

Spotify's Agent Context Layer, DeepMind's Nine Erdős Proofs, and GitHub's Spec-Kit - The Tokenizer Edition #31
This week's most valuable AI resources

Hey there! This week, the scaffolding around the model did more work than the model itself. A 20B search agent beats a 30B rival by storing its memory in the harness. Spotify’s data assistant handles 13,000+ conversations because domain experts own its context layer. And an ex-Meta principal engineer ships up to 40 PRs a day by making agents review each other’s work. Let’s dig in.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Flow-matching language models trained on 10x fewer tokens, a 20B search agent that offloads memory to its harness, an LLM that plays both agent and environment, agent benchmarks rebuilt to stop saturating, and a vision-loop agent that fixes your LaTeX.
🎥 Videos: An ex-Meta principal’s 20-to-40-PRs-a-day agent pipeline, a repair layer that fixes open-model tool calls, a hands-on Claude Fable 5 verdict, and AlphaProof Nexus closing nine Erdős problems.
📰 Reads: Spotify’s expert-owned context layer, a 10-year engineer watching his specialization get repriced, and the Fable 5 safeguard that stayed invisible until developers pushed back.
🛠 Tools: GitHub’s spec-driven development kit, and a queryable knowledge graph of any codebase inside your coding agent.
🎓 Learning: Ship a grounded document copilot over SEC filings in four hours: FastAPI, Pydantic AI, Supabase, and React.
📄 5 Papers
1. ELF: Embedded Language Flows
https://arxiv.org/abs/2605.10938 | GitHub
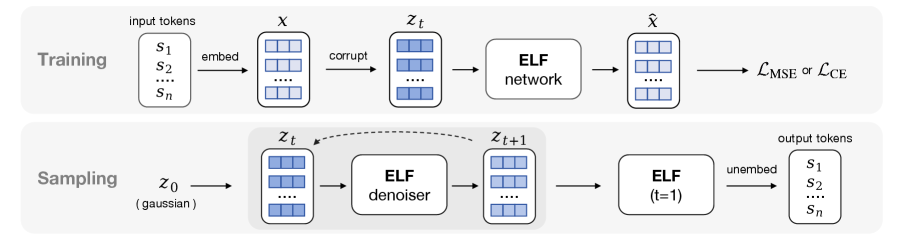
