

Training World Class LLMs, Google's Agent Starter Pack, and Fei Fei Li on AI's Evolution: The Tokenizer Edition #8
This week's most valuable AI resources

Hey there! Model distillation just got smarter with adversarial training that makes student models competitive, and the Depth Anything team pushed visual geometry to new heights with a simplified transformer approach. Sometimes the best progress comes from making things simpler, not more complex.
By the way, you may have noticed that there wasn’t a newsletter in your inbox last week. That’s because I was away giving a talk on Vision Language Models at the Google Developer Group’s DevFest 2025 conference at IIT Madras.

I had a ton of fun answering questions and got to meet so many of the Gradient Ascent community in person. I hope to catch more of you in person in future talks and events.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best papers, videos, articles, tools, and learning resources from across the AI landscape. Consider it your weekly dose of everything you need to stay ahead in machine learning.
TL;DR
What caught my attention this week:
📄 Papers: Adversarial distillation reaching proprietary model performance, visual geometry models setting new benchmarks, and efficient latent-space upscaling for diffusion models
🎥 Videos: Physics-based rendering breakthroughs, transformer architecture deep dives, and practical approaches to ML library testing
📰 Reads: Fei-Fei Li on AI’s evolution from words to worlds, scaling laws for reinforcement learning, and accessible PPO explanations
🛠 Tools: Google’s comprehensive agent starter kit and scalable diffusion language modeling
🎓 Learning: HuggingFace’s complete playbook for training small language models from scratch
Grab my first book — AI for the Rest of Us — today!
It’s been a whirlwind two weeks since the book’s launch and so many of you have sent me pictures of the book in your hands. Thank you so much!!
In fact, the book hit #2 on Amazon’s new releases in the software books category.
If you find the book useful, please leave a review on Amazon. It makes a world of difference. If you have a picture of the book IRL, please share it with me. I really appreciate it.

