



Tokenizers with Karpathy, Flexible Transformers for Diffusion, Speculative Streaming, AnyGPT and more...
A round up of the most interesting resources from the week gone by

These are some of the most interesting resources I found over the past week covering a range of topics in computer vision and NLP.
AnyGPT: A Unified Multimodal LLM
AnyGPT addresses the challenge of unifying speech, text, images, and music processing via a single model using discrete representations. It achieves this exclusively through data-level preprocessing, avoiding changes to model architecture or training techniques. The model is trained on a multimodal text-centric dataset and performs on par with modality-specific models. Check out some of the demos on the project page.

Speculative Streaming for Fast LLM Inference
This paper from Apple introduces Speculative Streaming, a method for accelerating Large Language Model (LLM) inference without relying on auxiliary models (unlike Speculative Decoding). It integrates the drafting process directly into the target model through a unique fine-tuning objective that predicts future n-grams (instead of just the next token), achieving a significant speed increase of 1.8x to 3.1x across various tasks. This efficiency comes without compromising on generation quality and is ideal for use on devices with limited computational capacity.

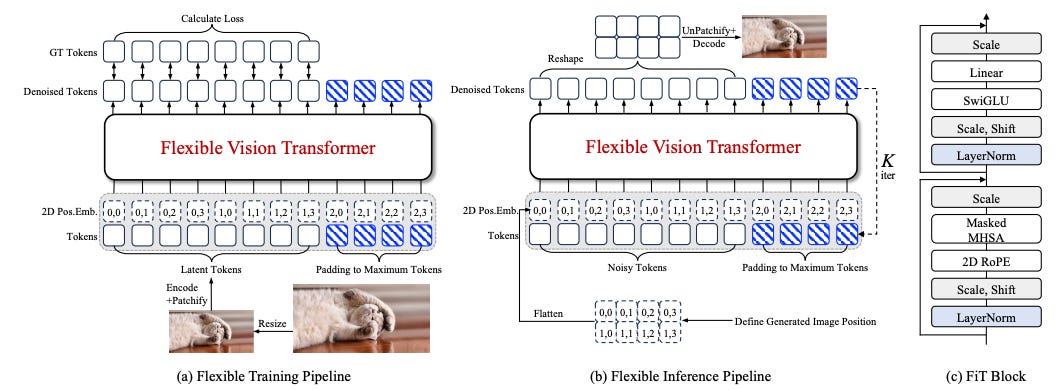
FiT: Flexible Vision Transformer for Diffusion
Flexible Vision Transformer (FiT) generates images with variable resolutions and aspect ratios, overcoming the limitations of existing diffusion models. FiT views images as sequences of dynamically sized tokens, allowing for adaptable training and inference across different aspect ratios. This method enhances resolution generalization and avoids biases from image cropping. The model checkpoint is available in the link above.
New Merging Methods in PEFT
The Hugging Face team has introduced new methods for merging model "adapters," specifically, LoRA adapters within the PEFT framework. This blog post outlines various merging techniques such as concatenation, linear/task arithmetic, SVD, TIES, and DARE and provides insights into the practical applications of these merging techniques.
GaussionObject: Just 4 Images for a High-Quality 3D Object
GaussianObject is a Gaussian splatting framework for 3D object reconstruction using just four images. It tackles the challenges of multi-view consistency by employing visual hull and floater elimination techniques for initial structure prediction. Next, it constructs a Gaussian repair model to refine and complete the 3D representation. GaussianObject significantly surpasses previous SoTA methods on various benchmarks.
LLM Comparator: Side-by-Side Evaluation of LLMs
The LLM Comparator from Google is a visual analytics tool designed for the side-by-side evaluation of Large Language Models. It facilitates interactive analysis of automatic evaluation results, helping users understand model performance differences and qualitative variations in response. While the paper mentions an observational study confirming LLM Comparator’s utility for model evaluators, it's unclear when and if the tool will be made available for users.

Building a Tokenizer with Karpathy
In this video, Andrej Karpathy covers the ins and outs of byte-pair tokenization used in the GPT series of models. This is a must-watch for anyone learning to work hands-on with LLMs. After all, tokenization is a crucial step in LLM data preprocessing.
Engineering Practices for LLM Application Development
This article discusses engineering practices for developing applications with Large Language Models (LLMs). It covers the importance of prompt engineering, automated testing, and addressing ethical considerations. The authors share insights from their project experience, emphasizing testing strategies, prompt refactoring, and the significance of foundational software engineering principles.