ELF trains a diffusion-style language model on 45B tokens. Rivals typically need over 500B. The MIT team keeps generation in continuous space until the last step, then converts to words, so the image-diffusion toolbox works on text almost unchanged. It beats other diffusion language models, not frontier models, and the authors say so upfront. If you’re watching for diffusion to become a serious alternative for text, this is the data-efficiency result to know.
2. Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
https://arxiv.org/abs/2606.02373 | GitHub
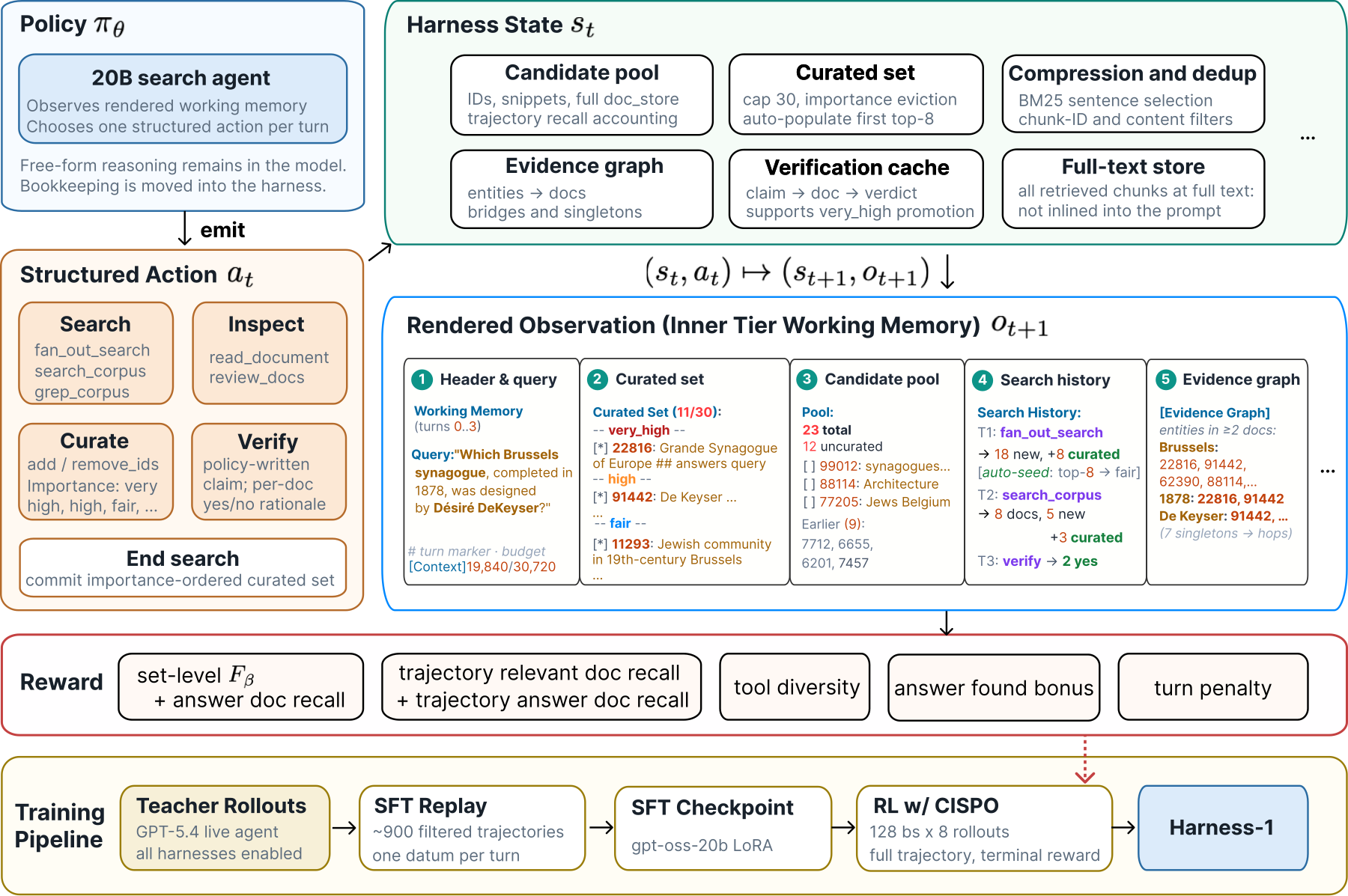
This 20B search agent stores its working memory (candidate lists, evidence, finished checks) in the harness instead of its own context window, and spends the context on decisions. It beats every open rival tested, including a 30B model. Among frontier models, only Opus 4.6 stays ahead. If you build research agents, read it for the harness design alone.
3. Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
https://arxiv.org/abs/2606.10917 | GitHub
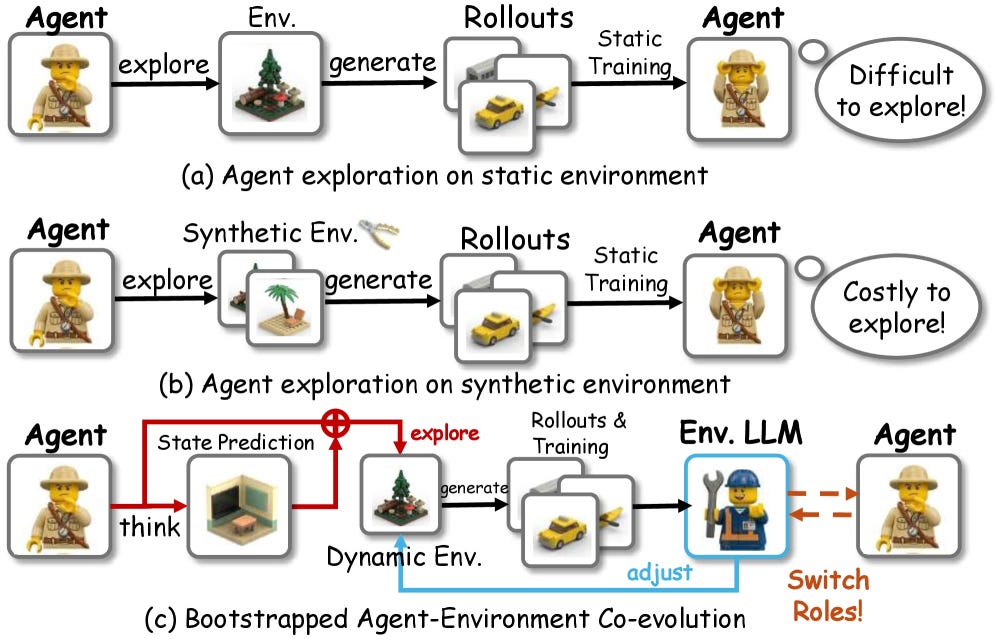
Training an agent needs an environment to practice in, and good environments are expensive. Here, one LLM plays both sides. As the agent, it predicts what happens next and gets rewarded when it’s right. As the environment, it studies its own failures and serves up more tasks like the ones it just failed. It posts average gains above 4% over strong RL baselines on small models. It’s flagged as work in progress, so treat it as a proof of concept that the environment side of agent training is becoming learnable too.
