redundancy rather than assuming more agents equals better performance.
Can You Learn to See Without Images? Procedural Warm-Up for Vision Transformers
https://arxiv.org/abs/2511.13945
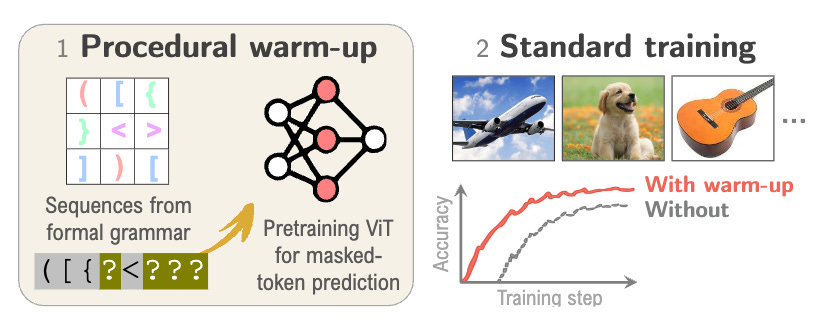
Vision transformers can learn useful representations from data that isn’t visual at all. This research generates procedural data using formal grammars with zero semantic content, then uses it to pretrain vision transformers before standard image training. Allocating just 1% of the training budget to this procedural warm-up improves ImageNet-1k accuracy by 1.7%, equivalent to replacing 28% of the actual image data. The benefits arise from structured dependencies that help transformers internalize abstract computational priors rather than visual patterns. Unlike existing structured initializations that only affect attention weights, procedural warm-up acts on both attention and MLP layers, primarily in later layers where standard visual pretraining typically has minimal impact.
The Universal Weight Subspace Hypothesis
https://arxiv.org/abs/2512.05117
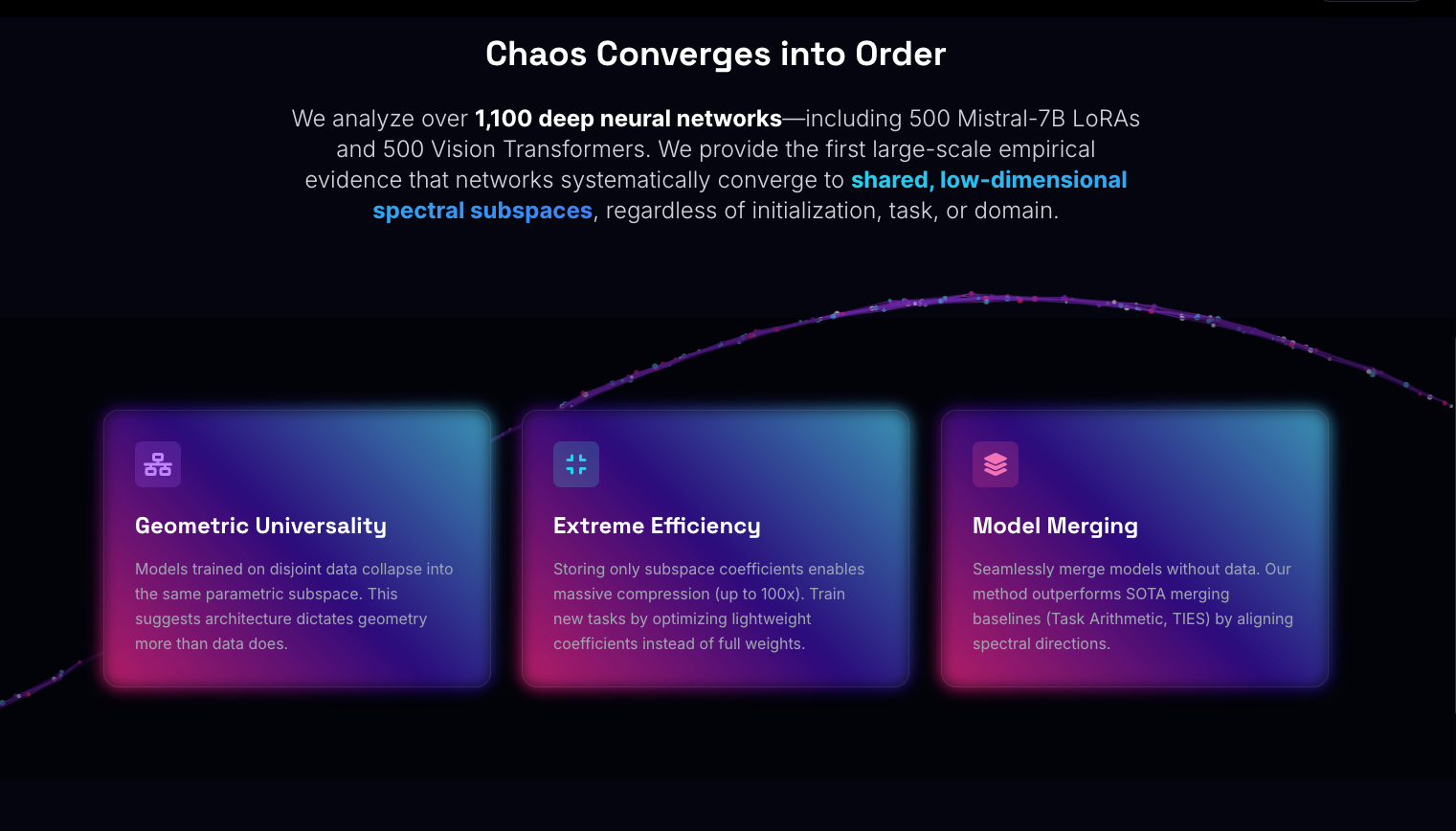
Neural networks trained on completely different tasks converge to remarkably similar low-dimensional parameter subspaces. Analysis of over 1,100 models including 500 Mistral-7B LoRAs, 500 Vision Transformers, and 50 LLaMA-8B models reveals that majority variance concentrates in just a few principal directions regardless of initialization, task, or domain. This finding explains why parameter-efficient fine-tuning works so well and enables massive model compression up to 100x. New tasks can be learned by optimizing scalar coefficients in the universal subspace rather than full weight matrices, suggesting that the vast majority of parameters in fine-tuned models are redundant. The implications for model reusability, multi-task learning, and training efficiency could fundamentally change how we approach large-scale neural networks.
