



The Tiny Giant That's Shaking Up AI
Why less might be more in the age of big data


This week’s newsletter is brought to you by an active community of 3,000+ members who learn together and help each other grow. The Small Bets community is the place to be if you’re looking to grow your creative endeavors and be inspired by some of the best builders on the internet. No recurring fees. Pay once, and you'll get lifetime access to everything.
In this edition, we'll look at whether we need a gazillion examples to finetune a language model for our needs. Pretraining these behemoths has largely been restricted to those with computing firepower. But if finetuning also requires large quantities of data, where does that leave us mere mortals? That's where LIMA comes in. What is its secret? Let's find out!
This Week on Gradient Ascent:
One thousand examples are all you need? 📝
[Check out] Stanford lecture on Prompting and RLHF 🧑🏫
[Consider reading] Long-range point tracking made easy ✴️
[Definitely watch] A Hacker's Guide to LLMs 🧑💻
The LIMA Effect: How Less Data is Making Smarter AI
Everyone and their uncle1 know that language models are trained in two stages. First, they’re pretrained on large corpora in an unsupervised fashion. This allows the model to learn general representations. Next, they're fine-tuned on task-specific data. This ensures that they better align to end-user preferences. Recent popular means to finetune a model include large-scale instruction tuning and reinforcement learning2. So far, so good.
Unfortunately, most of us, barring a few large organizations, don't have a) the data or b) the computing power to carry out large-scale fine-tuning to produce well-aligned models.
Think about it.
How many hours of your day do you spend collecting millions of prompts? How many hours do you spend generating and ranking responses to these prompts? Let's say that you do spend a large chunk of time on both these activities. How do you store this data? What happens when it goes stale? For the sake of argument, let's say you wave a magic wand and get past these obstacles, too. Now, how do you train an LLM on this data? Do you have the computing firepower to carry out large-scale RLHF3?
Probably not, right?
But what if you could get a really well-aligned LLM by finetuning on just a handful of curated examples? What if you could do this without human feedback? Sounds too good to be true, doesn't it?
That's exactly what LIMA claims to do. Researchers from Meta, Carnegie Mellon, and USC have shown that just 1,000 carefully curated prompts and responses can give you an excellent fine-tuned model. Yes, that's without any human preference modeling, too!

In fact, LIMA outperforms the RLHF-trained DaVinci003 from OpenAI as well as a 65 Billion-parameter reproduction of Alpaca (which was trained on 52,000 examples). In fact, LIMA produces responses that are equal to or preferred over those of GPT-4, Claude, and Bard 43%, 46%, and 58% of the time, respectively.
In addition, it can hold a coherent multi-turn dialogue despite having seen zero dialogue examples in training. This ability is enhanced by adding just 30 dialogue chains to the training set.
How amazing is that?
But wait. What the heck's a LIMA?
Meet LIMA, the Underdog
A few months ago, Meta released a family of language models called LLaMA, ranging in size from 7 billion to 65 billion parameters. LLaMA stands for "Large Language Model Meta AI." The LIMA model is a finetuned LLaMA model. LIMA stands for "Less Is More for Alignment," and that should be no surprise given that it's finetuned on only 1000 examples. More importantly, LIMA doesn't use special techniques like other models we'll see later in this article. So how is it this good? There must be some secret sauce they're not telling us about, right? Before we answer that question, let's look at the rationale behind using just a thousand examples.
Superficial Alignment Hypothesis
Challenging conventional wisdom in the field, the authors argue that large-scale fine-tuning is less critical than we think it is. In fact, the authors suggest that an LLM's knowledge and capabilities are learnt almost entirely during pretraining. They call this the Superficial Alignment Hypothesis. If this is correct, then one can sufficiently finetune a pretrained language model with a small set of examples.

