

Tsinghua's Multi-Agent AI Classroom, Anthropic's Context Engineering Playbook, and a 54 LLM-Architecture Gallery - 📚 The Tokenizer Edition #22
This week's most valuable AI resources

Hey there! Video generation went from “impressive demo” to “real-time streaming” this week, with three papers pushing interactive and long-form video into practical territory. Meanwhile, the tooling side caught up too, with Anthropic publishing one of the clearest guides yet on how to keep long-running agents from drowning in their own context.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: Streaming video generation hits 16 FPS, speculative sampling gets task-aware, and an autonomous medical AI scientist passes peer review
🎥 Videos: Sebastian Raschka maps 54+ LLM architectures, TurboQuant compresses KV cache to 3.5 bits, and two practical Claude Code tutorials
📰 Reads: Ethan Mollick on why AI interfaces matter more than models, Cameron Wolfe dissects LLM benchmarks, and Anthropic’s three primitives for context management
🛠 Tools: A biomimetic agent memory system with retain/recall/reflect, and an autonomous pentester that proves vulnerabilities with working exploits
🎓 Learning: Tsinghua’s multi-agent AI classroom turns any topic into an interactive lesson with AI teachers, students, and a shared whiteboard
📄 5 Papers
1. ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
https://arxiv.org/abs/2603.25746 | GitHub
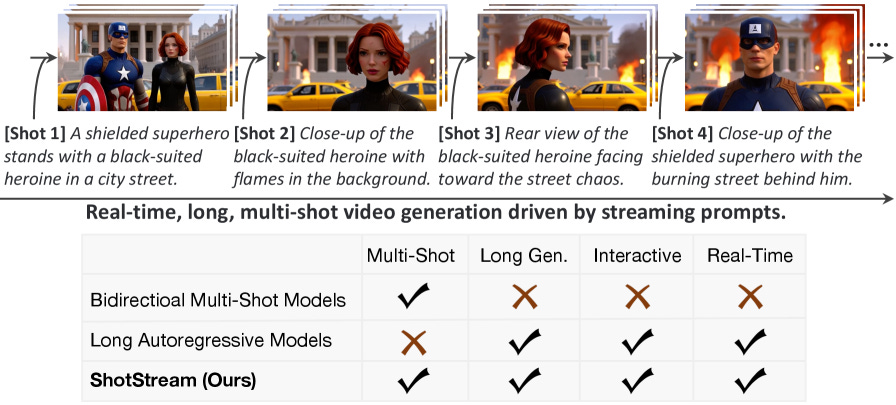
Real-time multi-shot video generation that maintains character consistency across scene transitions. ShotStream introduces a causal architecture with dual-cache memory (global context for inter-shot consistency, local context for intra-shot coherence) that enables ~16 FPS streaming, a 25x throughput improvement over bidirectional approaches. From the Kling AI Research team, this is the first system that makes interactive video storytelling feel responsive enough for real-time use.
2. Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models (HyDRA)