4. A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks
https://arxiv.org/abs/2605.28556
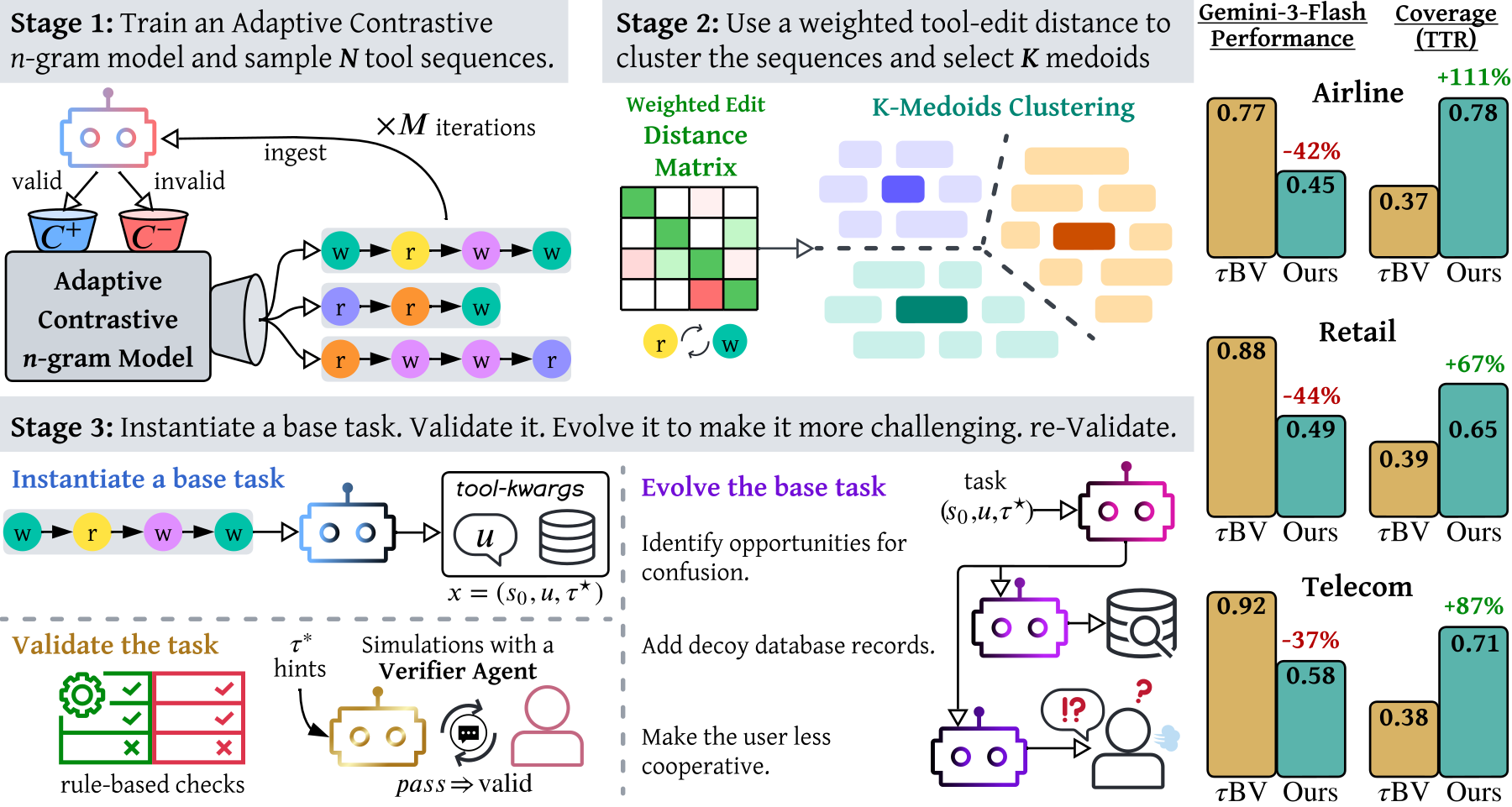
Your agent’s high benchmark score often measures the benchmark, not the agent. The authors rebuild τ²-Bench by working backwards: sample the tool sequences an agent could run, build tasks around them, then evolve the tasks until they’re hard. Gemini 3 Flash falls from as high as 0.94 on the original to as low as 0.28 on the rebuilt version. Before you trust a leaderboard number for a model decision, this paper shows you how much of it can be saturation.