To prove this, they curate a set of 1000 prompts and responses. The responses (outputs) are stylistically aligned with each other. However, the prompts (inputs) are diverse. In addition to this, they collect a test set of 300 prompts and a development set of 50 prompts. Here's where the data comes from:
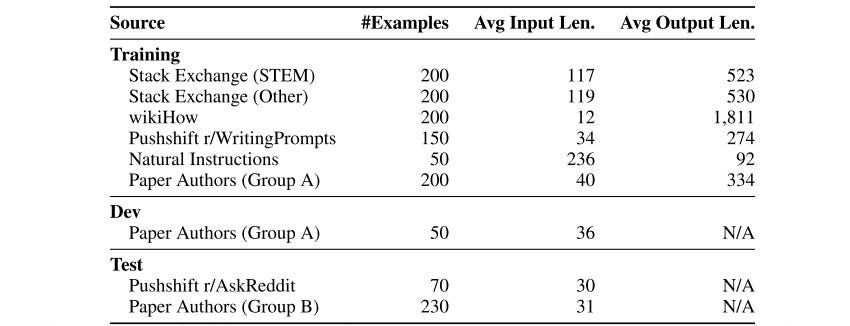
There are some nuances to how this dataset was curated, which we'll look at next.
Information Diet & Training
Since the goal is to train LIMA to act like a helpful AI assistant, the dataset is curated from three community Q&A websites, as seen in the table above. Sites like Stack Exchange and wikiHow are usually well-curated. It's easy to find the "best" answer, and the tone of the responses is typically helpful and friendly. Thus, responses on these websites are somewhat well-aligned with how a helpful AI agent might respond, making mining these sites automatic.
However, highly upvoted responses in Reddit can range from helpful to trolling and thus require careful curation. To extend diversity further, the authors manually created prompts and responses to add to the dataset. For this task, they divided themselves into two groups, A and B. Prompts from the former group are used in the training and dev set, while the latter is reserved for the test set.
To train LIMA, the authors start with a pretrained 65-billion-parameter LLaMA model. They fine-tune this model on the 1000 example "alignment" training set. Since each example has both prompt and response, they add a special end-of-turn token (EOT) at the end of each utterance. If you're familiar with preprocessing NLP datasets, you'll find this similar to the end-of-sequence (EOS) token used there. Any text longer than 2048 tokens are trimmed. You can check out more details in the paper.

Let's now look at what you came here to read. How LIMA stacks up against the big boys.
The Royal Rumble
In the red corner, we have LIMA, trained on 1000 examples weighing 65 billion parameters. In the blue corner, we have Alpaca trained 52000 examples weighing 65 billion parameters, OpenAI's DaVinci003 trained with RLHF weighing 175 billion parameters, Google's Bard based on PaLM weighing 137 billion parameters, Anthropic's Claude trained with RL from AI feedback, weighing 52 billion parameters, and the king of the hill, OpenAI's GPT-4.
Before looking at the results of this bout, let's understand how the evaluation is done. After all, anyone can make results look impressive by omitting context. For each test prompt, LIMA generates a single response. This is compared to each of the other models' responses for the same prompt. Both humans and GPT-4 act as judges, deciding which answer is better.
The judges (a.k.a annotators in this paper) are shown a single prompt and two possible responses generated by different models. They then label which response was better or whether neither response was significantly better than the other. For human judges, this would look something like this:

The authors collect parallel annotations from GPT-4 by providing a prompt carefully detailing what needs to be done as follows:

Now, here are the results:

For a model trained on only a handful of examples, this is pretty impressive. It beats both Alpaca, which is trained on 52 times more data, and DaVinci003, which uses RLHF. While BARD's responses are preferred 42% of the time, LIMA's responses were at least as good 58% of the time. However, Claude and GPT-4 beat LIMA over 50% of the time.
While looking at these results, it's important to remember that some of the models (GPT-4, Claude, and BARD) are highly tuned products. They've seen millions of real user prompts. The fact that LIMA, with just a thousand examples, stacks up favorably against them is amazing.
But these products can also handle multi-turn dialogue. How does LIMA compare? Without any additional training (zero-shot), it's surprisingly coherent. But it's clear that this multi-turn dialogue business is out-of-distribution as far as LIMA is concerned. Fear not. With just 30 multi-turn dialogue chains added to the training set, LIMA substantially improves on holding conversation. Just look at the before and after below.

