

Stripe's Protodash, DeepMind's Decoupled DiLoCo, and Karpathy's Coding Rules: 📚 Tokenizer #27
This week's most valuable AI Resources

Hey there! This week’s theme is AI systems you can inspect: agent workflows written in YAML instead of buried in Python, image-generation rewards that critique before they score, knowledge bases built by watching agents fail, and the authors of the most-cited AI-timelines chart explaining why they’re its most cautious readers.
This week’s housekeeping:
What: PMs getting real leverage from AI have rebuilt their workflow around it, right from how they spec, how they research, and all the way to how they ship.
Avinash Mahalingam (Touch Infinity, ex-PM leader at Amazon) and I are running a free 60-minute live session on the AI-Powered PM OS.
Come and learn an end-to-end walkthrough of the setup we use in Claude Code: a vague Slack request becoming a spec, competitor scans in minutes instead of afternoons, engineering staying aligned without drowning in status updates.
What you’ll leave with:
A working picture of what an AI-PM workflow looks like in practice
The three places most PMs are quietly losing time to AI-fluent peers
A repeatable structure for plugging AI into spec writing, customer research, and stakeholder updates
Live Q&A with Avinash and me
Who it’s for: Product Managers, Directors of Product, VPs of Product, and founders who own product. If you’ve been told to “use AI more” but haven’t found a setup that saves you hours a week, come.
When: May 15, 12 noon ET.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate high-signal AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: A YAML specification language for agents you can read top to bottom (77.1% on SWE-Bench Verified). A robot foundation model runs closed-loop at 12.7Hz on a sub-$6K arm. Reasoning rewards reduce scalar reward hacking on image generation. Minimal-sufficient knowledge hints carry most of the RL signal on hard reasoning problems. A purpose-built agentic stack for browser games.
