

Tencent Compresses Reasoning 3-4x, Robots Master 35,000 Hours of Human Data, and Anthropic's Evaluation Framework - 📚 The Tokenizer Edition #15
This week's most valuable AI resources

Hey there! Robots just learned to treat 35,000 hours of human movements as a universal training language, mechanistic interpretability made the jump from observation to intervention, and researchers compressed reasoning into images at 3-4x efficiency. Real progress on problems that matter.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Actionable mechanistic interpretability, agent efficiency frameworks, 3-4x reasoning compression, cross-embodiment robotics, unified video generation
🎥 Videos: Agent architecture patterns, live coding marathon, production evals, MoE routing mechanics
📰 Reads: Anthropic’s evaluation resilience, AI emotional frameworks, semantic search without embeddings
🛠 Tools: Production RAG and distributed training infrastructure
🎓 Learning: MIT’s command-line fundamentals
I’m running an ML & Generative AI System Design workshop with Packt.
We’ll cover the core design principles for building solid AI products: making systems reliable, measuring what matters, and designing architectures that work in production.

What topics/problems would you most want covered in a system design workshop? Drop a comment or DM me.
📄 5 Papers
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
https://arxiv.org/abs/2601.14004 | GitHub
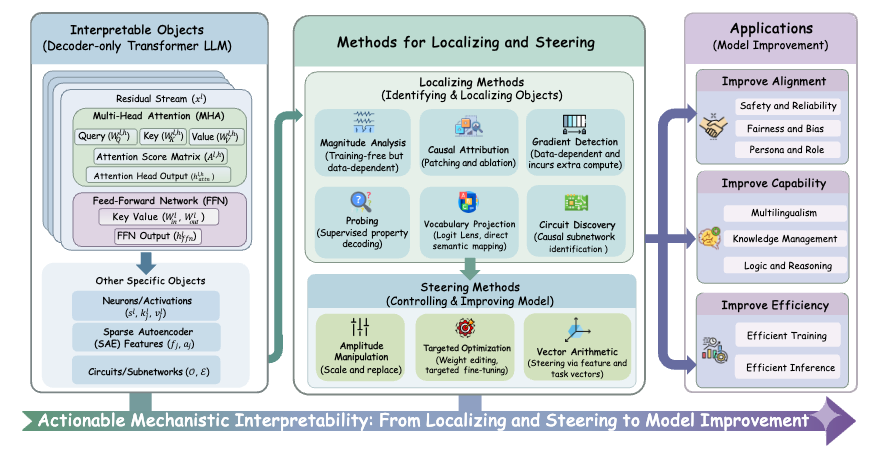
Mechanistic interpretability research has spent years documenting how models work internally. This survey introduces the first systematic framework for actually using those insights to improve models. The “Locate, Steer, and Improve” pipeline transforms interpretability from