

Running your Life with Claude Code, How OpenAI Uses Codex, and the Anatomy of a Coding Agent - 📚 The Tokenizer Edition #23
This week's most valuable AI resources

Hey there! This week kept circling back to one question: what does it actually take to make agents useful in production, not just in demos? A field engineer at Galileo is now answering every customer question by routing Claude Code across fifteen separate repositories, OpenAI’s Codex team is dogfooding their own tools, and Sebastian Raschka quietly explains why the “harness” around the model matters more than the model itself.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Benchmarks fight back against saturation, with new evaluations for video understanding, autonomous agents, robot policies, and the data behind LLM training.
🎥 Videos: Inside views from Stanford, OpenAI, Galileo, and Databricks on how agents actually run when you put them in front of real engineers (and non-engineers).
📰 Reads: Three sharp takes on coding agent architecture, why your RAG pipeline is overbuilt, and what really decides whether an open model gets adopted.
🛠 Tools: Memory and a Rust-native agent loop, two pieces of the open agent stack worth knowing.
🎓 Learning: A reproducible walkthrough of using Claude Code as a personal operating system, not as a coding tool.
📄 5 Papers
1. Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
https://arxiv.org/abs/2604.05015 | GitHub
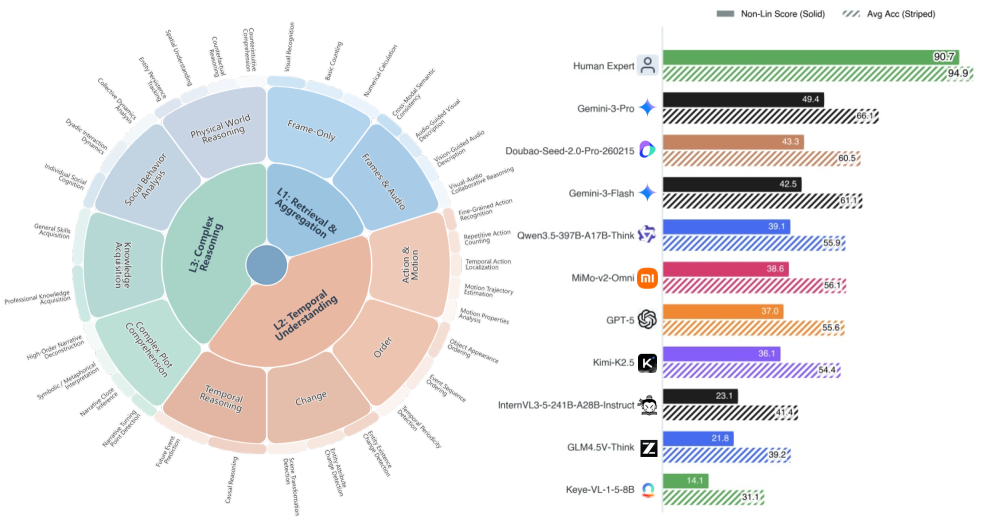
Video benchmarks have saturated to the point where leaderboard scores tell you almost nothing about real model capability. Video-MME-v2 introduces a tri-level hierarchy that escalates from visual aggregation up through temporal reasoning, plus a group-based scoring rule that punishes lucky guesses across linked questions. The team logged about 3,300 human-hours across 12 annotators and 50 reviewers, and one finding stands out: models lean hard on subtitles, and reasoning quality drops sharply when only the pixels are available.
2. DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
https://arxiv.org/abs/2603.26164
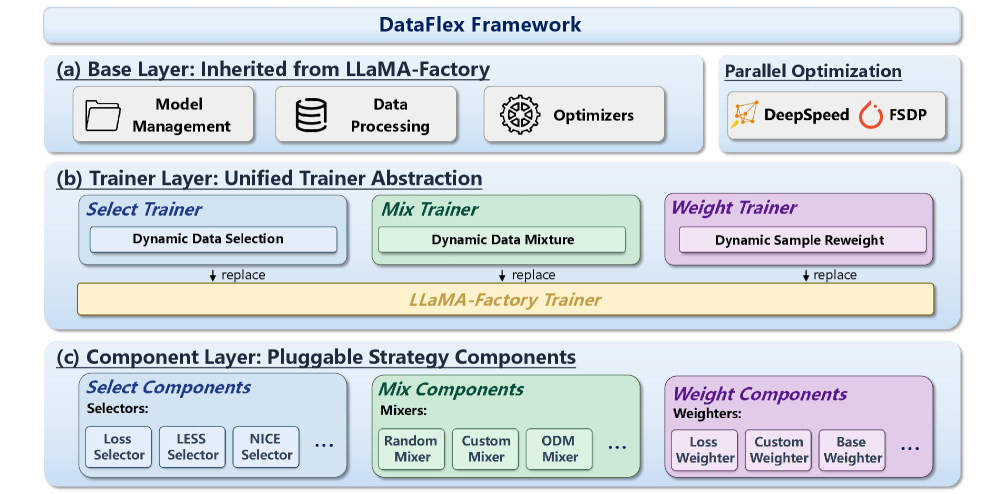
If you’ve ever tried to compare data selection, mixture optimization, and reweighting research, you know each lives in its own incompatible codebase. DataFlex sits on top of LLaMA-Factory and gives you one set of trainer abstractions for sample selection, DoReMi/ODM-style mixture tuning, and reweighting, all DeepSpeed ZeRO-3 compatible. It’s an infrastructure contribution rather than a new method, so the value here is reproducibility and composability across data-centric techniques you already wanted to try.
