

"Practically" building an image classifier - Episode I
Based on a true story 😉

This Week on Gradient Ascent:
Building an image classifier - The practical way 🤖
Your weekly machine learning doodle 🎨
[Check out] Pytorch reborn 🔥
[Be inspired by] ChatGPT can do what now? 🔤
[Consider reading] CLIP just got replaced 🖼️
"Practically" building an image classifier - Part I:
Most practitioners first learn deep learning through the lens of image classification. If you've taken a programming course, then consider this to be the equivalent of the "hello world" exercise they give you at the start. While many experts say image classification is solved (and there may be some truth in that), there's a lot of nuance and craft you can learn from this type of problem. With that being said, over the next couple of editions, I'll share how I build, evaluate and analyze these models through the form of a story. Initially, I considered consolidating everything into a single article. But to spare you from reading my response to Tolstoy's "War and peace", I've broken it down into pieces. Note: All the code used in these posts can be found here.
So you think you can classify?
To motivate this problem, let's consider that you've been hired as a Computer Vision (CV) engineer at Petpoo Inc, a pet shampoo company. Now you can ask me why in the world would a pet shampoo company need a CV engineer. Even more importantly, why for all the gold on earth would they call themselves Petpoo? I will answer the first question below, but I honestly don't know the answer to the second.
On your first day, your manager meets you and walks you through your project.
"Hi INSERT_YOUR_NAME_HERE! We're thrilled to have you here. Petpoo is scaling up and one of the most requested features from our customers is custom shampoo recommendations for their pets. Our customers are social media savvy and want their petfluencers to have the best perm in reels and selfies that they share. They also don't have time to fill out lengthy questionnaires because they're busy teaching their pawed companions the perfect duck face. So we're building a solution to recognize pets based on their pictures. Once we know what kind of breed a pet is, we can recommend custom shampoos from our product lines that will make the pet and its owner happy.
Since a majority of our customers have cats or dogs, we'd like you to build the image classifier to recognize if a pet is a cat or a dog. For starters, let's keep it at this level. Based on the traction we receive after launch, we can add more features to the solution. Good luck, we're all counting on you."
You ask, "What data do we have for prototyping?".
"Good question. You can start with this dataset", he replies.
"How are we going to evaluate performance?", you question.
"For the prototype, use your best judgment.", he responds and marches off.
Ok, so you need to build an image classifier to distinguish between cats and dogs. You have a dataset to start with and have to figure out how to evaluate the prototype.
You decide to look at the data first. After all, if the data is bad, no amount of machine learning shampoo can save it.
At first glance, this looks like properly processed data that you can start playing with right away. There are nearly 7500 images in total, so that should be sufficient for fine-tuning. The dataset has classification labels for specific pet breeds so you'll need to modify it so that each image is associated with a cat or dog label instead. Ok, a simple function to do that and we're all set.

So a cat image will have the label “True” while a dog image will have the label “False”.
Before starting your experiments, you split the data into training and validation sets. You're smart enough to know that simplicity is always better than sophistication. So, as a first step, you take a well known deep learning model, a ResNet-18 as a baseline. You then turn off all the fancy knobs like schedulers, data augmentation, pretrained weights, and regularization, and pass a batch of data through it. When you check the predictions of the model, you see something like this:
(TensorBase([0.0056, 0.9944]), TensorBase(1.))Good, the probabilities add up to 1. That means that the basic setup is ok. Feeling confident, you train the model for a few epochs and watch what happens. The loss seems to decrease, but for such a simple problem with such a clean dataset, the accuracy is underwhelming.


Wanting to make a good first impression, you visualize the examples that were misclassified and also plot the confusion matrix.
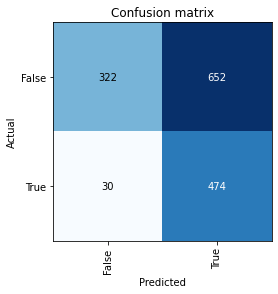

Hmmm, it seems like a whole bunch of dogs are being confused as cats by the model. Strange. Very strange.
You reason that this is because there are insufficient training examples for training from scratch. So you decide to use a technique that has served you well in your career - transfer learning.
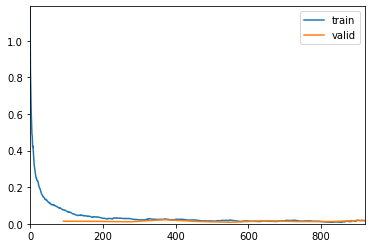
After initializing the Resnet-18 with pretrained weights, you repeat the same experiment, keeping everything else intact. The results from this run look awesome. Almost zero errors and wonderful training curves.

You repeat the same visualization as before and find that only a handful of dogs are being confused with cats.
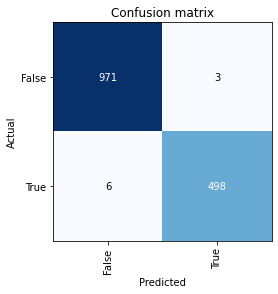

Happy that your new job is off to a good start, you save all your work and go home in the evening.
Later, much later. 1:30 am… You wake up startled as beads of sweat trickle down your forehead.
You've missed a very important detail while setting up the experiment. Accuracy might not be a good metric for this problem at all.
Why?
Stay tuned for part II…
Poorly Drawn Machine Learning:
Learn more about weight initialization here.

Resources To Consider:
Pytorch just got way better
Release Notes: https://pytorch.org/get-started/pytorch-2.0/
One of the big news items this past week was the release of Pytorch 2.0. While stable diffusion and ChatGPT might have caught the headlines, this is no slouch. I'm excited by the backward compatibility support. But there are a whole bunch of updates worth checking out too. I found this thread from Sebastian Raschka really useful in understanding why Pytorch 2.0 will change the game (again).

Building a virtual machine within ChatGPT
Link: https://www.engraved.blog/building-a-virtual-machine-inside/
By now, you would have seen at least one of the many amazing conversations that people have had with ChatGPT. But this is one of the craziest ideas that anyone has tried with this amazing piece of tech, and surprisingly it seems to work. A virtual machine *inside* ChatGPT. Check out the blog post above to learn more.
Faster language image pre-training
Paper: https://arxiv.org/abs/2212.00794
A big limitation of training transformers is the amount of compute and training time required to get them to converge. This gets worse for multi-modal transformers. In this work, researchers propose a way to pretrain image-text transformers faster and more efficiently than prior methods (in particular CLIP). Their work results in nearly a 4x speedup while producing excellent results on downstream tasks. This is an interesting paper to check out if you're working on transformers.