passive analysis into active intervention, showing how to diagnose issues in specific model components, steer behavior through targeted modifications, and measurably improve alignment, capability, and efficiency. The framework provides actionable protocols for practitioners who want to do more than just observe their models.
Toward Efficient Agents: Memory, Tool learning, and Planning
https://arxiv.org/abs/2601.14192 | GitHub
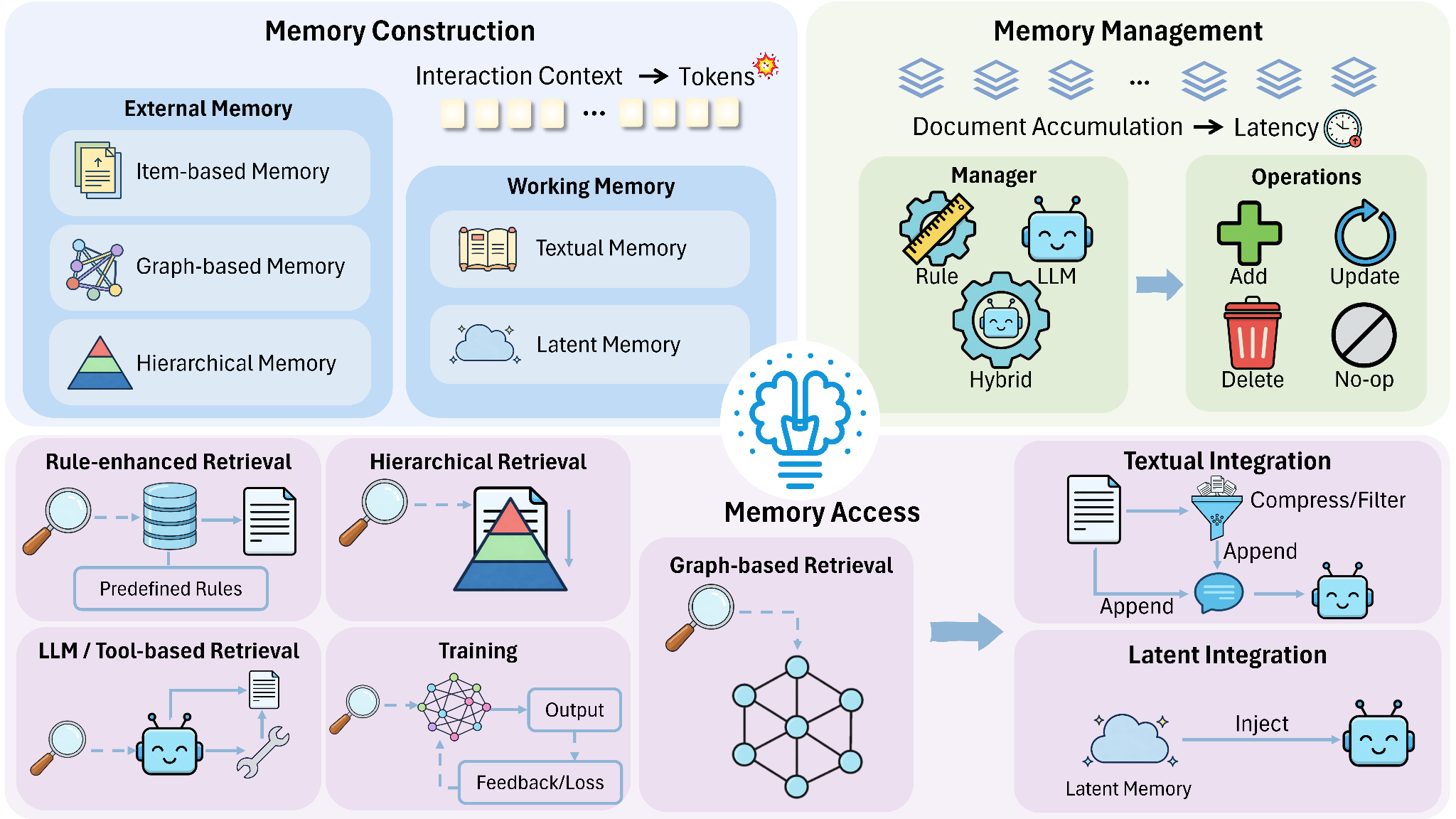
Production AI agents burn through tokens, time, and compute budget faster than most teams anticipate. This comprehensive survey tackles efficiency across three critical components: memory management through context compression, tool learning via reinforcement learning rewards that minimize unnecessary invocations, and planning with controlled search mechanisms. The research addresses the gap between agents that work impressively in demos and systems that remain economically viable at scale. If deployment costs are keeping your agents in the lab, this provides frameworks for optimizing them.
Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
https://arxiv.org/abs/2601.14750 | GitHub
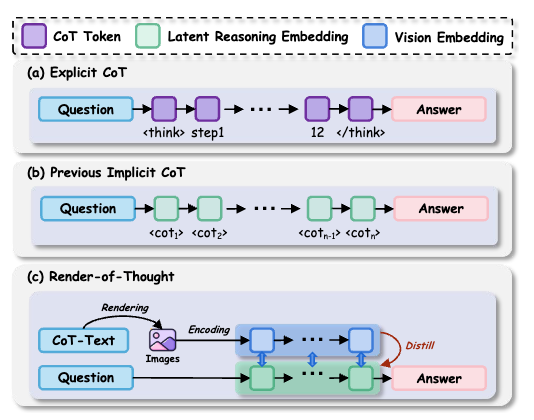
Chain-of-thought prompting unlocked reasoning capabilities but created a verbosity problem. Render-of-Thought converts those verbose textual reasoning steps into compact visual representations, achieving 3-4x token compression while maintaining competitive performance on mathematical and logical reasoning benchmarks. The framework leverages vision encoders from existing VLMs as semantic anchors, making it plug-and-play without additional pretraining. The approach addresses a practical bottleneck: getting models to reason without drowning in tokens.
Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
https://arxiv.org/abs/2601.12993 | GitHub
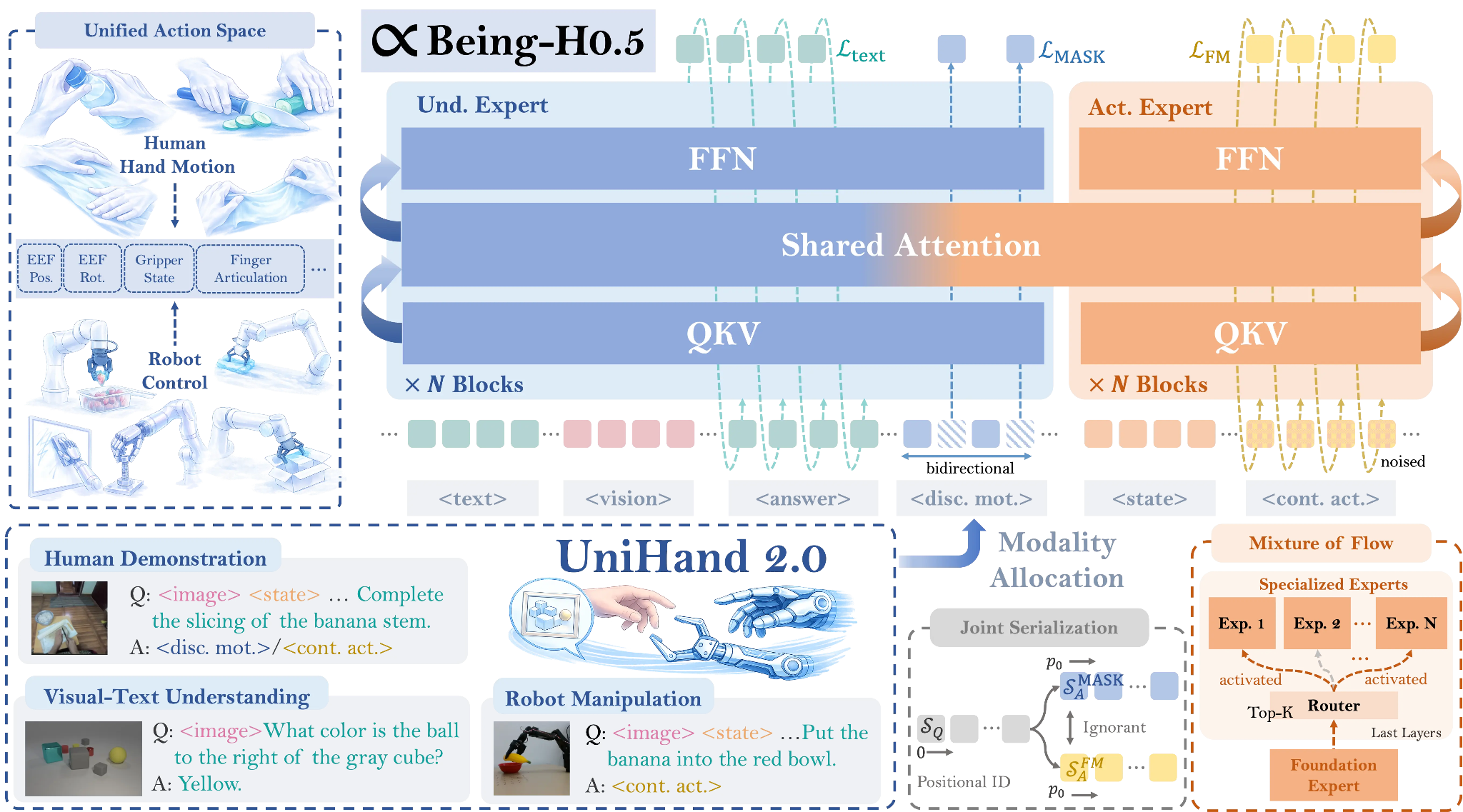
Most robot learning systems work brilliantly on the hardware they trained on and catastrophically fail when transferred to different morphologies. Being-H0.5 treats human interaction patterns as a universal “mother tongue” for physical manipulation, training on over 35,000 hours of multimodal data across 30 robot embodiments. The key innovation is a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, letting low-resource robots bootstrap skills from human demonstrations and high-resource platforms. The system achieves 98.9% on LIBERO and 53.9% on RoboCasa while demonstrating genuine cross-embodiment transfer on five different robotic platforms.
OmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
https://arxiv.org/abs/2601.14250 | GitHub
Video generation models typically handle appearance transfer or temporal effects separately, requiring different models for each task. OmniTransfer unifies spatial appearance transfer (ID and style) with temporal video transfer (effects, motion, camera movement) in a single framework. The system uses Task-aware Positional Bias to adaptively leverage reference video information, Reference-decoupled Causal Learning for efficient transfer, and Task-adaptive Multimodal Alignment to handle different tasks dynamically. The framework matches pose-guided methods in motion transfer without requiring explicit pose extraction, establishing a more flexible paradigm for video generation.
🎥 4 Videos
Agent Skills, Rules, Subagents: Explained!
Lee Robinson simplifies the complex terminology around managing context with coding agents, covering the evolution and core concepts behind rules, commands, MCP servers, subagents, modes, hooks, and skills. The video provides clarity on when to use each approach, cutting through the confusion that comes with rapidly evolving agent architectures. Helpful if you’re building with AI coding assistants and need clear decision frameworks for context management.
