

Vercel's Agent Framework, Netflix's Generative Homepage, and a Repo That Writes Less Code: The Tokenizer Edition #33
This week's most valuable AI resources

Hey there! Netflix now builds its entire homepage with one model and serves it about 20% faster than the pipeline it replaced. The best coding agents still can’t finish a playable game more than 41% of the time. And one of the fastest-growing repos on GitHub exists to make your agent write less code, not more. Let’s dig in.
New here?
The Tokenizer is my resource-focused newsletter edition where I curate the best AI/ML papers, videos, articles, tools, and learning resources so you don’t have to sift through the noise. Subscribe to Gradient Ascent for the full experience.
TL;DR
What caught my attention this week:
📄 Papers: A spec compiled straight into runnable weights, a bounded-memory testbed that keeps long agent runs from drowning in their own transcript, a world model that loops one block instead of adding parameters, a diffusion LLM that teaches itself, and a benchmark where the best agents still can’t finish a playable game.
🎥 Videos: The habits from normal software that quietly break when you build agents, why scale is beating hand-built structure in protein models, what ARC-AGI-3’s headline score really measures, and Jeff Dean on where another million-fold compute leap leads.
📰 Reads: Why “hard to eval” is really a product problem, how Netflix generates its whole homepage with one model, and the case that your GPUs will outlive the three-year obituary.
🛠 Tools: Vercel’s file-first framework for durable agents, and an engine that splits one big model’s inference across GPUs in different cities.
🎓 Learning: The agent skill whose whole job is to make your coding agent write less code.
📄 5 Papers
1. Program-as-Weights: A Programming Paradigm for Fuzzy Functions
https://arxiv.org/abs/2607.02512 | GitHub
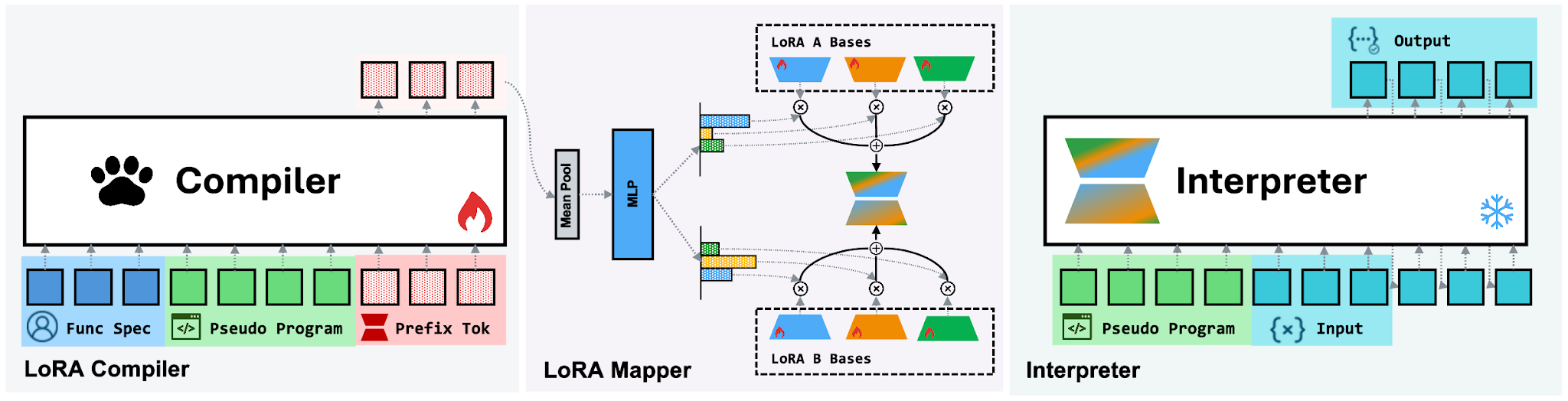
Some small tasks are too fuzzy for plain code, like flagging the important log line, fixing broken JSON, or ranking items by intent. Today you’d call an LLM API every time. Program-as-Weights turns a plain-English description of the task into a small model you run on your own machine. In their tests, a tiny 0.6B model does the job as well as prompting a 32B one, and it runs on a laptop. You build the function once, then run it cheaply and offline instead of paying for every call.