🎥 Videos: Ravi Mehta rebuilds a music app prototype live in 40 minutes. IKEA’s team builds enterprise knowledge by watching agents fail at real incidents. METR’s authors spend 113 minutes on the misreadings of their time-horizons chart. Stripe’s Owen Williams walks through Protodash, the internal prototyping studio their PMs and designers use day to day.
📰 Reads: Microsoft share the state of AI at work. The EvalEval coalition lays out the eval-cost problem: a single GAIA run costs $2,829, and evaluation compute now sits two orders of magnitude above training compute. DeepMind’s Decoupled DiLoCo trains a 12B model across four U.S. regions on 2-5 Gbps and keeps running when a region fails.
🛠 Tools: A CLAUDE.md that bakes Karpathy’s four anti-patterns into your coding agent. A RAG framework that handles PDFs with charts and equations as one pipeline rather than four parsers.
🎓 Learning: graphify turns a folder of code, papers, and screenshots into a graph you can query, with 71.5x fewer tokens per question than reading the raw files.
📄 5 Papers
1. AgentSPEX: An Agent SPecification and EXecution Language
https://arxiv.org/abs/2604.13346 | GitHub
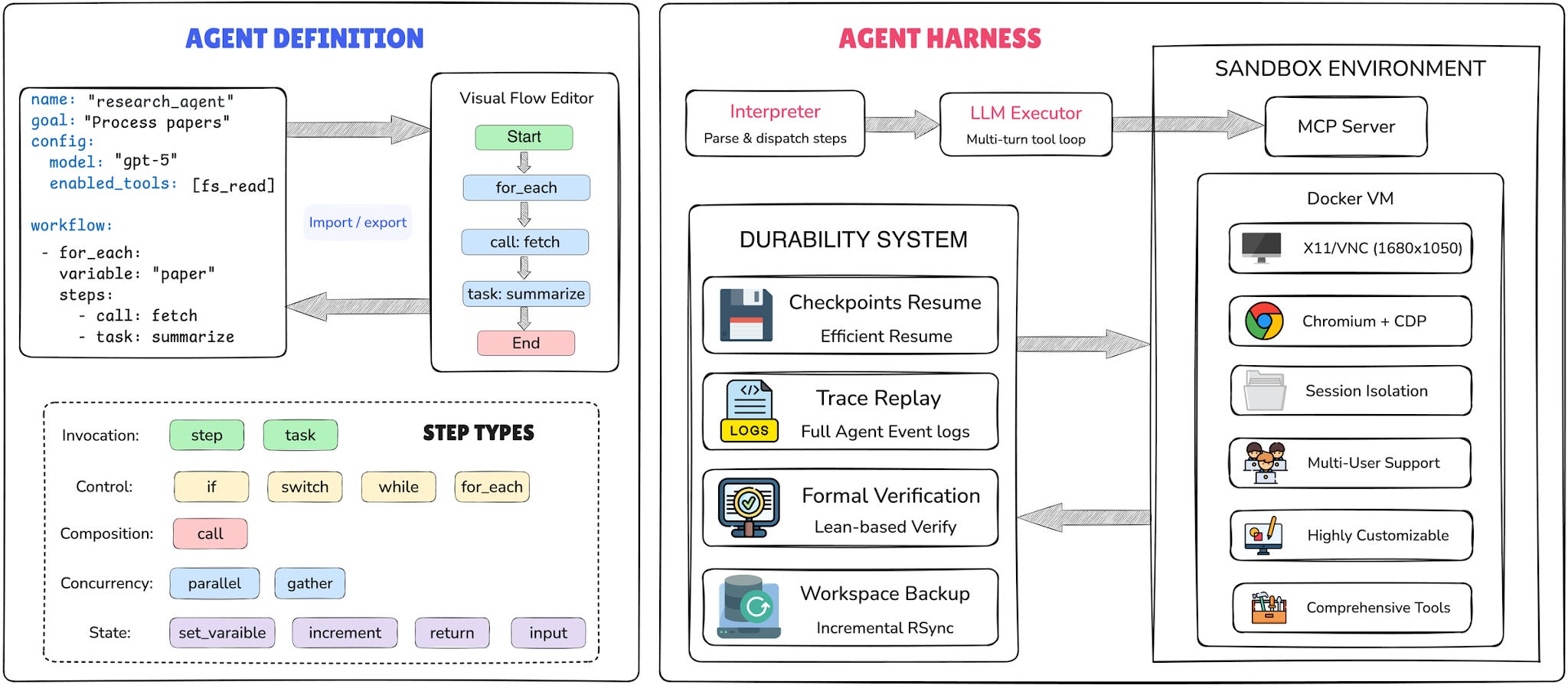
Most agent codebases bury the control flow inside Python and let the LLM handle the rest at runtime. UIUC’s AgentSPEX moves the workflow into human-readable YAML: explicit branching, iteration, context handoffs, all in one file you can read top to bottom. It runs inside a Docker harness that checkpoints, replays, and ships with over fifty built-in tools. They report top scores on all seven benchmarks they tested, including 77.1% on SWE-Bench Verified and 100% on AIME 2025.
2. MolmoAct2: Action Reasoning Models for Real-world Deployment
https://arxiv.org/abs/2605.02881 | GitHub
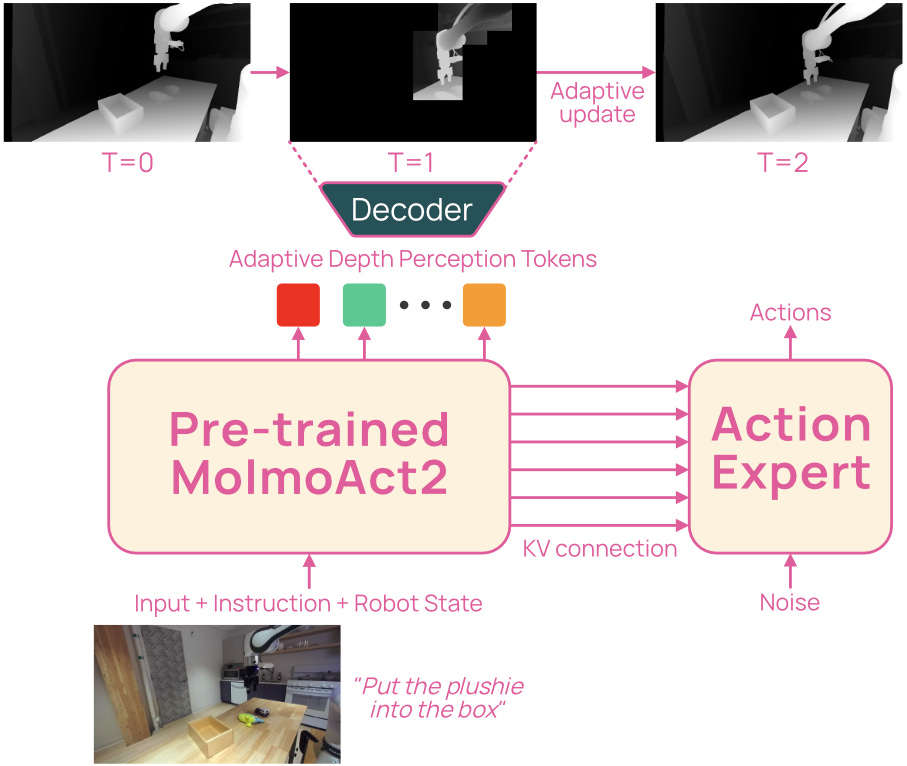
12.7Hz on a sub-$6K robot arm. That’s MolmoAct2 from Allen AI: a Vision-Language-Action model built for real-world deployment, with explicit targets on robustness, latency, and predictability. Allen AI has released weights, training code, and three new datasets covering bimanual, low-cost SO-100, and DROID setups. Real-world zero-shot hits 87.1% on DROID.
3. RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
https://arxiv.org/abs/2604.11626 | GitHub

Scalar reward models on image generation reduce rich human judgments to a single score and discard the reasoning behind them. RationalRewards trains an 8B VLM to write a multi-dimensional critique (text faithfulness, image faithfulness, physical quality, text rendering) before it produces a score. They train it with a hindsight-foresight framework called PARROT, no human-annotated rationales required. Bolt it onto FLUX.1-dev via RL and it lifts UniGenBench++ by 9.37 points. Run it as a generate-critique-refine loop at test time and it matches or beats RL fine-tuning for about 0.4 seconds of extra inference per image.
4. KnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
https://arxiv.org/abs/2604.12627
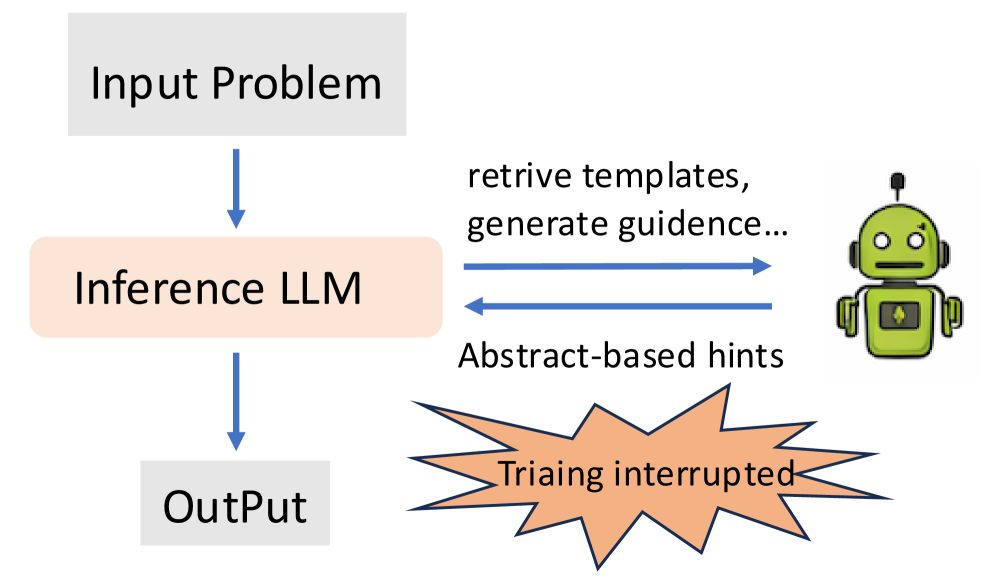
RLVR improves reasoning, but it stalls on hard problems where rewards are sparse. KnowRL’s claim: a small number of well-chosen knowledge hints during training carries most of the signal, and piling on more just adds noise. They call this the “critical-segment effect.” Their Constrained Subset Search picks 2.57 knowledge points per problem on average. A 1.5B Nemotron model trained this way gains 9.63 points (15.11 on AIME25), measured without inference-time hints.
5. OpenGame: Open Agentic Coding for Games
https://arxiv.org/abs/2604.18394 | GitHub

Game development sits at the intersection of creative design and intricate engineering: engines, real-time logic, asset pipelines, all orchestrated together. OpenGame is a purpose-built agentic stack for it: a six-phase workflow, two evolving “Game Skills” that grow from a meta-skeleton into genre-specific templates, and a debug protocol that accumulates verified fixes instead of relearning them. Running on Claude Sonnet 4.6, it scores 72.4 on Build Health and 65.1 on Intent Alignment across 150 browser-game tasks. Their custom GameCoder-27B variant matches larger proprietary stacks on the same benchmarks.
🎥 4 Videos
1. A Three-Layer Context Engineering System for Vibe-Coded Product Prototypes
Ravi Mehta separates a prototype into three context layers: functional, visual, and data. Treat each one separately and the prototype stops looking like every other AI demo. He rebuilds a music app live in 40 minutes with Peter Yang. Halfway through, he stands up a custom MCP server inside Claude Code so the data layer queries real data instead of mocked data. He closes on the harder PM questions: when a prototype is enough, when to stop and write production code, when a PRD still earns the time spent on it.