📄 5 Papers
Black-Box On-Policy Distillation of Large Language Models
https://arxiv.org/abs/2511.10643 | GitHub
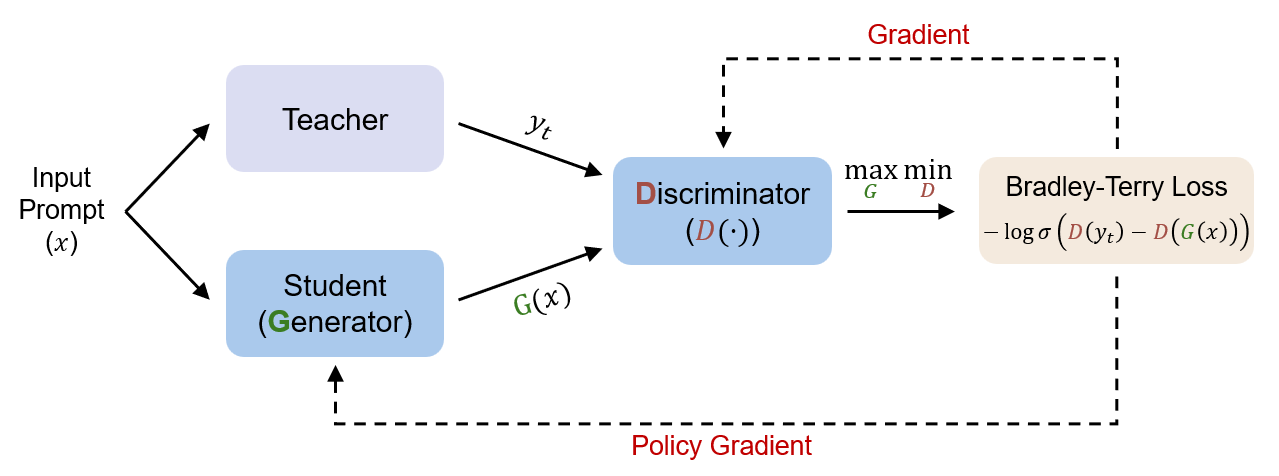
Distilling knowledge from proprietary models usually means settling for worse performance because you only get text outputs, not internal logits. Microsoft’s Generative Adversarial Distillation (GAD) changes this by training a discriminator to distinguish student responses from teacher outputs, creating a minimax game where the student learns to fool the discriminator. The discriminator acts as an on-policy reward model that evolves alongside the student, providing stable feedback throughout training. Qwen2.5-14B-Instruct trained with GAD matches its teacher GPT-5-Chat on LMSYS-Chat evaluation, proving you can reach proprietary model performance through black-box distillation alone.
Depth Anything 3: Recovering the Visual Space from Any Views
https://arxiv.org/abs/2511.10647 | GitHub
Depth Anything 3 achieves state-of-the-art visual geometry from arbitrary viewpoints using surprisingly minimal architecture. A vanilla DINO encoder handles everything without specialized modifications, and a single depth-ray prediction target eliminates complex multi-task learning. The model surpasses prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy while outperforming Depth Anything 2 in monocular depth estimation. Training exclusively on public academic datasets, DA3 demonstrates that architectural simplicity paired with smart training paradigms outperforms specialized complexity for visual geometry tasks.
One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
https://arxiv.org/abs/2511.10629
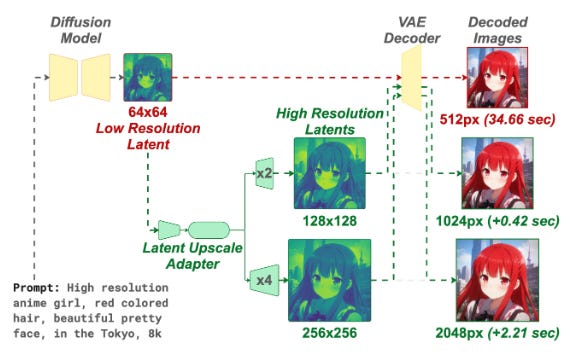
Diffusion models struggle with high-resolution generation because direct sampling is slow and post-hoc upscaling introduces artifacts. The Latent Upscaler Adapter (LUA) performs super-resolution directly on latent codes before VAE decoding, integrating as a drop-in component requiring zero modifications to base models. A shared Swin-style backbone with scale-specific pixel-shuffle heads supports both 2x and 4x upscaling, adding only 0.42 seconds for 1024px generation from 512px compared to 1.87 seconds for pixel-space super-resolution. LUA generalizes across different VAE latent spaces without retraining, making deployment straightforward regardless of which decoder you’re using.
Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
https://arxiv.org/abs/2510.19338
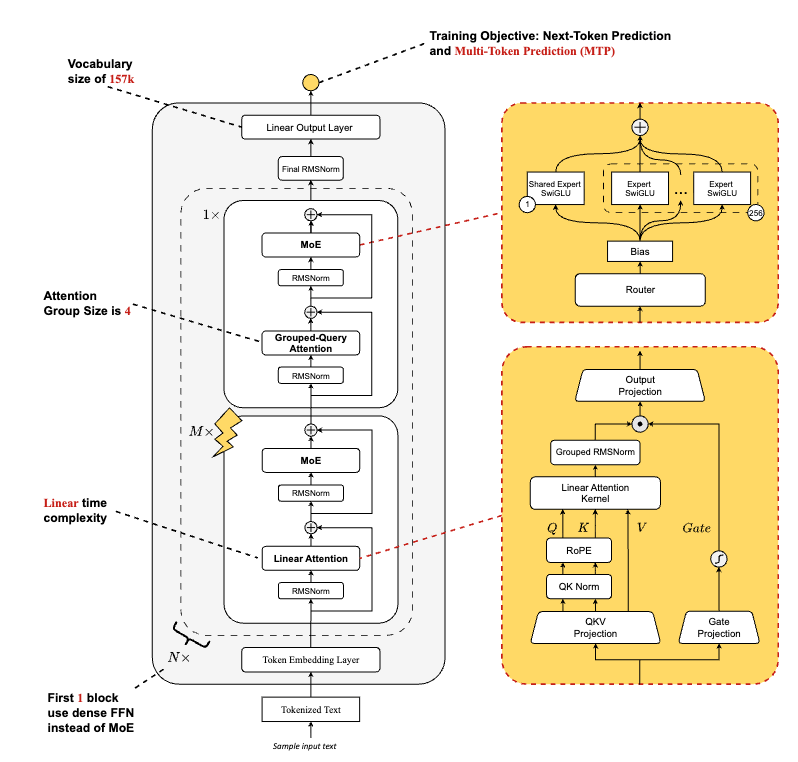
The Ring-linear model series combines linear attention and softmax attention to slash long-context inference costs. Ring-mini-linear-2.0 (16B parameters, 957M activations) and Ring-flash-linear-2.0 (104B parameters, 6.1B activations) reduce inference cost to 1/10 compared to 32B dense models. Through systematic exploration of attention mechanism ratios, they identified optimal hybrid architecture structures that maintain SOTA performance across challenging reasoning benchmarks while leveraging their FP8 operator library for 50% training efficiency gains. The models undergo stable long-term optimization during reinforcement learning phases due to high alignment between training and inference operators.