2. AgenticSTS: A Bounded-Memory Testbed for Long-Horizon LLM Agents
https://arxiv.org/abs/2607.02255 GitHub
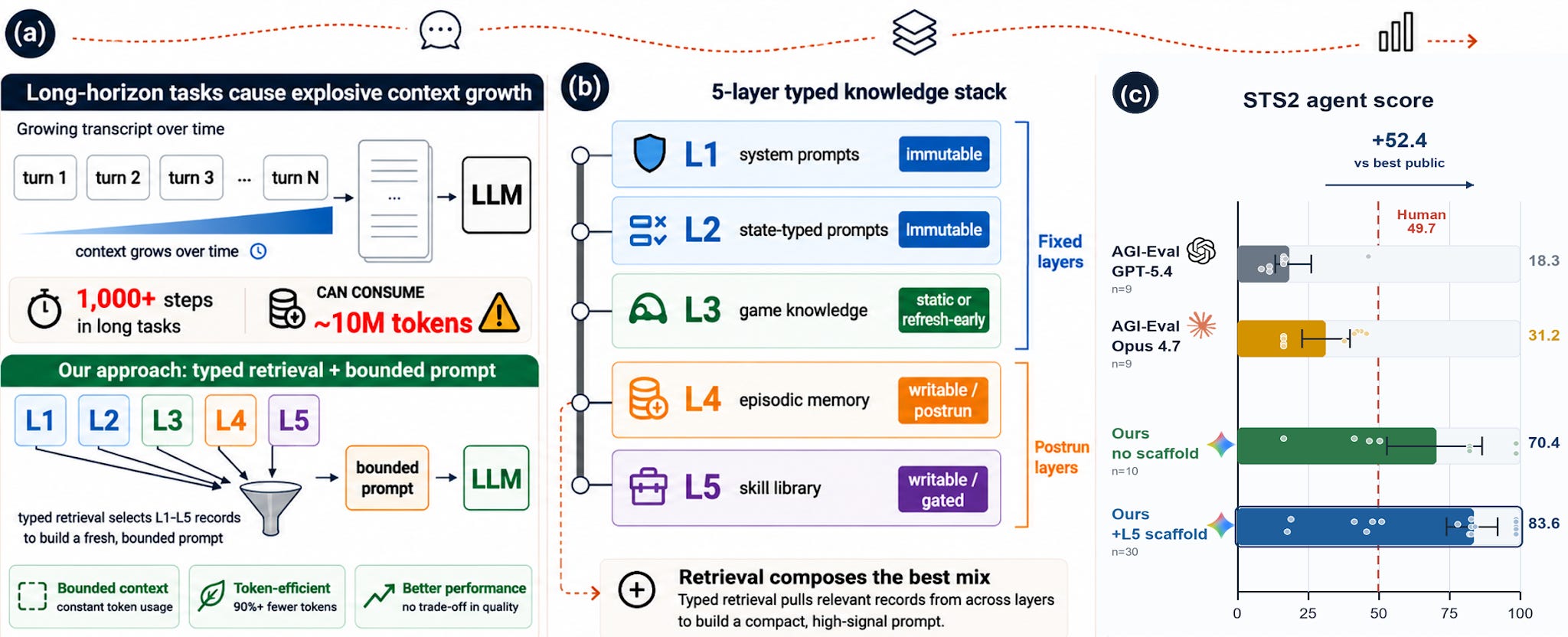
Long-running agents tend to drown in their own history: every step appends to the transcript, the prompt balloons, and the agent loses the thread. AgenticSTS is a test setup for a cleaner approach. Instead of piling everything into one growing prompt, the agent keeps what it learns in separate memory layers and pulls from them as needed, so the prompt stays a manageable size no matter how long it runs. You can switch any one layer off to see how much it mattered. The team tried it on a hard game, Slay the Spire 2, where top models win none of their games at a level humans can usually clear. Adding a memory layer for strategy raised the agent’s wins from three to six out of ten.