🎥 4 Videos
How We Built a Leading Reasoning Model (OLMo 3)
Nathan Lambert walks through every stage of building OLMo 3 Think, from pretraining through reinforcement learning infrastructure and evaluation. This isn’t a high-level overview but a detailed technical breakdown of the decisions, trade-offs, and engineering challenges involved in creating competitive reasoning models. The talk focuses heavily on RL infrastructure and evaluating reasoning capabilities, providing insights into how leading labs actually iterate on model training versus what appears in published papers. If you want to understand the gap between research papers and production reasoning models, this comprehensive walkthrough fills that void.
Agent Reinforcement Fine Tuning
OpenAI’s approach to reinforcement fine-tuning for code models, explained in depth. The video covers how to structure RL training for agent behaviors, balancing exploration with task completion, and the specific challenges that arise when models need to use tools and environments rather than just generate text. Particularly valuable for understanding how frontier labs think about agent training beyond standard language modeling objectives.
Learn RAG From Scratch
A LangChain software engineer teaches you to implement RAG from scratch using Python. This isn’t about using abstractions but understanding the mechanics: how retrieval actually works, why embeddings matter, when to chunk documents, and how to combine retrieved context with LLM generation. The course covers practical patterns you’ll need when building production systems that augment language models with custom knowledge.
Mastering the JAX AI Stack
https://youtube.com/playlist?list=PLOU2XLYxmsIJBcjiFi8LdyY5YGR8sz0ZZ
Comprehensive guide to the JAX ecosystem centered on the Flax NNX library. The playlist takes you through JAX’s functional transformations, debugging techniques, scaling across distributed hardware with SPMD, optimization with Optax, checkpointing with Orbax, efficient data loading with Grain, and model serving with vLLM. Designed to bridge the gap for those familiar with PyTorch and NumPy, this provides everything you need to tackle advanced computational challenges with JAX at scale.
📰 3 Curated Reads
Demonstrably Safe AI For Autonomous Driving
https://waymo.com/blog/2025/12/demonstrably-safe-ai-for-autonomous-driving
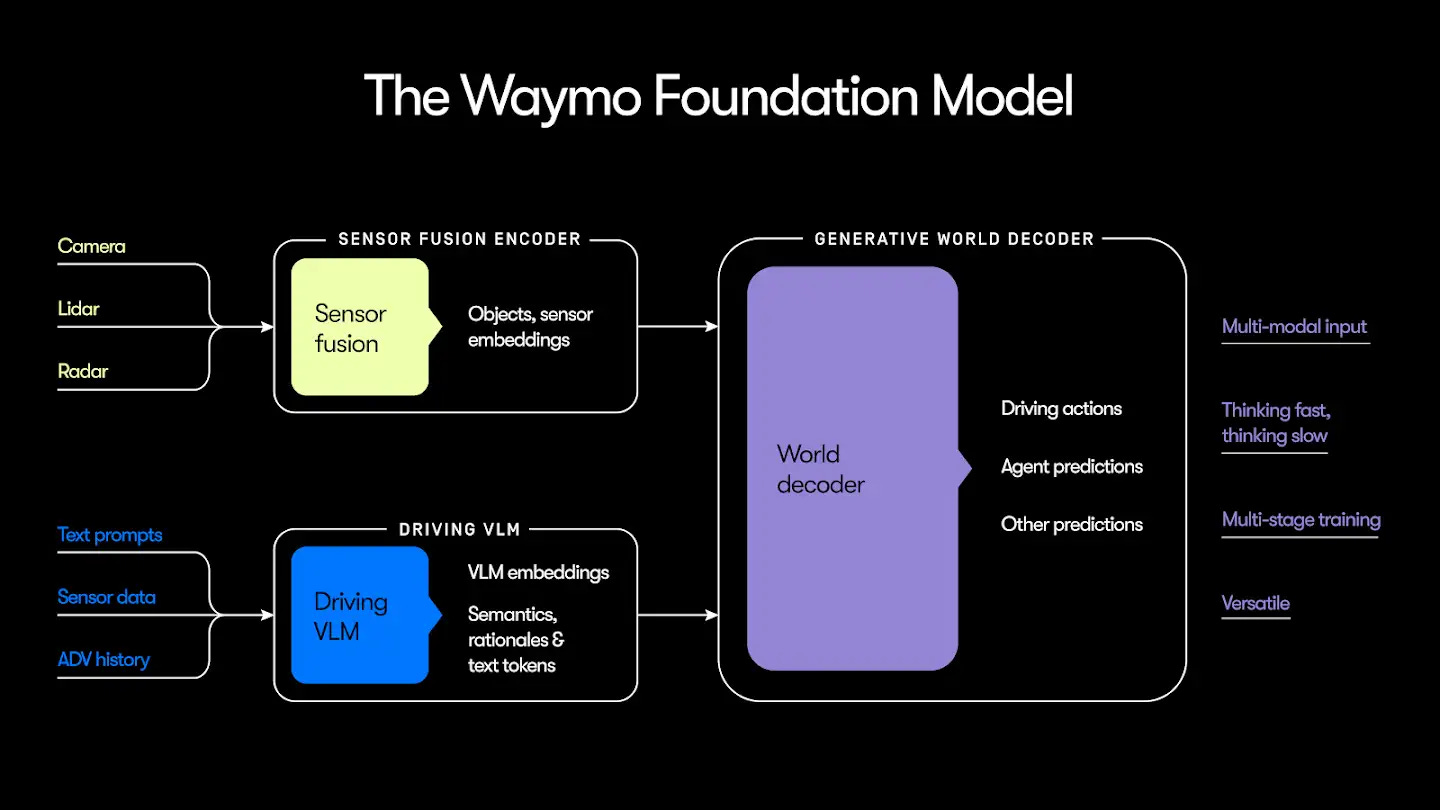
Waymo explains their approach to building AI systems that can be verified safe rather than just empirically tested. The piece covers how they structure safety cases, validate behavior in edge cases, and maintain safety guarantees as models evolve. Particularly relevant as AI systems take on higher-stakes applications where failures have real consequences beyond incorrect text generation.