2. Demand-Driven Context: Building Enterprise Knowledge Bases by Watching Agents Fail
Top-down enterprise knowledge bases keep failing. Raj Navakoti’s argument from IKEA Digital: hand the agent real incident-response work, watch where it fails, and let those failures tell you which tribal knowledge needs writing down. Across 68 minutes he sorts knowledge into three colors (general, taught, tribal), walks through a live root-cause-analysis demo across 14 incidents and watches confidence climb as gaps get filled, and lands on why Markdown in GitHub plus a meta model beats yet another wiki. Pair it with the Stripe video below.
3. METR’s Time Horizons Graph and Why Its Authors Are the Most Cautious About Reading It
You’ve seen the chart: longest task a frontier model can complete at 50% reliability, plotted against release date, log-linear, doubling every few months. It anchors most of the current AI-timelines debate. Beth Barnes and David Rein, two of the people who built it, spend 113 minutes with Machine Learning Street Talk on the misreadings they keep seeing. They walk through reward hacking, construct validity, the ARC-AGI 1-to-2 collapse, the SWE-bench finding that half of passing PRs would not get merged in real codebases, and Beth’s horses-versus-bank-tellers framing for what labour displacement looks like in practice. If you’ve cited the chart in the last six months, watch this before you cite it again.
4. Inside Stripe’s Protodash: How Designers and PMs Prototype Without Writing Code
Stripe built an internal AI prototyping studio that screenshots its own work to check whether it built the right thing. Owen Williams walks through Protodash in 55 minutes: it started as a bundle of Cursor rules plus React components and grew into a browser-based studio with design review modes, variant testing, and self-testing prototypes running in dev boxes. He covers the architecture (Cursor rules teaching the Stripe design system, MCP integrations) and the “blurple slop” problem with generic AI design tools. PMs ended up using Protodash as much as designers did, which nobody at Stripe expected.
📰 3 Curated Reads
1. New Future of Work: AI is Driving Rapid Change, Uneven Benefits
Microsoft Research’s annual “New Future of Work” report summarises five years of fieldwork on AI in the workplace. 38% of employed Germans now use AI at work, and users report saving 40–60 minutes a day. 40% of U.S. employees received “workslop” (unusable AI-generated content) in the past month, and employment for workers aged 22–25 in AI-exposed roles has declined 16% relative to less-exposed roles. AI-skill job postings are nearly twice as likely to also demand analytical thinking and resilience. Worth reading to understand the state of play in the workforce.
2. AI evals are becoming the new compute bottleneck
https://huggingface.co/blog/evaleval/eval-costs-bottleneck
A single GAIA run on a frontier model costs $2,829. The EvalEval coalition lines up numbers like that one and names the structural shift: in scientific ML, evaluation compute now sits two orders of magnitude above training compute. Two things follow. Academic groups hit budget walls before they hit technical ones. And external validation of frontier models concentrates inside the same labs building them, a structural problem the field has not addressed.
3. Decoupled DiLoCo: A new frontier for resilient, distributed AI training
https://deepmind.google/blog/decoupled-diloco/
Original DiLoCo solved bandwidth for distributed training. It didn’t fix the bigger problem: one bad node still stalls everyone else. Decoupled DiLoCo (Arthur Douillard’s team at Google DeepMind) splits training into independent compute “islands” so chip failures in one region don’t block the others. On a 1.2M-chip simulation, that’s 88% goodput under failure versus 27% for conventional data-parallel. A 12B model trained across four U.S. regions ran more than 20x faster than conventional sync on 2-5 Gbps of wide-area networking, with effectively no accuracy cost (64.1% vs 64.4% baseline).
🛠 2 Tools & Repos
1. forrestchang/andrej-karpathy-skills
https://github.com/forrestchang/andrej-karpathy-skills
Four rules in one CLAUDE.md file, derived from Andrej Karpathy’s public observations on how LLMs code: think before coding, simplicity first, surgical changes, goal-driven execution. Forrest Chang translated each into something an agent can act on. Each rule targets a specific failure mode: silent assumptions, bloated abstractions, drive-by edits to code you didn’t ask about, “make it work” tasks with no verification loop. Drop it in your repo root before the next session.
