

📚 The Tokenizer Edition #2: GUI Agents Break Through and Video Models Hit New Heights
This week's most valuable AI resources

Hey there! This week brought genuinely exciting developments in GUI automation and video generation that feel like glimpses into how we'll actually interact with AI. GUI agents achieving 73% success rates on real mobile tasks, and video models generating coherent 10-second clips at 1080p don't feel like incremental improvements.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
• 📄 Papers: GUI automation agents hitting production-ready performance levels, plus unified video models that actually work across tasks
• 🎥 Videos: Real-world AI tool building from Amplitude, evaluation frameworks that matter, and DeepMind's latest “game” AI breakthroughs
• 📰 Reads: GPT-oss architectural deep-dives, context engineering strategies, and practical skills for thriving with AI
• 🛠 Tools: Automated paper curation systems and comprehensive LLM learning resources that cut through the noise
• 🎓 Learning: Why AI products need fundamentally different development approaches (hint: it's not just about the tech)
📄 5 Papers
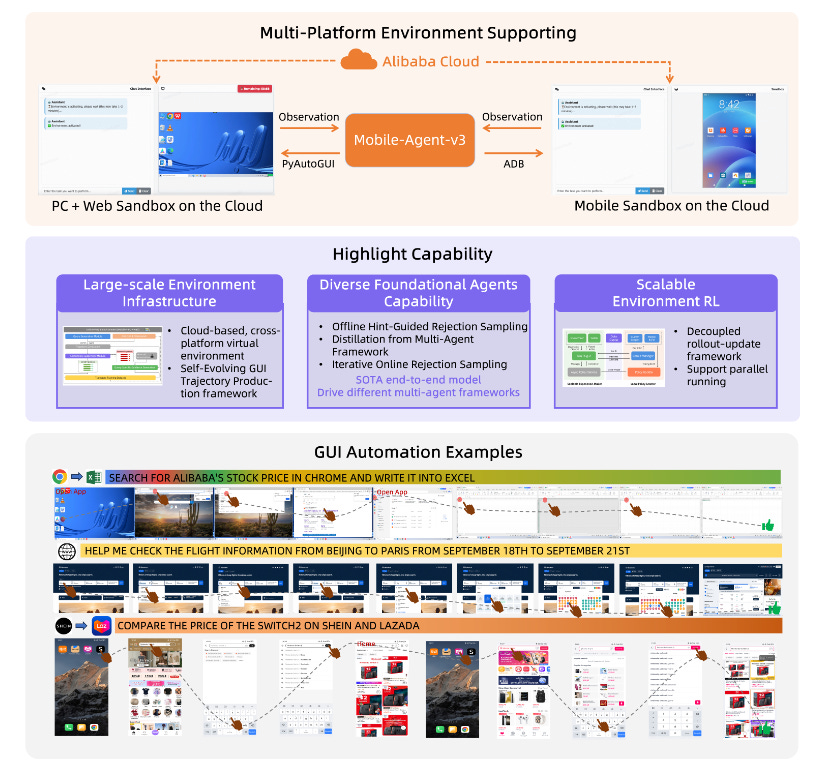
Mobile-Agent-v3: Foundational Agents for GUI Automation
https://arxiv.org/abs/2508.15144 | GitHub
Mobile-Agent-v3 achieves a 73.3% success rate on AndroidWorld, marking significant progress toward practical GUI automation. The system introduces GUI-Owl, a 7B model that combines screen perception with task understanding. Unlike traditional automation scripts that break when interfaces change, GUI-Owl learns from its interactions through a self-improving feedback loop. The self-evolving training pipeline addresses a major challenge in GUI automation: generating quality interaction data without massive manual annotation.
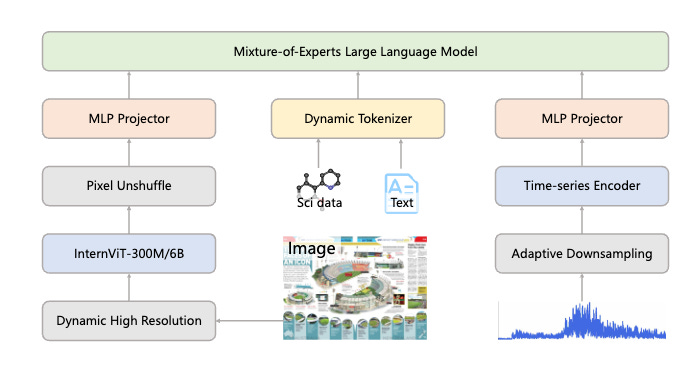
Intern-S1: A Scientific Multimodal Foundation Model
https://arxiv.org/abs/2508.15763 | GitHub