5. PaperFit: Vision-in-the-Loop Typesetting Optimization for Scientific Documents
https://arxiv.org/abs/2605.10341 | GitHub
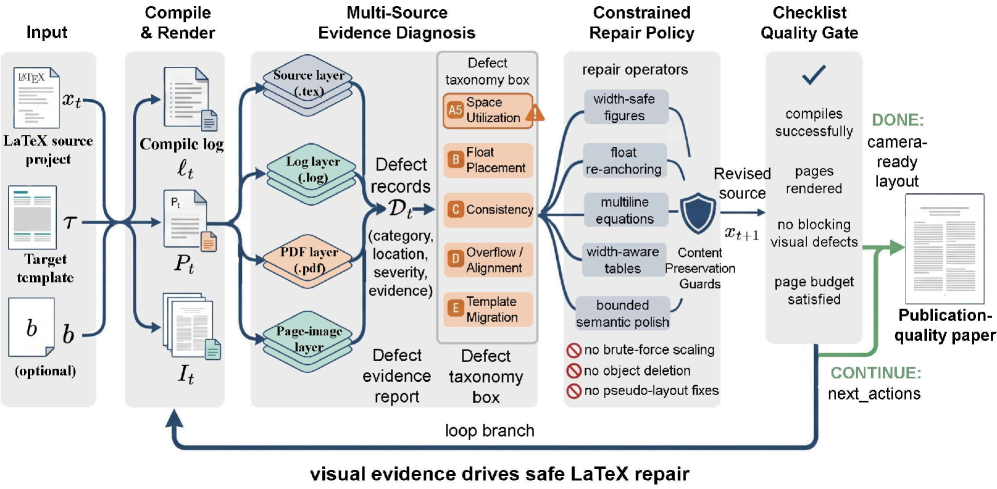
Your LaTeX compiles, but the figures drift, the tables overflow, and you’re a page over the limit at midnight. PaperFit looks at the rendered pages the way you would, spots the layout problems, and keeps applying careful fixes until a checklist passes. It meets the page budget 80.5% of the time, against 62.3% for the best baseline, and swapping the model underneath barely changes the score; the system does the work. If a LaTeX float has ever eaten your submission evening, this one is aimed at you.
🎥 4 Videos
1. How an Ex-Meta Principal Engineer Ships 20 to 40 PRs a Day
Kun Chen ships 20 to 40 PRs a day and never reviews the agent’s first draft himself. A second agent reviews the work in a fresh context window, because a reviewer in the same session inherits the writer’s bias. A test pass attaches screenshots before anything becomes a PR. The full setup includes a pool of pre-warmed worktrees that keeps 20 to 30 agents running at once. Chen’s three tools are open source; the coding agents underneath are the ones you already pay for.
2. Fixing Tool Confusion: A Repair Layer for Open-Model Agents
Open models keep fumbling tool calls, and the usual fix (send the error back and hope) doesn’t work: DeepSeek V4 Pro just repeats the same broken call. Ahmad Awais of CommandCode built a layer that repairs the call on the spot and sends the model a hint about what went wrong, so by the third try the model gets it right on its own. With that layer, DeepSeek V4 Pro beats Opus 4.7 on 6 of CommandCode’s 10 internal evals. If your agents run on open models, watch this one; the fix lives in your harness, not in a bigger model.
