

Understanding Large Language Models

Take a look at this Twitter thread by productivity Youtuber Ali Abdaal:
At first glance, nothing seems awry and by the looks of it, it seems to be a really popular thread. Here's the catch - It was almost entirely written by a large language model (LLM) pretending to be him. In fact, it did such a good job that it got over 1 million views and nearly 25k engagements shortly after it was published.
If your immediate thought is "Does this mean AI is coming for our jobs?", don't worry. It's not quite there. Yet.
The model that wrote Ali's thread is called GPT-3 (Generative Pretrained Transformer). With no context of his personality, other than a few words that he entered to get it started, it promptly churned out a pro twitter thread most of us might be proud of.
Unveiled by OpenAI in July 2020, GPT-3 might be the most well-known LLM given how widespread it has become, but there is an entire family of these models that are just as capable if not more. For example, Google uses one of these in its search engine. That's right. If you googled something today, you harnessed the power of an LLM called BERT (Bidirectional Encoder Representations from Transformers). I remember reading somewhere that specific search results improved by 7% since Google started using it. Baidu uses another of these species called ERNIE in their online products and services.
I can sense a lot of questions in your mind - "Why are these called Large language models?", "How do they work?", and most importantly, "Why do they remind me of Sesame Street?". I'll try to break these down in the next few sections. Yes, the Sesame street question too.
What are LLMs?
Large language models are neural networks based on a specific breakthrough from 2017, the Transformer (no pun intended). The reason they are large is because a) They are several gigabytes in size and b) They are trained on enormous (petabyte scale) datasets. These models have billions of parameters. Think of parameters like knobs that a model can tweak to learn things. Therefore, the more knobs it has, the more complex representations it can learn. Over time, these models have become larger and larger, and have also become significantly more powerful.
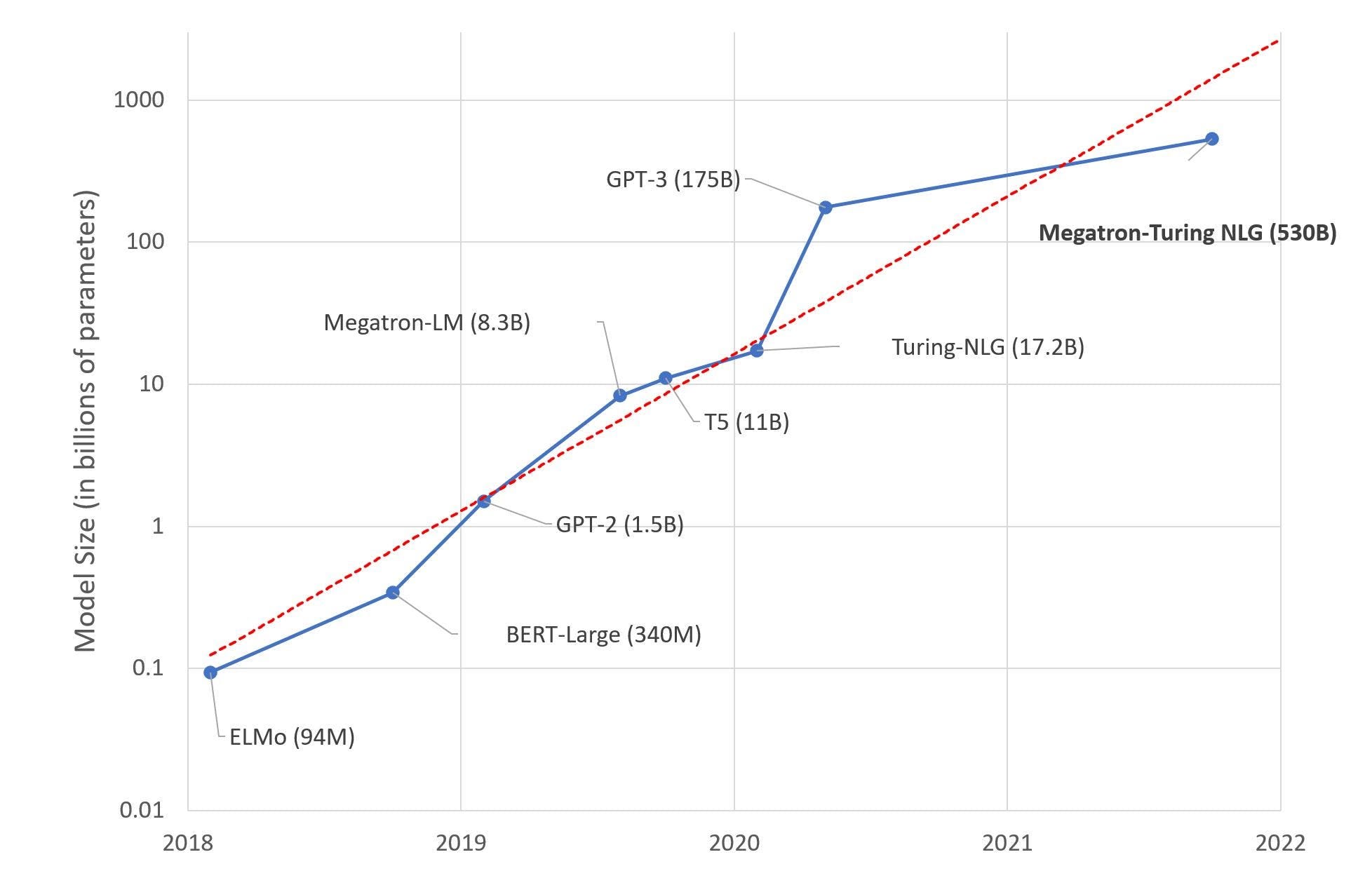
So we know why they're called large language models. Are they really such a big deal? Well, kind of. They can do everything from writing essays, creating charts, and writing code (yup, scary), with limited or no supervision. Fundamentally though, all they are trained to do is predict the next word in a sentence - Yes, similar to autocomplete on your phone. So why do you need a large model and datasets for something this trivial? Let's look at that next.
Why are they large?
Imagine you have a magic mouse (I did say imagine). By showing it examples of 5 tasks that you want done, no matter how difficult or different, you can train it to be a world-class expert at them. You don't need to show a lot of examples. Just a few will suffice. How awesome would that be?
Now imagine that you are given a magic cow. This cow can do the same 5 tasks that your magic mouse can, but better. Also, it can do 5 more new tasks that the mouse can't do. Even better right?
Humor me once more and imagine that the gods have bestowed upon you a magic dinosaur. This can one-up the cow (duh it's morphin time ) and do even better on the 10 tasks that the cow could do and do another 5 new ones. Do you see where I'm going with this?
LLMs are remarkable because a single model can be used for several tasks. As the size of the model increases (in parameters), it can learn more complex representations, and, therefore can do more tasks better than a smaller model. What's more, they can learn new tasks from just a handful of examples. These tasks can be any of the things I mentioned before and more! That's why researchers are trying to scale these models up.
The natural question that emerges next is how on earth do these models learn.
How do they learn?
These models learn in two stages - Pretraining and fine-tuning.
Pretraining
In the pretraining stage, the goal is to teach the model the semantics, structure, and grammar of language by showing it a lot of examples (think billions). As is the case with machine learning, we simply show examples to the model and let it learn the rules by itself.
Pretraining is the longest and most computationally expensive part of the learning process. A model is shown examples over and over again and eventually learns the rules. So, how does it learn?
Here are a couple of common pre-training methods used in practice today:
What comes next in the sentences below?