GigaBrain-0: A World Model-Powered Vision-Language-Action Model
https://arxiv.org/abs/2510.19430 | GitHub
Physical robot data collection bottlenecks VLA model development, so GigaBrain-0 uses world models to generate diverse training data at scale through video generation, real2real transfer, human transfer, view transfer, and sim2real techniques. This dramatically reduces reliance on expensive real robot data while improving cross-task generalization. RGBD input modeling and embodied Chain-of-Thought supervision enable the model to reason about spatial geometry, object states, and long-horizon dependencies during execution. GigaBrain-0 achieves superior generalization across appearance variations, object placements, and camera viewpoints for dexterous, long-horizon, and mobile manipulation tasks, with GigaBrain-0-Small optimized for NVIDIA Jetson AGX Orin deployment.
You’ll Never Look At Chocolate TV Ads The Same Way Again
Károly from Two Minute Papers explores physics-based rendering advances that make digital chocolate indistinguishable from the real thing. The techniques behind realistic material simulation and light transport have commercial applications beyond advertising, affecting everything from product visualization to virtual production. Worth watching to understand how far physically-based rendering has come and where computational photography is heading.
LLM Building Blocks & Transformer Alternatives
Sebastian Raschka breaks down the fundamental components that make language models work, then examines emerging alternatives to standard transformer architectures. His systematic approach covers why certain architectural choices matter for training efficiency, inference speed, and model capabilities. Useful for anyone building models or evaluating which architectures suit specific use cases.
Designing Tests for ML Libraries
Testing machine learning libraries requires different strategies than traditional software because of probabilistic outputs and numerical precision issues. This practical guide covers approaches for ensuring your ML code behaves correctly across edge cases, different hardware configurations, and varying input distributions. Essential viewing for anyone maintaining production ML infrastructure or contributing to open-source frameworks.
Recursive Language Models
This exploration of recursive structures in language models examines how models can learn to call themselves iteratively to solve complex reasoning tasks. The approach offers alternatives to chain-of-thought prompting by building recursion directly into model architecture and training. Helpful for understanding emerging approaches to multi-step reasoning beyond standard autoregressive generation.
📰 3 Curated Reads
From Words to Worlds