https://arxiv.org/abs/2603.25716 | GitHub
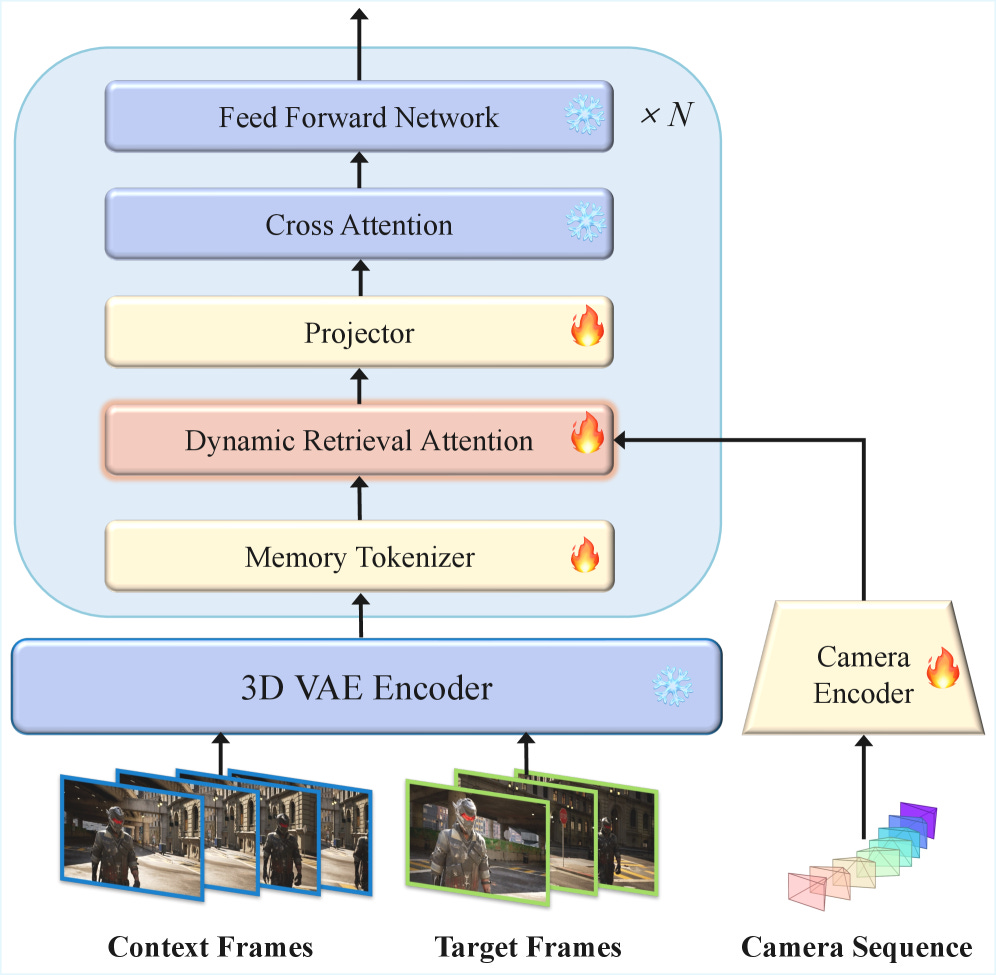
Video world models lose track of objects the moment they disappear behind something. HyDRA fixes this with a hybrid memory system that separates archival storage (for static scenes) from working memory (for active, occluded objects). The result: +5.5 PSNR improvement over commercial systems like WorldPlay on a new Dynamic Object Tracking benchmark. Also ships HM-World, the first large-scale video dataset dedicated to hybrid memory evaluation with exit-entry occlusion events.
3. TAPS: Task Aware Proposal Distributions for Speculative Sampling
https://arxiv.org/abs/2603.27027 | GitHub
Speculative decoding’s dirty secret: generic draft models waste tokens because they don’t match the downstream task distribution. TAPS trains task-specific draft models that align with the target model’s behavior on actual workloads, yielding ~26% acceptance length improvements over general-purpose drafters. Practical and immediately applicable if you’re running speculative decoding in production.
4. Towards a Medical AI Scientist
https://arxiv.org/abs/2603.28589
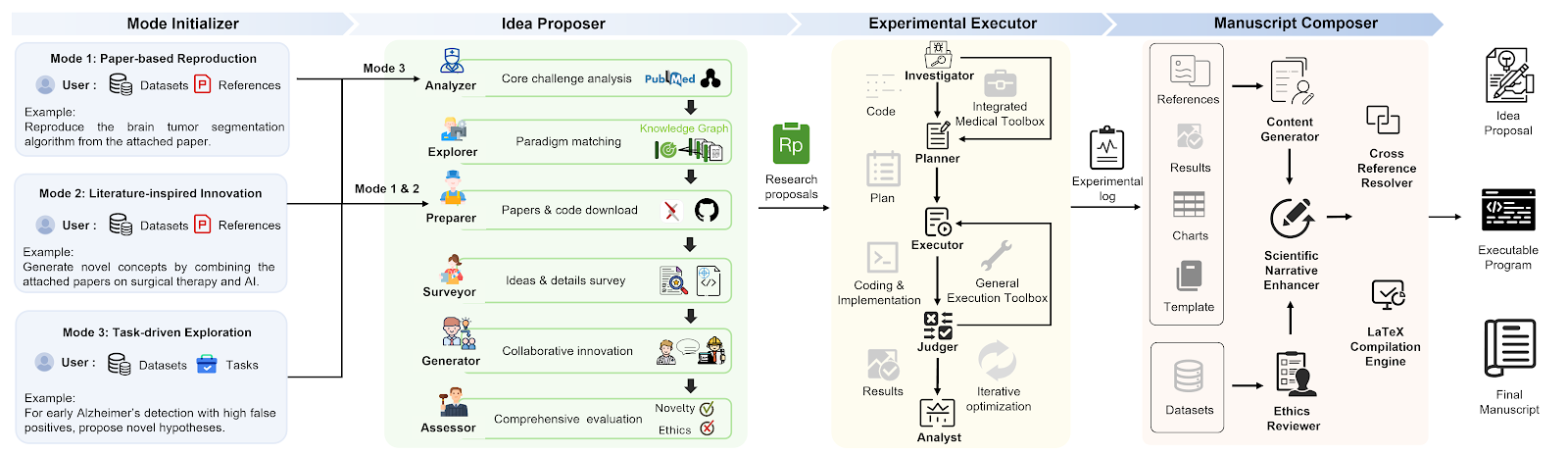
An autonomous research framework that generates clinical hypotheses, designs experiments, executes analyses, and writes papers. The system achieved 91% execution success rate versus GPT-5’s 60%, and one of its generated papers was accepted at ICAIS 2025 (36.8% acceptance rate). This is a concrete step toward AI that does science, not just assists with it.
5. PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
https://arxiv.org/abs/2603.25730 | GitHub
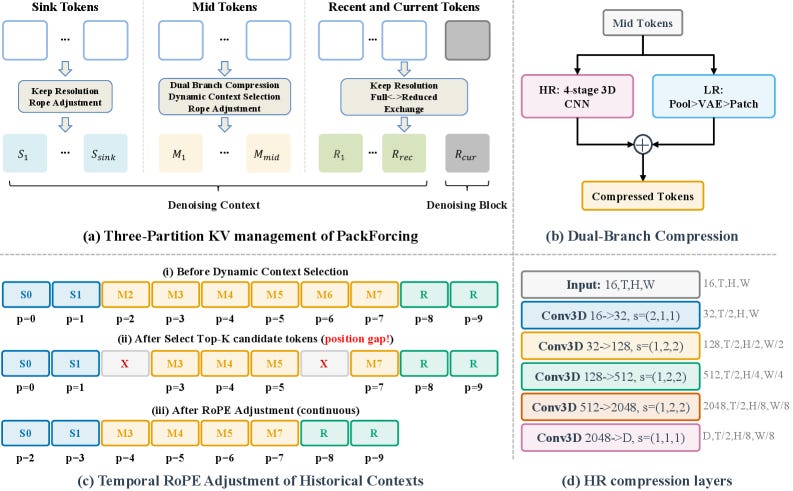
Training on long videos is expensive. PackForcing shows you don’t need to. By introducing hierarchical KV-cache management with a bounded 4GB memory budget, it achieves 24x temporal extrapolation: models trained on short clips generate coherent long videos. The spatiotemporal compression maintains temporal consistency while keeping inference memory constant regardless of video length.