Vibe Code Camp: Live Marathon With the World’s Best AI Builders
A live coding marathon featuring developers building real projects with AI tools. The session provides unfiltered looks at how experienced builders approach problems, handle tool limitations, and combine different AI capabilities in production workflows. Rather than polished tutorials, you see actual development with all the debugging, iteration, and problem-solving that comes with building AI-powered applications.
AI Evals for Everyone
https://www.youtube.com/playlist?list=PLZoalK-hTD4VPIkRXNdSEwcTCt2QUgEPR
This playlist covers evaluation frameworks that work beyond toy benchmarks. The content addresses designing evaluations that capture real failure modes, continuous evaluation strategies for production systems, and practical approaches to measuring what actually matters. Essential viewing if your models perform well on standard benchmarks but struggle in deployment, or if you need systematic ways to track improvements across releases.
MoE Token Routing Explained: How Mixture of Experts Works (with Code)
Mixture-of-experts models power many frontier systems, but their routing mechanisms remain poorly understood. This video walks through the actual code that determines which tokens get routed to which experts, explaining the load balancing challenges and why naive routing strategies fail. With models like DeepSeek-R1 using MoE architectures, understanding these fundamentals helps you work with and debug these systems effectively.
📰 3 Curated Reads
AI Resistant Technical Evaluations
https://www.anthropic.com/engineering/AI-resistant-technical-evaluations
Anthropic’s performance engineering team had to redesign their hiring take-home test three times because Claude kept beating it. When Opus 4.5 matched the best human performance within the 2-hour time limit, they faced a problem: candidates’ optimal strategy became delegating entirely to Claude Code. The article documents each iteration, from realistic optimization problems to increasingly unusual puzzle-like constraints, revealing what happens when your own AI outperforms most technical candidates on the tests designed to evaluate them.
A feelings wheel but for robots

Hilary Gridley built the “AI Steering Wheel” to solve a vocabulary problem: LLMs are extremely sensitive to word choice, but most people lack precise language for what they want. Inspired by psychology’s Feelings Wheel, her tool organizes feedback across six dimensions (Originality, Grounding, Risk, Scope, Style, Certainty) with increasingly specific terms. “Make it more specific” and “make it more detailed” sound similar but produce completely different results from LLMs. The same precision helps when giving feedback to people, not just models.
Large scale semantic search without embeddings
https://fergusfinn.com/blog/arxiv-llm-search/
Fergus Finn demonstrates building semantic search over academic papers without traditional embedding pipelines. The approach bypasses the usual vector database infrastructure, using LLMs directly for relevance matching at query time. The method trades some retrieval speed for elimination of embedding maintenance overhead and improved interpretability of search results. Particularly relevant if you’re building search systems where embedding drift or maintenance burden has become problematic.
🛠 2 Tools & Repos
RAG Project (bRAG-langchain)
https://github.com/bragai/bRAG-langchain
A production-focused RAG framework built on LangChain that addresses common implementation gaps in retrieval-augmented generation systems. The repository includes patterns for document processing pipelines, retrieval strategies that work beyond simple similarity search, and integration approaches for connecting to various data sources. Designed for teams moving from RAG prototypes to production deployments where reliability and performance actually matter.
DeepSpeed
https://github.com/deepspeedai/DeepSpeed
Microsoft’s distributed training library makes training large models practical. DeepSpeed handles the infrastructure complexity of multi-GPU and multi-node training, implementing memory optimization techniques like ZeRO (Zero Redundancy Optimizer) that let you train models that wouldn’t fit in memory otherwise. The library includes optimizations for both training and inference, with specific support for mixture-of-experts architectures. Essential infrastructure for teams working with models beyond what fits on a single GPU.
🎓 1 Pick of the Week
MIT’s Missing Semester 2026
https://www.youtube.com/playlist?list=PLyzOVJj3bHQunmnnTXrNbZnBaCA-ieK4L
MIT’s course on the practical computing skills that formal CS education typically skips. The 2026 playlist covers shell scripting, version control, text manipulation, debugging tools, and the command-line workflows that separate efficient developers from those constantly fighting their environment. These fundamentals compound in value over your entire career, making tasks that seem arcane to beginners second nature to experienced practitioners. If you’ve ever watched a senior engineer accomplish in seconds what takes you minutes of clicking through UIs, this teaches those techniques systematically. In this age of AI-assisted coding, these are the skills you absolutely should master.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.
I resonate with how you framed these advancements. This is exactly the meaningful progres AI needs right now. The sheer scale of robots learning from human data is truly fascinating. And the efficiency gains in reasoning are quite transformative. Great insights, as always.