3. Adam’s Law: Textual Frequency Law on Large Language Models
https://arxiv.org/abs/2604.02176 | GitHub
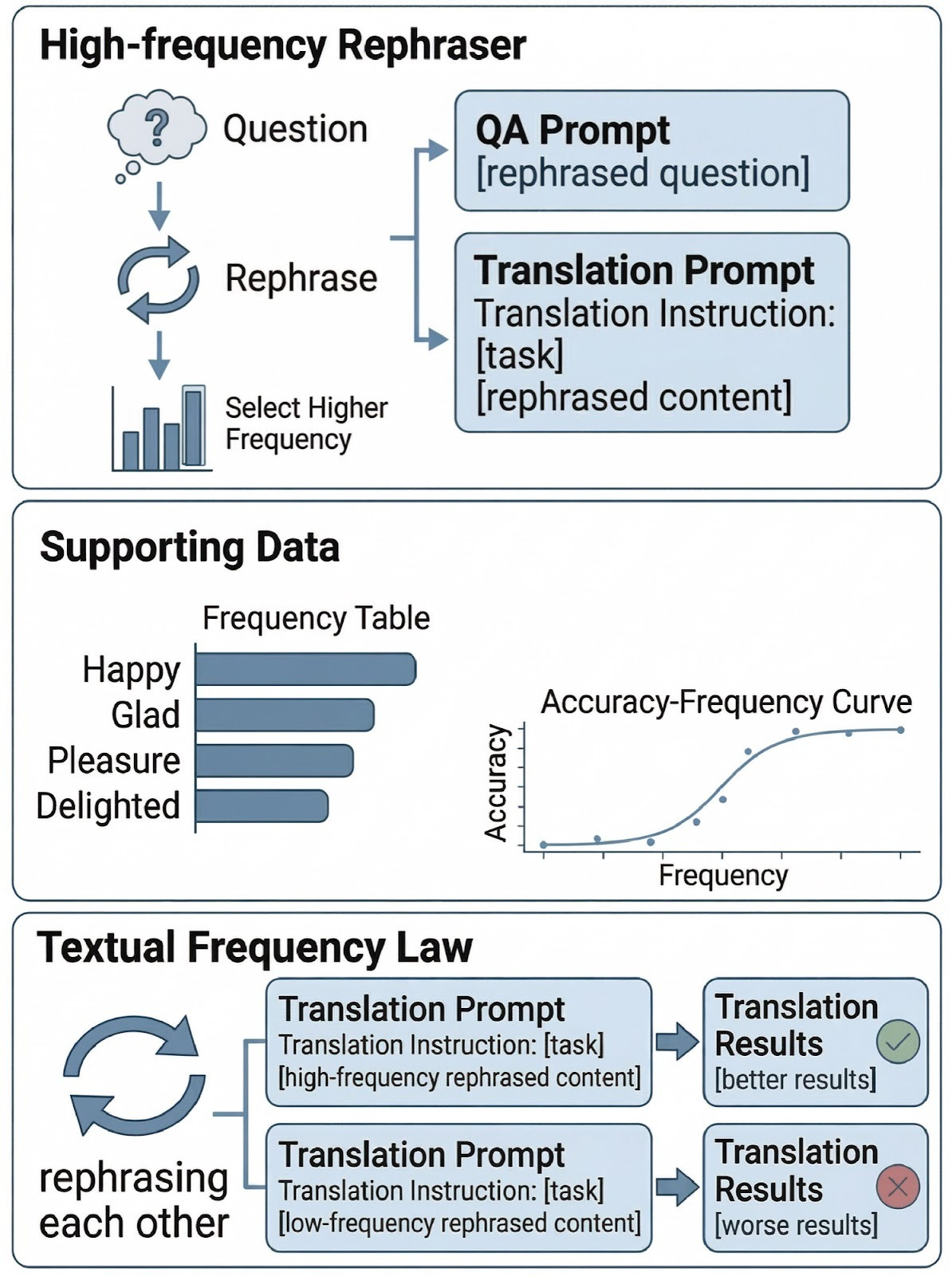
The headline claim sounds tautological (frequent text is better text), but the paper actually proposes a measurement framework with three concrete components: a Textual Frequency Law that estimates sentence-level frequency from open web sources, a distillation step (TFD) that refines that estimate by querying the target model itself, and a curriculum (CTFT) that orders training data from rare to frequent expressions during fine-tuning. Tests cover math reasoning, machine translation, commonsense, and tool calling, which is a wider footprint than the abstract suggests.
4. Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
https://arxiv.org/abs/2604.06132 | GitHub
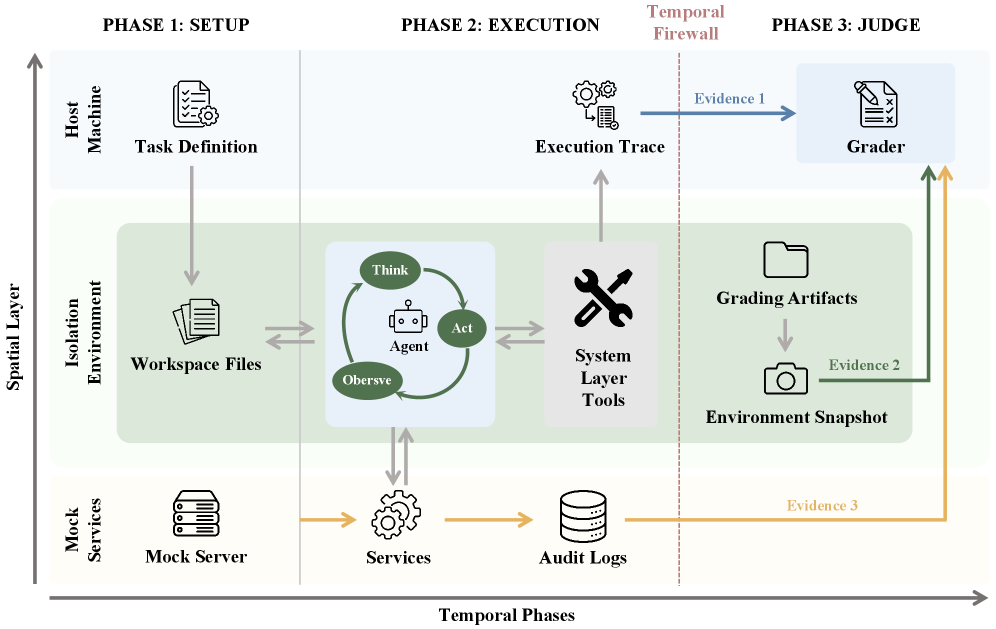
Most agent benchmarks only check the final answer, which means a trajectory full of safety violations can still score a clean pass. Claw-Eval grades the path, not just the destination, with 2,159 fine-grained rubric items across 300 tasks, scored over execution traces, audit logs, and environment snapshots. The headline result is that trajectory-opaque grading misses 44% of safety violations and 13% of robustness failures, which is a hard number to ignore if you’re building agent eval today.
5. LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
https://arxiv.org/abs/2603.28301 | GitHub
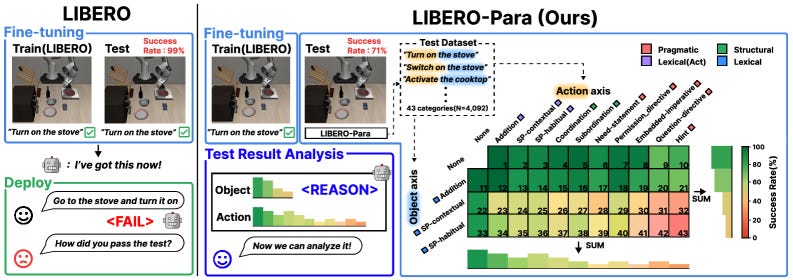
Vision-Language-Action models look impressive until you reword the instruction, and then performance drops 22 to 52 points across the seven configurations tested (0.6B to 7.5B parameters). LIBERO-Para isolates action phrasing from object references so you can see exactly where the model is reading words instead of meaning. The authors trace 80 to 96 percent of failures to the planning stage, not execution, and introduce PRIDE, a metric that quantifies paraphrase difficulty by semantic and syntactic distance.
🎥 4 Videos
1. World Models You Can Actually Interact With: Inside Moonlake
Interactivity changes what a world model has to learn, and that’s the thread Stanford’s Chris Manning and Fan-yun Sun pull on in this Latent Space conversation about Moonlake. The 67-minute episode gets into how the training signal differs from passive video models, and where this approach sits relative to Marble, Cosmos, and the gaming-data world models that have dominated the last quarter. Worth watching as a counterweight to the “world models = video generation” framing.