🎥 4 Videos
1. 54+ LLM Architectures and 7 Attention Variants in One Visual Gallery
A visual map of how LLM architectures evolved from GPT-2 (2019) to Kimi K2.5 (2026), covering 54+ models from 270M to 1T parameters. The 38-minute deep dive compares 7 attention variants: standard MHA, Grouped-Query, Sliding-Window, Multi-Head Latent (DeepSeek’s MLA), Sparse, Gated, and Hybrid. Sebastian Raschka built the companion Architecture Gallery as an open resource, and this walkthrough is how you actually learn to read it.
2. TurboQuant: Compressing KV Cache to 3.5 Bits Per Channel
Random rotation plus scalar quantization can compress KV cache vectors to near-optimal distortion at 3.5 bits per channel. That’s the core of Google’s TurboQuant paper, broken down here by Karoly Zsolnai-Feher (Two Minute Papers). The practical result: cheaper LLM inference through aggressive cache compression without meaningful quality loss, with community review context and reproduction attempts included.
3. Building a Mobile Fitness App with Claude Code and Pencil in 16 Minutes
A three-phase workflow for building mobile apps without coding: define requirements conversationally, generate 8 UI screens with Pencil (pencil.dev), then build the working app with Claude Code. Peter Yang takes it from blank screen to a fitness tracker running on iOS via Expo Go in 16 minutes. Covers workout creation, live session tracking, calendar progress, and the path to App Store deployment.
4. The “Recording Mode” Trick for Privacy-Safe Claude Code Demos
A 2-minute clip with a clever idea: instead of maintaining separate anonymized demo environments, create a Claude Code skill called “recording on” that intercepts and anonymizes personal information in real-time. It tracks consistent mappings (person A stays person A), toggles on and off with zero friction, and works for B2B demos where you need to show live production data without exposing customer names or financial details.
📰 3 Curated Reads
1. Claude Dispatch and the Power of Interfaces