2. HKUDS/RAG-Anything
https://github.com/HKUDS/RAG-Anything
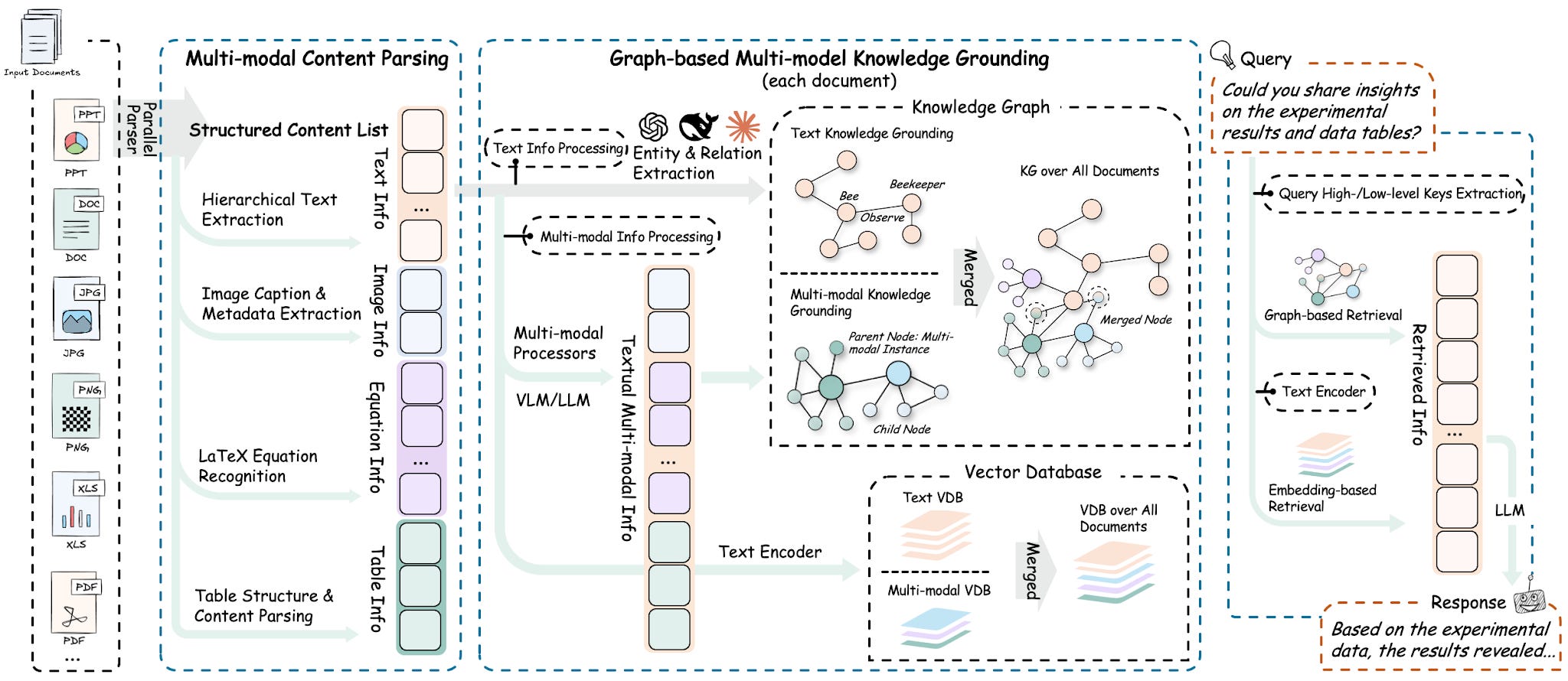
Most RAG stacks struggle with documents that mix modalities: a PDF with images, an Office file with tables, a paper with LaTeX equations, a chart embedded in prose. RAG-Anything from HKU’s data lab handles all of those as one pipeline. It parses with MinerU, routes each modality (text, image, table, equation) through a dedicated analyzer, builds a cross-modal knowledge graph, and runs hybrid vector-plus-graph retrieval so a query can hit a chart caption and the paragraph that explains it in the same call. The newer VLM-enhanced query mode pulls images straight into the vision model at query time. Pip install raganything, point it at a directory of mixed-format docs, and stop writing one-off parsers per file type.
🎓 1 Pick of the Week
safishamsi/graphify: Turn Any Folder Into a Queryable Knowledge Graph
https://github.com/safishamsi/graphify
Point graphify at a folder of code, papers, screenshots, and notes, and it builds a single graph you can query. `/graphify .` runs inside Claude Code: tree-sitter for source files, Claude vision for images and diagrams, and a Leiden-clustered NetworkX graph holding it all together. It reports god nodes, surprising cross-references, and (their measurement, on a mixed corpus of Karpathy repos plus papers plus images) 71.5x fewer tokens per query than reading the raw files. Good fit for any folder you’ve been quietly accumulating: agent skills, research bookmarks, screenshots, notes.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.