This is how the GPT family of models are pretrained. Given a partial sentence, they have to predict the next word in the sentence and then the next, and so on. Even though we may have a full sentence that we can show the model, we don't. This prevents the model from cheating and looking into the next set of words that may occur in the sentence.
Fill up the blanks in the sentences below

You might have had luck guessing the first two, but the third might be tricky. This is called masked language modeling. In this approach, we randomly blank out words in a sentence and have the model guess what those words might be. Unlike the previous approach, we present a full (but blanked out) sentence to the model so it can learn from words on either side of the blanks. Models like BERT are pre-trained using this approach.
By doing this over and over again on a ridiculously large dataset, these models learn rich representations of language. But of what use is that if it can't be put into a practical application?
That's where fine-tuning comes in.
Fine-tuning
In the fine-tuning phase, we can take a pretrained model and show it examples of the task we want it to solve. This can be question answering (who is Neil Armstrong?), sentiment analysis (was that tweet mean?), conversation, and so on. This stage usually takes much lesser time and data compared to the pretraining phase which is why these pretrained models are invaluable.
But that raises the question - "Where do you get all that data for pretraining?"
What do they learn from?
If you take all the books in the world, all of Wikipedia, and all of the text you can get by crawling the web and ingesting that knowledge, how smart would you be? Well, that's what these models are fed. In the pretraining phase, these models are trained on all of these datasets (amounting to just short of the collective human consciousness). That's another reason why they are large by design. Smaller models are limited in what they can learn. In the fine-tuning phase, smaller in-house datasets relevant to your application are used.
Where do we go from here?
LLMs have some limitations though. First, only a few well-funded organizations can train these models since they need so much compute (hundreds of thousands of dollars). Second, they aren't as eco-friendly since the energy it takes to train these models amounts to several years of your electricity bill. More importantly, these models are trained on information contained on the internet. That means that they can be biased, learn toxic things, and much more. Given how good they are at writing, the spread of disinformation is a big worry. Thankfully, researchers across the globe are working on addressing these issues.
That's the ELI5 version of LLMs for you. Finally, I haven't yet told you about the Sesame Street connection. Well, here you go.