3. Claude Fable 5 With Early Access: Where It Wins, Where It Stalls
Claire Vo tested Fable 5 before launch. The model costs $10 in and $50 out per million tokens and burns roughly twice the tokens of other models. It excels at vision, document formatting, and long, hard technical work. It disappointed her on front-end design and wrote spec prose she found nearly unreadable. Watch this before you re-route your workloads.
4. AlphaProof Nexus and the Nine Erdős Problems
DeepMind pointed AlphaProof Nexus at about 350 unsolved Erdős problems. It cracked nine, some open for 56 years, for a couple hundred dollars each. A cheaper judge model compares pairs of wrong proofs, keeps the most promising failure, and restarts the search from there until a verifier signs off: a reliable system built from unreliable parts. Two caveats: the team picked problems that could be formalized, and smaller models solved zero.
📰 3 Curated Reads
1. Encoding Your Domain Expert: The Context Layer Behind Spotify’s Data Assistant
Spotify’s data assistant works because domain experts own what it knows. Each expert team curates its own cluster: the datasets that matter, approved question-and-SQL examples, and the docs that explain the business. Spotify tried generating those examples from old query logs with an LLM; curators accepted only 12.5% of them. Vedder has now handled 13,000+ conversations, and more than a quarter of its users had never written SQL. If you’re building an agent over company data, copy the ownership model, not just the prompts.
2. LLMs Are Eroding My Software Engineering Career and I Don’t Know What to Do
An anonymous backend engineer, ten years in, watched his expertise stop mattering one pillar at a time and wrote it down. The bugs that made him valuable used to take days; now his AI tooling one-shots 90% of them, race conditions included. His manager’s response when design docs ran slow: “Are you using AI? You should use more AI.” His strongest point is economic: once expertise is promptable, everyone competes as a generalist, and generalists earn less. The essay hit 1,100+ points on Hacker News. Read it next to the Kun Chen video above; they describe the same world from opposite ends.
3. If Claude Fable Stops Helping You, You’ll Never Know
The Fable 5 model card shipped with a safeguard designed to be invisible. If Anthropic classified your requests as frontier LLM development, the model could hold back, and the card said you would never see it: the safeguards “will not be visible to the user.” Jonathon Ready pulled that clause into the open, developers pushed back, and Anthropic reversed course; the safeguards will now be visible. His bigger worry remains: the card never says where frontier LLM development ends and ordinary fine-tuning begins. Ready trains his own rerankers for a bootstrapped product, exactly the gray zone the card leaves open.
🛠 2 Tools & Repos
1. github/spec-kit
https://github.com/github/spec-kit
GitHub is betting that a real spec beats one-shot prompting for anything non-trivial. Spec-kit bootstraps your repo with templates and slash commands, then walks your coding agent (it works with 30+, including Claude Code, Copilot, Cursor, and Codex) from constitution to spec to plan to tasks to implementation. If one-shot prompting keeps failing you on bigger features, this gives the work a structure your agent can follow.
2. Understand-Anything
https://github.com/Egonex-AI/Understand-Anything

Drop this plugin into your coding agent and it maps the whole codebase: tree-sitter reads the structure, LLM passes capture the meaning, and you get a knowledge graph with guided tours and a chat that knows your architecture. You commit the map to the repo as JSON, so the next person skips the analysis. It pairs naturally with spec-kit: one governs the code you’re about to write, the other explains the code you already have.
🎓 1 Pick of the Week
Build a Full-Stack GenAI Project in 4 Hours
Dave Ebbelaar builds a complete document copilot over SEC filings in just under four hours: ask a plain-English question, get a grounded, cited answer. He uses the stack working teams actually use (FastAPI, Pydantic AI, Supabase, React), builds the way engineers now build (prompting Cursor, then reviewing and debugging), and deploys the finished app. The companion repo has two branches: the starting scaffold and the finished product. It’s not beginner-friendly and each agentic query costs a dollar or two, but you finish with a deployable system instead of a toy.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.