3. Looped World Models
https://arxiv.org/abs/2606.18208
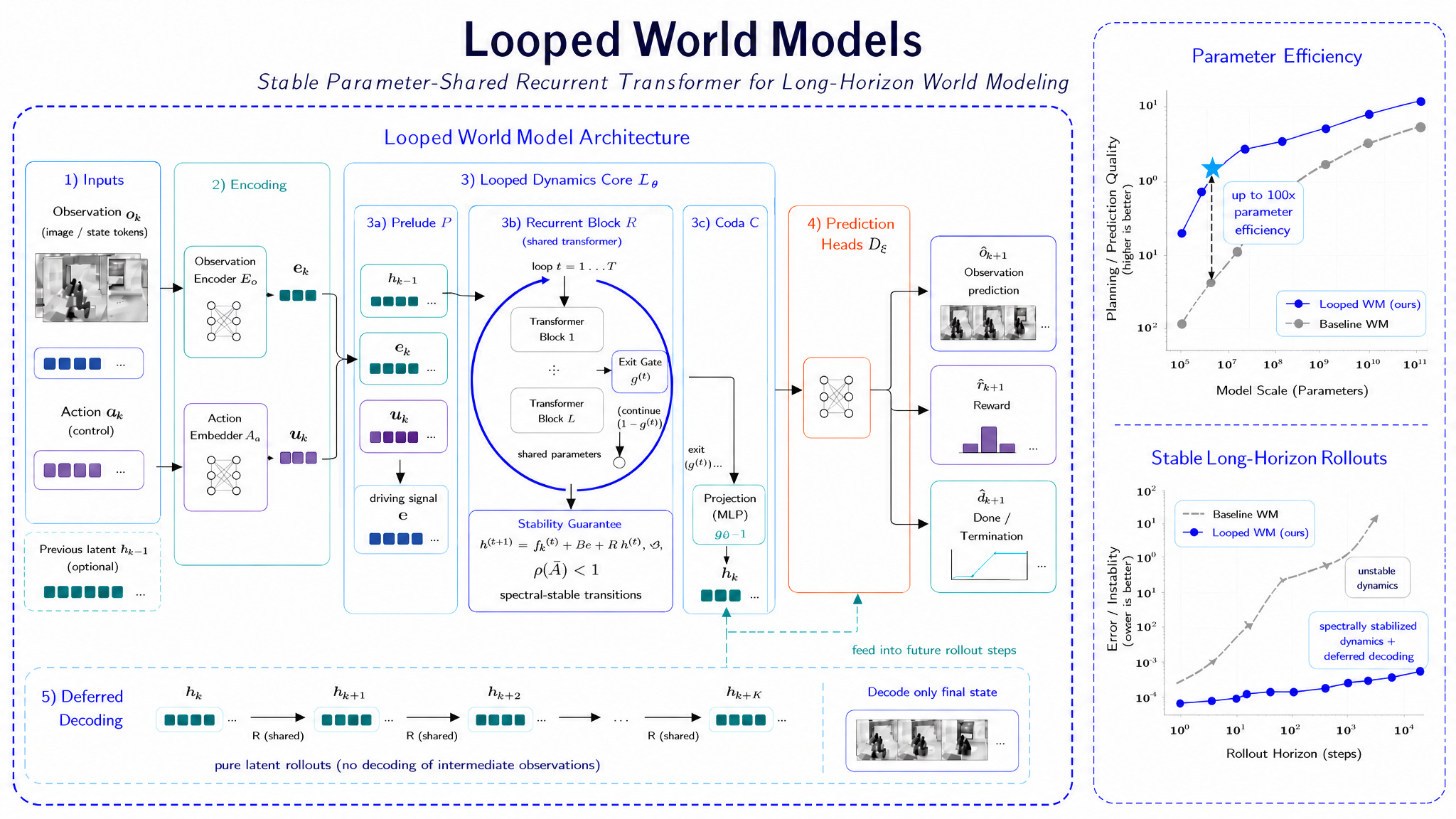
World models usually get better the way everything else does, by adding parameters. This paper proposes a different option: loop a single shared block over and over, refining the latent state, and spend more loops only on the predictions that are hard. The authors claim up to 100x parameter efficiency, though it’s an early idea with no benchmarks or code released yet.