Continuous Batching
https://huggingface.co/blog/continuous_batching

Traditional batching waits for all sequences in a batch to finish before processing new requests. Continuous batching processes sequences at the token level, adding new requests as soon as existing ones complete. This dramatically improves throughput and reduces latency for LLM serving. HuggingFace’s breakdown explains why this matters for production deployments and how to implement it effectively with modern serving frameworks.
An Engineer’s Guide to Choosing GPUs

Alex Razvant provides practical guidance on selecting GPUs for AI workloads. The analysis goes beyond spec sheets to explain how memory bandwidth, compute capabilities, and interconnect topology actually affect training and inference performance. Covers trade-offs between consumer and data center GPUs, when to prioritize memory over compute, and how to evaluate cost-effectiveness for specific use cases.
🛠 2 Tools & Repos
Made with ML
https://github.com/GokuMohandas/Made-With-ML

Goku Mohandas built a complete production machine learning course covering everything from experiment tracking and data versioning through deployment and monitoring. The repository provides working code for MLOps patterns you’ll actually use: CI/CD for models, feature stores, model registries, and production monitoring. Designed for practitioners who need to move models from notebooks to reliable systems that serve real users.
AI Engineering Toolkit
https://github.com/Sumanth077/ai-engineering-toolkit

Comprehensive collection of resources and tools for AI engineering, organized by use case. Instead of overwhelming you with every possible library, this toolkit focuses on battle-tested tools for specific problems: prompt engineering, vector databases, model deployment, evaluation frameworks, and monitoring solutions. Helpful for navigating the rapidly evolving ecosystem and finding tools that solve your specific engineering challenges.
🎓 1 Pick of the Week
Stanford’s Deep Reinforcement Learning
https://youtube.com/playlist?list=PLoROMvodv4rPwxE0ONYRa_itZFdaKCylL
Stanford updated their deep RL course for 2025, covering policy gradients, actor-critic methods, model-based RL, and advanced topics like offline RL and multi-agent systems. The lectures balance theoretical foundations with practical implementation details, explaining not just how algorithms work but when to use them and why they fail. Essential viewing if you’re working with RL for agents, robotics, or any sequential decision-making problem where you need to understand the fundamentals rather than just applying libraries.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.