Ethan Mollick (Wharton) argues the gap between AI capability and actual user experience is an interface problem, not a model problem. Current chatbot UIs impose cognitive costs that overwhelm productivity gains, particularly for less experienced workers. Three paths forward: specialized professional tools (the coding IDE model), meeting users on familiar platforms (WhatsApp, Slack), and dynamic interfaces where AI generates the right UI on the fly. Includes hands-on demos of Claude Dispatch and Cowork.
2. The Anatomy of an LLM Benchmark

LLM benchmarks break in predictable ways: MMLU has a 6.49% error rate (Virology hits 57%), and correcting those errors moved Llama-3.1-405B from 16th to 1st. Cameron Wolfe (Deep Learning Focus) maps the full lifecycle of how benchmarks are designed, saturate, and get replaced. The standout section covers Item Response Theory, which cuts evaluation costs 140-160x by selecting only the most informative test items.
3. Context Engineering for AI Agents: Memory, Compaction, and Tool Clearing
https://platform.claude.com/cookbook/tool-use-context-engineering-context-engineering-tools
Three composable primitives for managing context in long-running agents, each targeting a different type of bloat. Clearing drops re-fetchable tool outputs at zero inference cost (peak context: 173K tokens vs. 335K baseline). Compaction summarizes conversation history (169K peak, lossy). Memory persists knowledge across sessions by letting the agent write its own notes. Isabella He (Anthropic) includes a diagnostic framework: profile your agent’s token breakdown first (in the demo, 96.3% of tokens were stale file-read results), then pick the primitive that matches.
🛠 2 Tools & Repos
1. Hindsight
https://github.com/vectorize-io/hindsight

Agent memory that goes beyond conversation history. Hindsight provides three API primitives (retain, recall, reflect) that let agents learn, retrieve, and synthesize knowledge over time. Recall runs four parallel strategies (semantic, keyword, graph, temporal) with cross-encoder reranking. The reflect API generates new insights from existing memories, not just retrieval. SOTA on LongMemEval, 6.8K GitHub stars, MIT license, works with any LLM provider, and deploys via Docker or as an embedded Python library.
2. Shannon
https://github.com/KeygraphHQ/shannon

An autonomous AI pentester that reads your source code and executes real exploits against the running app. It builds a Code Property Graph to trace data flows from user input to dangerous sinks, then attacks those paths. Every reported vulnerability comes with a working proof-of-concept, not theoretical findings. Handles authentication complexity including 2FA/TOTP flows.
🎓 1 Pick of the Week
OpenMAIC: Tsinghua’s Multi-Agent AI Classroom
https://github.com/THU-MAIC/OpenMAIC

Type “teach me Python in 30 minutes” and OpenMAIC generates a full interactive classroom: slides with narration, quizzes with real-time grading, interactive HTML simulations, and AI agents playing teacher and student roles who lecture, discuss, and draw on a shared whiteboard. Built on LangGraph with a director agent that orchestrates turn-taking, it supports uploading PDFs for document-to-course conversion. 13.6K stars in three weeks, live demo at open.maic.chat, and the LangGraph-based multi-agent orchestration pattern is a reusable blueprint beyond education.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.