4. Learning from the Self-future: On-policy Self-distillation for dLLMs
https://arxiv.org/abs/2606.18195 | GitHub
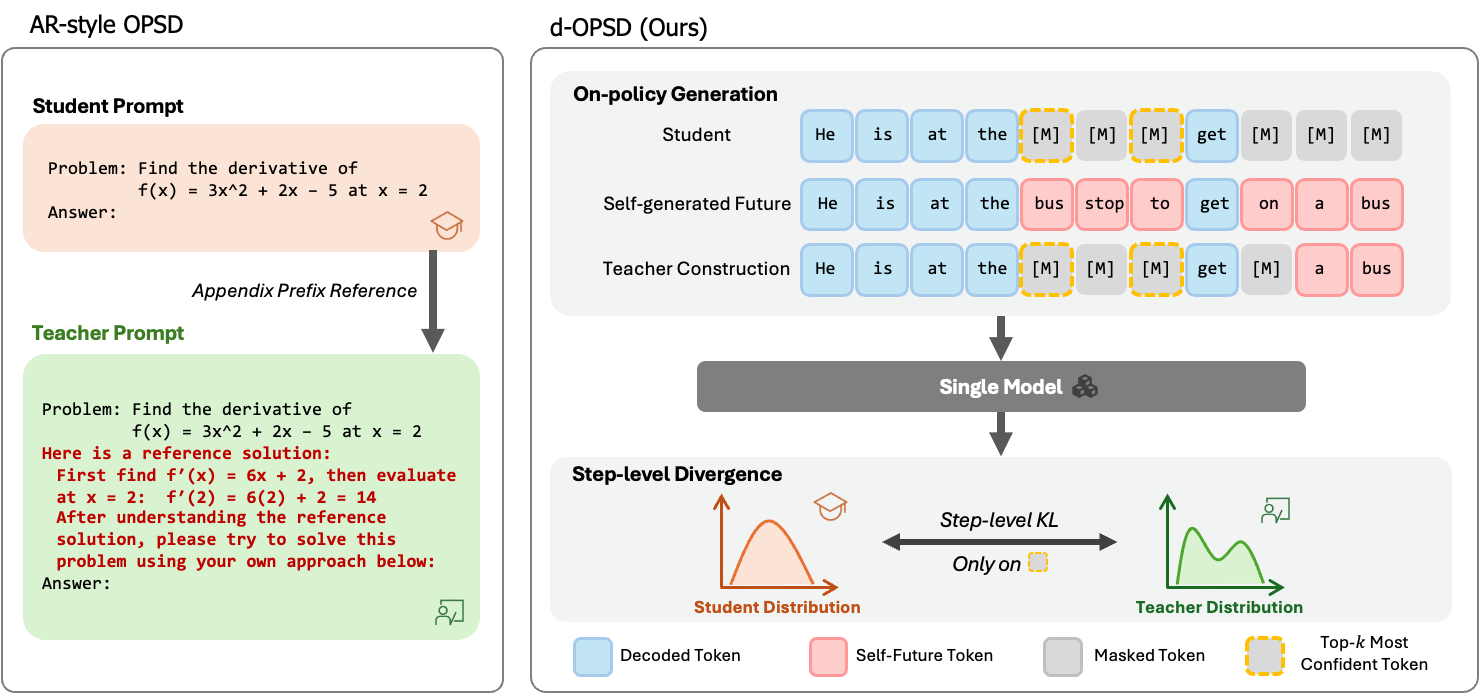
Most language models write left to right. Diffusion language models don’t; they fill words in any order, so the usual ways of training them after the fact don’t fit well. This paper has the model learn from its own finished answers, in a way that matches how these models actually write. It matches or beats standard training like reinforcement learning and fine-tuning while doing about a tenth of the work. If you train these models, the efficiency alone makes it worth a look, and the code is public.