2. How OpenAI’s Codex Team Actually Builds with Codex
“For specs, we write like 10 bullets and that’s it,” and “our designers now write more code than eng did 6 months ago” are two of the throwaway lines in this 43-minute sit-down with Codex product lead Alex and developer experience lead Romain on Peter Yang’s channel. The conversation is unusually candid about what shipping without traditional specs and roadmaps looks like inside a team that lives on its own tools. Closest thing to a field report you’ll get on agent-native product development right now.
3. A Non-Engineer Runs Claude Code Across 15 Repos to Answer Every Customer Question
Al Chen is a field engineer at Galileo, an AI observability platform, and he has never held an engineering role. He has also built something most coding teams would be proud of: a Claude Code setup that queries 15 separate internal repositories, stitches in Confluence docs and customer-specific quirks, and delivers answers that previously required pulling an engineer off real work. The walkthrough covers his custom Claude Code commands, the sixteen-line sync script (written entirely by Claude Code) that pulls every repo’s main branch each morning, and the multi-source MCP pattern that lets a single question hit code, docs, and deployment notes in one pass. If you’ve been treating Claude Code as a coding assistant, this is the reframe that turns it into a customer support operating system.
4. From Chaos to Choreography: Multi-Agent Orchestration That Actually Works
Sandipan Bhaumik from Databricks opens with the line of the week: “Adding more agents isn’t adding more features. It’s building a distributed system.” His 26-minute AI Engineer talk covers the silent handoff failures, stale state, and untraceable decisions that show up once you scale from one agent to five, then walks through the orchestrator and choreography patterns Databricks uses in production. If you’re past the proof-of-concept stage, this is the talk you actually need.
📰 3 Curated Reads
1. Components of a Coding Agent

Sebastian Raschka makes the case that what looks like a smarter model is usually a better harness around the same model. He breaks coding agents into six concrete pieces (live repo context, prompt shape and cache reuse, tool access, context reduction, structured session memory, and bounded subagents) and shows how they fit into a three-layer architecture of model, agent loop, and runtime support. Read this before you blame your model for behavior that’s actually a context engineering problem.
2. Your RAG Pipeline Is Overkill

Paul Iusztin argues that recursive language models (RLMs) make most RAG pipelines unnecessary. The core idea is that the model never receives the giant document directly. Instead, the data lives outside the context as a REPL variable, and the model writes code to explore, filter, and recursively process it through `llm_query()` calls. Iusztin reports RLMs being tested up to 10 million tokens with GPT-5 and Qwen3-Coder, and lays out four scenarios (file parsing, codebase analysis, legal and financial work, research synthesis) where this approach beats stuffing chunks into a vector store.
3. Gemma 4 and What Makes an Open Model Succeed

Benchmark numbers at release tell you almost nothing about which open models will actually get used, and Nathan Lambert uses the Gemma 4 launch to explain why. His five-factor framework (performance and size, country of origin, license, tooling at release, fine-tunability) maps onto the messy reality that ecosystem maturity often takes 18 months to catch up with a model launch. The note about Google moving to Apache 2.0 and the 30B dense model targeting the enterprise sweet spot is the part to underline.
🛠 2 Tools & Repos
1. mem0
https://github.com/mem0ai/mem0

Memory is the bottleneck for any agent that needs to remember anything across sessions, and mem0 is the fastest-moving open option for solving it. The framework manages user, session, and agent state through a single API, with self-hosted Python and TypeScript packages plus a managed cloud service if you want to skip the infra. The team reports 26% better accuracy than OpenAI Memory and roughly 90% lower token usage versus full-context approaches, which matches what people are seeing in production.
2. goose
https://github.com/aaif-goose/goose
Block built goose as a general-purpose AI agent in Rust, and it’s now part of the Agentic AI Foundation under the Linux Foundation. You get a desktop app, CLI, and API that work with 15+ LLM providers and over 70 MCP extensions, and you can use existing Claude, ChatGPT, or Gemini subscriptions instead of API keys. If you’ve been looking for a serious open alternative to the closed coding agent stack, this is the most active one right now.
🎓 1 Pick of the Week
How to Automate Your Life with Claude Code
Claude Code as a personal operating system, not as a coding tool. Hilary Gridley (former product leader) walks through how she runs her professional work and personal life through it as her primary interface. Her “anti-system system” leans on simple capture (an iPhone back-tap shortcut) and lets the model learn her preferences through observation rather than upfront configuration. The 10x impact framework for deciding what to automate is the part most people will steal, and the whole 51-minute walkthrough is reproducible on your own setup.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.