Fei-Fei Li contends that spatial intelligence, which is the ability for AI to perceive, reason about, and interact with the 3D world, is the pivotal next step for artificial intelligence. Her essay highlights the need for world models that can build, simulate, and understand consistent environments, expanding AI’s impact across creativity, robotics, science, and human-centered applications.
How to Scale RL

Nathan Lambert examines emerging scaling laws for reinforcement learning, challenging assumptions that RL doesn’t scale like supervised learning. The analysis covers what factors actually drive RL performance improvements, from compute allocation to data diversity. Critical reading as RL becomes more central to post-training for language models and robotics applications.
PPO for LLMs: A Guide for Normal People

Cameron R. Wolfe, Ph.D. demystifies Proximal Policy Optimization for language model training without assuming you have a PhD in reinforcement learning. His breakdown covers why PPO became the standard for RLHF, what the core mechanisms actually do, and how to think about the algorithm’s behavior during training. An accessible guide that translates complex ideas into clear, actionable insights and showing how PPO underpins contemporary LLM alignment practices.
🛠 2 Tools & Repos
Agent Starter Pack
https://github.com/GoogleCloudPlatform/agent-starter-pack
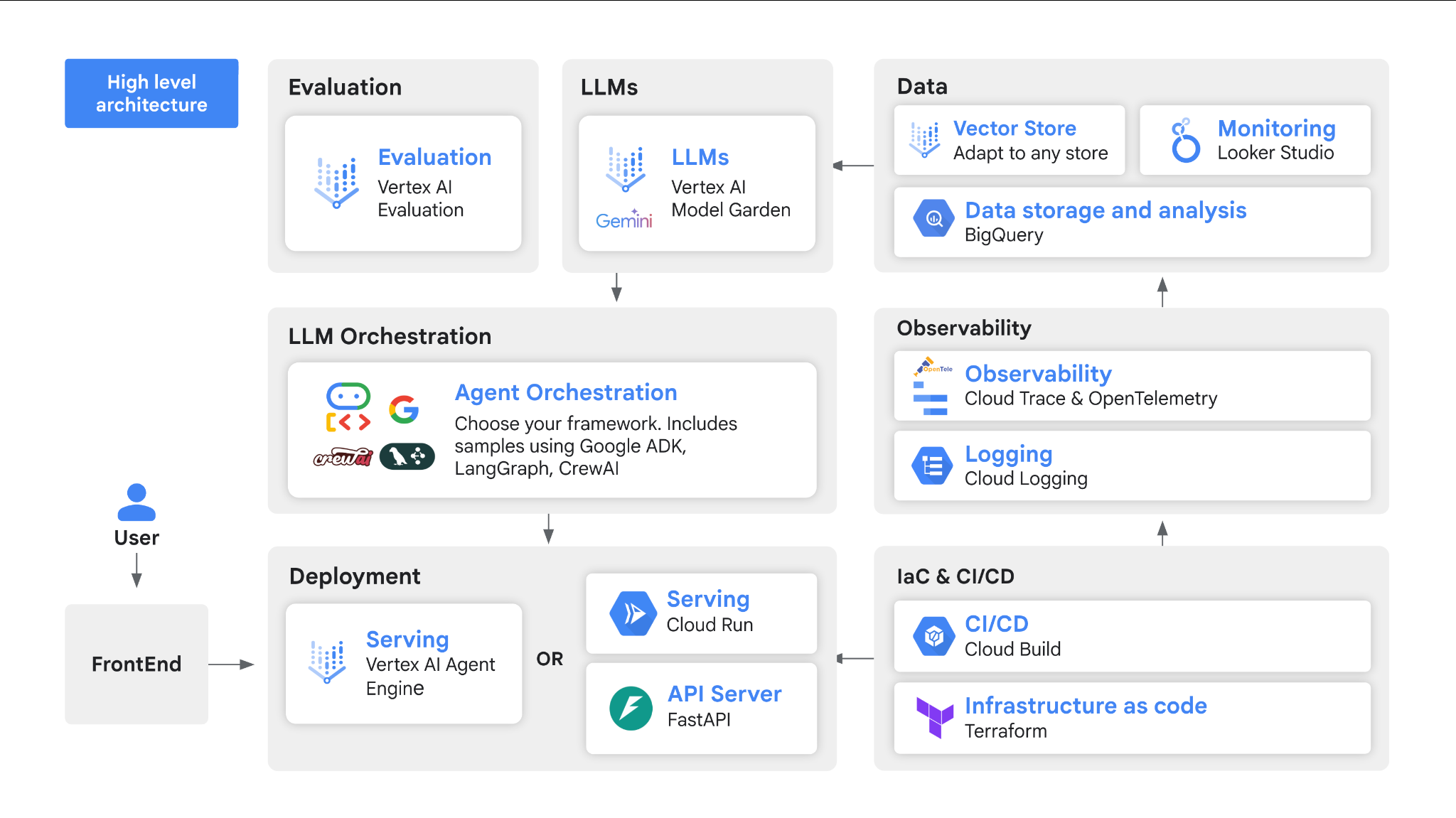
Google Cloud’s comprehensive toolkit for building production AI agents covers everything from basic scaffolding to deployment patterns. Instead of starting from scratch, you get tested implementations of common agent workflows, integration templates for external tools, and best practices for managing agent state. The repository focuses on patterns that work reliably in production rather than experimental approaches.
Simple Diffusion Language Modeling
https://github.com/ZHZisZZ/dllm

This implementation demonstrates diffusion models applied to language generation, offering an alternative to standard autoregressive approaches. The clean codebase makes it easier to understand how diffusion processes work for discrete tokens and experiment with different training strategies. Useful for researchers exploring non-autoregressive generation methods or looking to understand diffusion model fundamentals.
🎓 1 Pick of the Week
The Smol Training Playbook
https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook

HuggingFace’s complete guide to training small language models efficiently covers everything from data preparation through final evaluation. The playbook synthesizes lessons learned from training the SmolLM series, including which architectural choices matter most at smaller scales, how to optimize training compute, and which evaluation benchmarks actually predict downstream performance. Particularly valuable if you’re training models under 2B parameters where established practices for larger models don’t always apply. The guide includes specific hyperparameter recommendations, dataset mixing strategies, and ablation studies showing what works versus what doesn’t at small scale.
Thanks for reading The Tokenizer! If you found something useful here, share it with someone who might benefit. And if you want more curated insights like this, consider subscribing to Gradient Ascent.