5. GameCraft-Bench: Can Agents Build Playable Games End-to-End in a Real Game Engine?
https://arxiv.org/abs/2606.17861 | GitHub
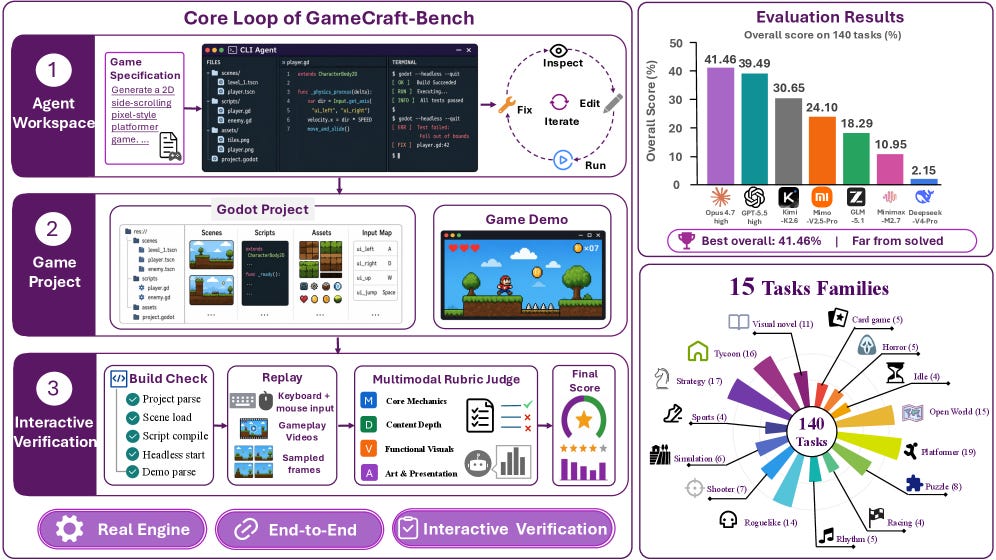
Most coding benchmarks stop at “does the code run.” GameCraft-Bench hands an agent a spec and sees if it can build a complete, playable game inside a real engine, and then judges it by replaying the game. Across 140 Godot tasks, the strongest agent scores 41%, and most fall below that. They build recognizable mechanics but can’t pull them together into a whole game, one with enough content, working feedback, and a coherent feel. It’s a powerful reminder that “the code compiles” and “the thing works end to end” are still far apart.
🎥 4 Videos
1. Why Good Engineers Struggle to Build Agents
Solid software instincts can quietly work against you when you build agents. Philipp Schmid, who works on agents at Google DeepMind, lists the habits to unlearn. Booleans give way to text as your state, so a user can approve a plan and amend it in the same sentence. Errors become inputs you feed back mid-run, not failures you restart from. Unit tests give way to evals, because you measure how often the agent succeeds, not whether one output matches. And an API that reads fine to you can be opaque to a model that only sees the schema. Watch it before your next agent project to save yourself the rewrites.
2. Why Scale Is Beating Hand-Built Structure in Protein Models
AlphaFold won by baking in what we know about protein structure. Alex Rives, who built the ESM protein language models, makes the case that the opposite bet is now paying off: give the model no structural priors and let scale learn the biology. Two ESM models at the same size performed very differently, and the jump came not from more parameters but from feeding in billions of metagenomic sequences the earlier one never saw. His team now treats the model as a searchable map of protein space and has used it to design binders and antibodies. If you work near biology, watch how a scale-first model with no priors gets used to design real molecules.