Intern-S1 tackles the gap between open and closed-source models in scientific domains head-on. This 235B parameter model was specifically trained on 2.5T scientific tokens and outperforms closed-source models on specialized tasks like molecular synthesis planning and crystal stability prediction. It's a significant step forward for open science - having competitive performance on highly specialized tasks that usually require proprietary systems. The "Mixture-of-Rewards" training across 1000+ tasks means it's not just memorizing textbooks but learning to reason like a scientist. If you're tired of AI that can write poetry but struggles with actual research, this addresses that gap.
Waver: Wave Your Way to Lifelike Video Generation
https://arxiv.org/abs/2508.15761 | GitHub
Waver unifies text-to-video, image-to-video, and text-to-image generation in a single system, producing 5-10 second videos at 1080p with strong temporal consistency. While most teams build separate models for each task, Waver's unified approach ranks in the top 3 globally on video generation leaderboards. The key innovation is their Hybrid Stream DiT architecture combined with MLLM-based quality filtering for training data. They're also sharing implementation details - architecture specifications, training procedures, and data curation methods that typically remain proprietary.
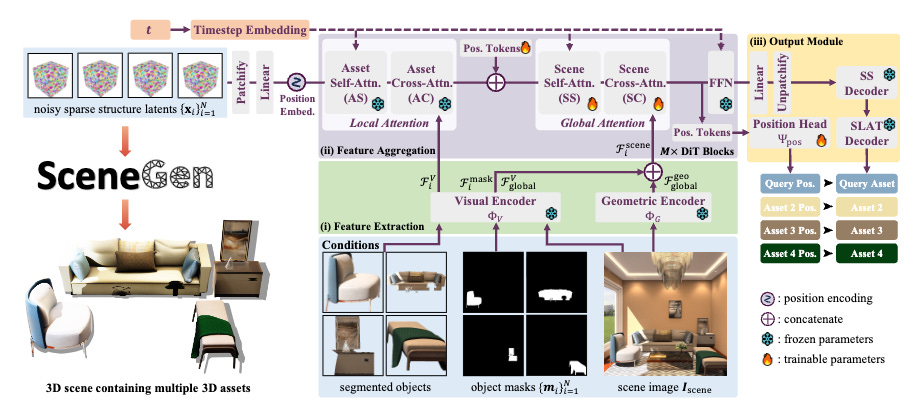
SceneGen: Single-Image 3D Scene Generation in One Feedforward Pass
https://arxiv.org/abs/2508.15769 | GitHub
SceneGen generates multiple 3D assets from a single scene image and object masks in one forward pass. The system handles spatial reasoning by understanding how objects relate to each other in 3D space rather than generating them in isolation. This addresses a key bottleneck in 3D content creation by eliminating the need for iterative optimization algorithms.
A Survey on Large Language Model Benchmarks
https://arxiv.org/abs/2508.15361
This survey analyzes 283 LLM benchmarks and identifies critical flaws in current evaluation methods. The authors document how data contamination inflates performance scores, cultural biases create unfair comparisons, and most benchmarks fail to evaluate model behavior in dynamic environments. Beyond cataloging problems, they provide a design framework for building more reliable evaluation systems. This explains why benchmark performance often doesn't translate to real-world utility.