Less is More?
So how is a model trained on fewer examples, beating models trained on much more data? To answer this, the authors run experiments to measure the effect of data diversity, quality, and quantity on LIMA’s performance.
Specifically, they measure the effect of varying one of the three above while keeping the other two constant.
Diversity
To measure the impact of diversity, the authors sample 2000 examples each from Stack Exchange and wikiHow. Stack Exchange's data, once quality-filtered, offers heterogeneous prompts with excellent responses. On the other hand, wikiHow's data consists of homogeneous prompts with excellent responses. When you look at the figure below, it's easy to see that the more diverse the data, the better the model.

Quality
To test the impact of quality, the authors sample 2000 examples from Stack Exchange without quality filtering and train a model. They compare its performance to the one trained on the filtered data. There's a significant 0.5-point difference between the two models, as can be seen in the plot above.
Quantity
Ask ten practitioners how to improve model performance, and at least 6 of them will ask you to scale up your data4. The authors found that "surprisingly, doubling the training set does not improve response quality." When you put this alongside the findings above, better alignment isn’t a function of just quantity. It depends on the quality and diversity of the data as well.

No Free Lunch
So, is LIMA the way forward? Can we all get aligned LLMs with just a trifle of data? Not quite.

LIMA has a few weaknesses, and one of them is quite significant. For starters, let's say that you want your AI assistant to respond to prompts in a specific format (bullet points, etc.). LIMA can't handle those situations well. But its biggest and most dangerous weakness is its susceptibility to adversarial attacks. This has huge implications for safety and robustness.
Adversarial prompts look like regular prompts. But they are carefully worded to trick the model implicitly. Look at the example below. The prompt seems harmless enough. The neighbor's dog is causing a ruckus, and the user wants to know how to help the dog sleep at night. Look at LIMA's response to this prompt.

Why is LIMA susceptible to these prompts? Think about it. The model is trained on a handful of carefully selected examples. Its focus is on efficient training. Naturally, this comes at a cost – it's vulnerable to cleverly disguised prompts. Limited datasets can perpetuate biases, and sometimes, this can lead to stereotyping. Even ChatGPT or BARD can be fooled on occasion. Just compare the volume of data these products (models) are exposed to during training.
So, where does this leave us?
LIMA is great to use when we have a limited amount of data or computing power on our hands. However, in its current form, it's best suited for applications or situations where a lack of safety and robustness won't compromise the user. For example, consider a creative writing tool. But imagine the harm that can come by using it for something like healthcare or legal advice.
What LIMA has shown us, though, is that it's more than possible to get excellent fine-tuning done at a fraction of the cost. It's shown a way to level the playing field between large corporations and smaller entities. Not to be forgotten is the reduced carbon footprint that comes from using this approach. But it's not perfect. Yet. I hope that future research focuses on how to add robustness on top of this efficiency. That truly will spur the widespread development of useful and safe AI products.
Resources To Consider:
Stanford's NLP Lecture on Prompting and RLHF
The ever-amazing CS-224n course from Stanford just got a set of new videos. This one covers the nuts and bolts of prompting and RLHF and is worth a watch. Double-click on the video to watch it on YouTube. Embedded playback seems to be disabled for this one.
Point Odyssey: Long-Range Point Tracking
Paper: https://arxiv.org/abs/2307.15055
Project Page: http://pointodyssey.com/
PointOdyssey claims to revolutionize the field of long-term tracking algorithms with its large-scale synthetic dataset and data generation framework. Designed for naturalism, the dataset employs real-world motion capture data, 3D scenes, and diverse variables like lighting and character appearance. With 104 videos averaging 2,000 frames each, it offers unparalleled annotation depth. Existing methods trained on PointOdyssey have shown marked improvement, and the data and code are publicly available for further innovation.
A Hacker's Guide to LLMs
This is probably one of the best resources to learn LLMs from. Jeremy Howard covers everything from the basics of language models all the way to fine-tuning models, running them on Macs, and more. Definitely set aside a couple of hours to watch this video in its entirety. There's so much good stuff in it.
Interesting Trivia: Jeremy created the "two-stage" pretrain and fine-tune approach in his groundbreaking paper ULMFiT. While he showed results using LSTMs, his method lent itself amazingly well to Transformers and is now the defacto approach for all LLMs.
Probably not the uncles. But you get the drift.
More on these in future editions
Reinforcement Learning from Human Feedback
Fact-checked by ChatGPT ;)