3. What ARC-AGI-3’s Top Score Really Measures
A 36% score is topping the ARC-AGI-3 leaderboard, and it doesn’t mean what it looks like. The Tufa Labs team explain that the score measures how few moves the agent takes to win, not how many games it wins. That 36% also needs a hand-built helper that turns the game into text for the model; without it, scores fall below 1%. Their old shortcut, only trying moves that changed the screen, stopped working once the organizers made the test harder.
4. Jeff Dean on Where Another Million-Fold Compute Leap Leads
Compute for AI has grown about a million times over in a decade. Jeff Dean, Google’s chief scientist, asks: what if it happens again? He’s not worried about running out of data, pointing to reinforcement learning on code, where you generate many solutions, keep the ones that pass tests, and even translate a working program into another language to mint more. He argues inference, not training, is now most of the compute, which is bending hardware toward lower precision and inference-specialized chips. The problem he most wants solved is continual learning, so a model can learn and act in interleaved cycles instead of the frozen pretrain-then-serve split we live with today.
📰 3 Curated Reads
1. “It’s Hard to Eval” Is a Product Smell
https://hamel.dev/blog/posts/eval-smell/
When an AI feature is “hard to evaluate,” the problem usually isn’t your evals. It’s the product. Hamel Husain says that in order to trust an AI summary of a 50-page medical report, a doctor has to re-read the whole chart, which can take as long as writing the summary from scratch. If checking the output costs that much, the tool has saved no one anything. Before you build an eval, answer four simpler questions: what does the user actually need to verify, what can they compare it against, what shortcuts do experts already use, and what smaller pieces can they accept or reject. Then redesign the product around those answers.
2. GenPage: Towards End-to-End Generative Homepage Construction at Netflix
Netflix replaced the multi-stage pipeline behind its homepage with a single model that treats your viewing history as a prompt and generates the whole page, rows and titles, in one pass. In A/B tests it lifted core engagement and cut serving latency by about 20% against the production system it replaced. The authors draw a useful lesson for personalization at scale: richer input context bought them more than a bigger model would have, and one generative system turned out simpler, better, and faster than a stack of specialized stages.
3. AI GPUs Probably Live Longer Than Three Years
https://www.seangoedecke.com/ai-gpus-live-longer-than-three-years/
The claim that AI GPUs wear out in three years, and that this makes the whole inference business unsustainable, gets repeated a lot. Sean Goedecke went looking for the evidence and didn’t find it. Google runs eight-year-old TPUs in production at full utilization. Amazon’s cloud chief said in early 2026 that AWS has never retired an A100 server. A GPU can be economically old, worth less than the newest chip, while still being physically fine and profitable for inference.
🛠 2 Tools & Repos
1. vercel/eve
Agent projects tend to sprawl into config and glue that no one can find later. Eve, Vercel’s new framework, puts every capability on the filesystem instead: instructions in a markdown file, and tools, skills, and schedules each in their own folder. Both you and a coding agent can then read the whole agent straight off disk, which makes it far easier to inspect and extend.
2. leyten/shard
https://github.com/leyten/shard
Serving a big model usually means fitting it on one machine with enough VRAM, or renting a datacenter. Shard breaks that assumption. It splits a single model into layer-blocks spread across separate machines and streams the activations between them, so no one GPU ever holds the whole model. The project reports serving a 744B model across six workstation GPUs in different US states, over the open internet, at usable speeds.
🎓 1 Pick of the Week
DietrichGebert/ponytail: the agent skill that writes less code
https://github.com/DietrichGebert/ponytail
Most coding agents have the opposite of a discipline problem: ask for a date picker and they install a library, wrap it, and add a stylesheet, when a plain HTML date input would do. Ponytail is a small skill that fixes this by making your agent lazy on purpose. Once it understands the task, it asks: does this need to exist at all, can I reuse what’s already here, is it in the standard library, is it a built-in platform feature, and only then, the smallest thing that works. It never gets lazy about the parts that matter, like validation and security. In one benchmarked run on a real codebase it cut lines of code by about half. If your agent over-builds, this is the fix.
Thanks for reading The Tokenizer! If you found this valuable, please share it with your colleagues and consider subscribing to Gradient Ascent for more AI insights.