🎥 4 Videos
How Amplitude built an internal AI tool that the whole company's obsessed with (and how you can too)
Wade Chambers details how Amplitude built Moda, an internal AI assistant that integrates with all company data sources. Rather than another general-purpose chatbot, Moda helps teams move from customer feedback analysis to working prototypes within single meetings. The organizational insights matter more than the technical architecture: how they secured company-wide adoption, managed complex data integration, and use cross-functional role-swapping exercises to build AI literacy across teams.
Five hard-earned lessons about Evals
Ankur Goyal examines evaluation frameworks that work reliably in production. He addresses why traditional metrics often mislead, how to design evaluations that capture real failure modes, and practical approaches to continuous evaluation. The focus is on lessons from production deployments rather than theoretical frameworks, since moving from prototype to production typically reveals that evaluation strategy determines success more than model choice.
Building and prototyping with Claude Code
This official guide demonstrates effective workflows for collaborative coding with Claude Code. Success depends on providing proper context about your codebase rather than treating Claude as a generic code generator. The video covers context management techniques, coordinating multiple Claude sessions, and transitioning from exploratory coding to production implementations.
DeepMind Just Made The Most Powerful Game AI Engine!
DeepMind's latest game AI demonstrates advances in multi-agent coordination with broader applications beyond gaming. The techniques for real-time decision making and collaborative planning apply directly to robotics, autonomous systems, and scenarios requiring multiple AI agents to work together effectively. Károly explains complex multi-agent dynamics clearly while highlighting practical implications.
📰 3 Curated Reads
GPT-oss from the Ground Up

Cameron R. Wolfe, Ph.D. examines OpenAI's first open-weight models since GPT-2, analyzing architectural changes, training methodologies, and performance characteristics. His breakdown reveals how leading labs actually iterate on transformer designs versus what they publish in papers. You'll discover why some of the most important improvements never make it into academic publications.
Context Engineering: 2025's #1 Skill in AI

Paul Iusztin argues that context engineering - systematically providing AI systems with relevant information - matters more than prompt engineering for production AI applications. The article covers practical frameworks for context design, memory management in extended conversations, and maintaining coherence across multi-step tasks. Examples range from chatbot architecture to agentic workflows, showing how to move from brittle prompt-based solutions to robust systems that handle context limitations effectively.
How to develop the most important skill for AI

Devansh focuses on developing intuition for AI capabilities and limitations, recognizing when AI solutions fit specific problems, and iterating productively when they don't. The frameworks address transitioning from deterministic software thinking to working with probabilistic, emergent AI behaviors. Helpful for practitioners adapting their problem-solving approaches to AI systems that behave fundamentally differently from conventional software.
🛠 2 Tools & Repos
Arxiv-paper-curator
https://github.com/jamwithai/arxiv-paper-curator
This automated system discovers and curates relevant papers from ArXiv using semantic similarity to identify papers worth reading and generate summaries. Instead of manually reviewing hundreds of daily submissions, you receive personalized recommendations aligned with your work. Particularly useful for researchers tracking developments across multiple subfields.
Go checkout Shantanu Ladhwe and Shirin Khosravi Jam. They’re building this project (and teaching, too). Give them a follow.
LLM Course
https://github.com/mlabonne/llm-course
Maxime Labonne's course covers LLM development from mathematical foundations to production deployment. The curriculum includes practical notebooks, theoretical explanations, and hands-on projects that mirror real-world applications. The course balances mathematical rigor with implementation details, suitable for both newcomers seeking foundational understanding and practitioners deepening their knowledge of language modeling techniques.
🎓 1 Pick of the Week
Why your AI product needs a different development lifecycle

Aishwarya Naresh Reganti and Kiriti Badam examine why traditional software development methodologies fail when applied to AI products. They outline how standard agile practices struggle with non-deterministic systems, provide frameworks for structuring AI product teams, and offer practical approaches for managing uncertainty in AI-driven features. The article covers evaluation strategies, user research methodologies, and iteration cycles designed specifically for AI systems.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.