

Yes We GAN: A "White Collar" Approach to Fooling AI Detectives
A journey from the humble autoencoder to Stable Diffusion

A couple of quick updates before we start:
Update 1: Welcome to the 225 new readers who've joined the Gradient Ascent community since last week! Gradient Ascent was featured on wired.com, and I'm incredibly humbled by the support.
Update 2: I'm looking for Beta readers for my book, AI for the Rest of Us. If you'd like to help and can contribute as an awesome Beta reader, please let me know here:
I promise you'll not be asked to read the entire draft. Rather, you'll be responsible for reviewing one to two chapters at the most. All beta readers will be acknowledged in the book as part of my AIR team - The team responsible for making the most accessible introduction to AI ever known. They'll also receive a gift from me for their efforts.
With these updates out of the way, Welcome to the series on generative AI. This week, we'll cover a fascinating idea in machine learning. We've seen a ton of cat-and-mouse games in real life. Let's check out one from the machine learning universe! As always, we'll first look at the intuition behind these models and then explore code examples.
This Week on Gradient Ascent:
How Generative Adversarial Networks (GANs) work 👮🦹
[Definitely check out] Prompt engineering guide 🔤
[Consider reading] Adam instability & training LLMs 📉
[Check out] A new open-source LLM - StableLM 🤖
"White Collar" - The Machine Learning Edition

“If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained, you will also suffer a defeat. If you know neither the enemy nor yourself, you will succumb in every battle.”
~ Sun Tzu, The Art of War
The air is thick with the scent of aged leather and the sharp tang of paint. These smells permeate every nook of a dimly lit room laden with the finest antiques. Rebelling against an army of notes and leatherbound books stands an easel. Next to it is a figure – hunched over, sweat dripping over his brow and eyes strained with intense concentration. Only a shaft of light cuts through the darkness, illuminating his features.
Neal Caffrey carefully adds the finishing touches to his latest con. He deftly wields his paintbrush, each stroke a masterful mimicry, each detail a testament to his unparalleled skill. A perfect replica of a Degas. Just recreating the colors and strokes isn't enough. He needs to age the paint and canvas as if it was magically retrieved from centuries past.
Meanwhile, his eagle-eyed partner in crime, Mozzie, paces the room with unease. His brain hums like a small computer, evaluating possibilities and imagining everything that could go wrong. He inspects Neal's work, scrutinizing it with every ounce of knowledge and expertise he possesses. He searches for the slightest hint that could betray them, bringing down this house of cards.
Their ultimate goal: to fool Peter Burke, the ever-vigilant FBI agent. Peter was the only agent that caught Neal before and the only one who can, again. When every move, every stroke of the brush is a high-stakes gamble, the line between victory and despair is thinner than the bristles on Neal's paintbrush.
If you aren't familiar with the story above, it's from the TV show White Collar. Neal is a convicted art forger who has to work with the man to put him behind bars in order to win freedom. What unfolds in the series is a thrilling game of cat-and-mouse where Neal and Peter try to stay one step ahead of each other.
Interestingly though, this same dynamic also plays out in the realm of machine learning. Grab your paintbrushes and magnifying glasses as we dive into the shadowy world of Generative Adversarial Networks.
Intuition: A Game of Cat & Mouse
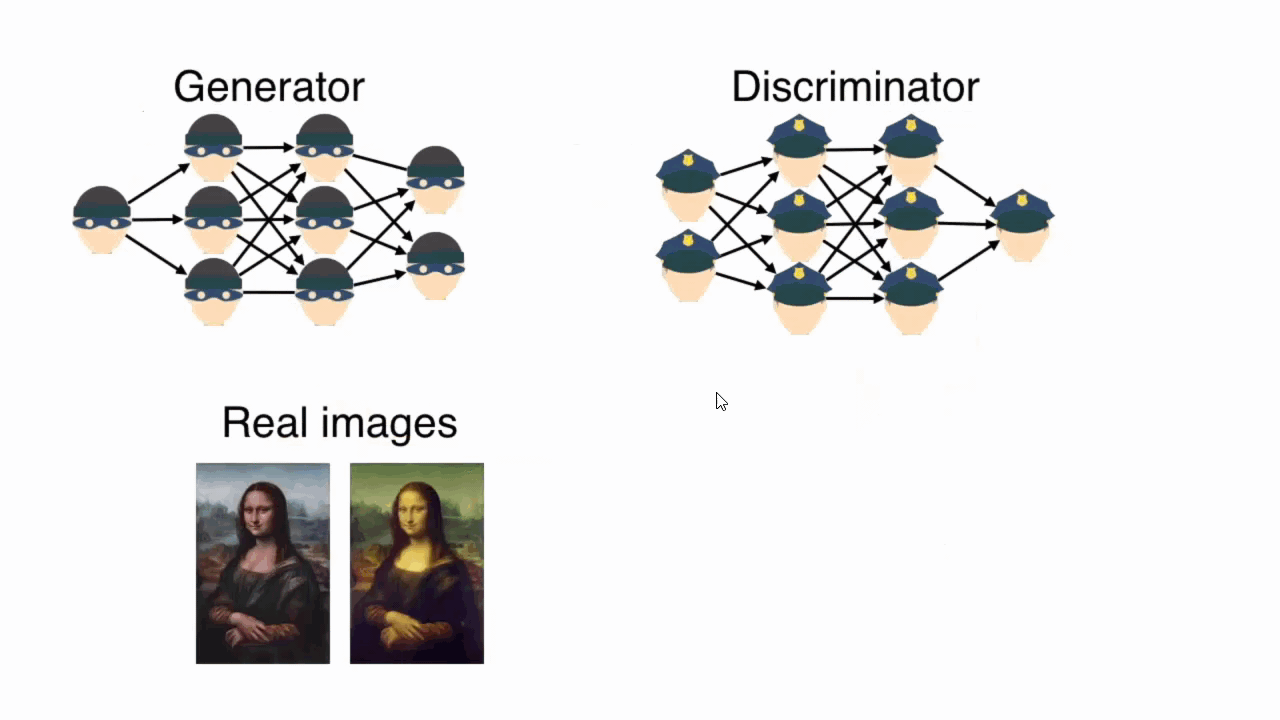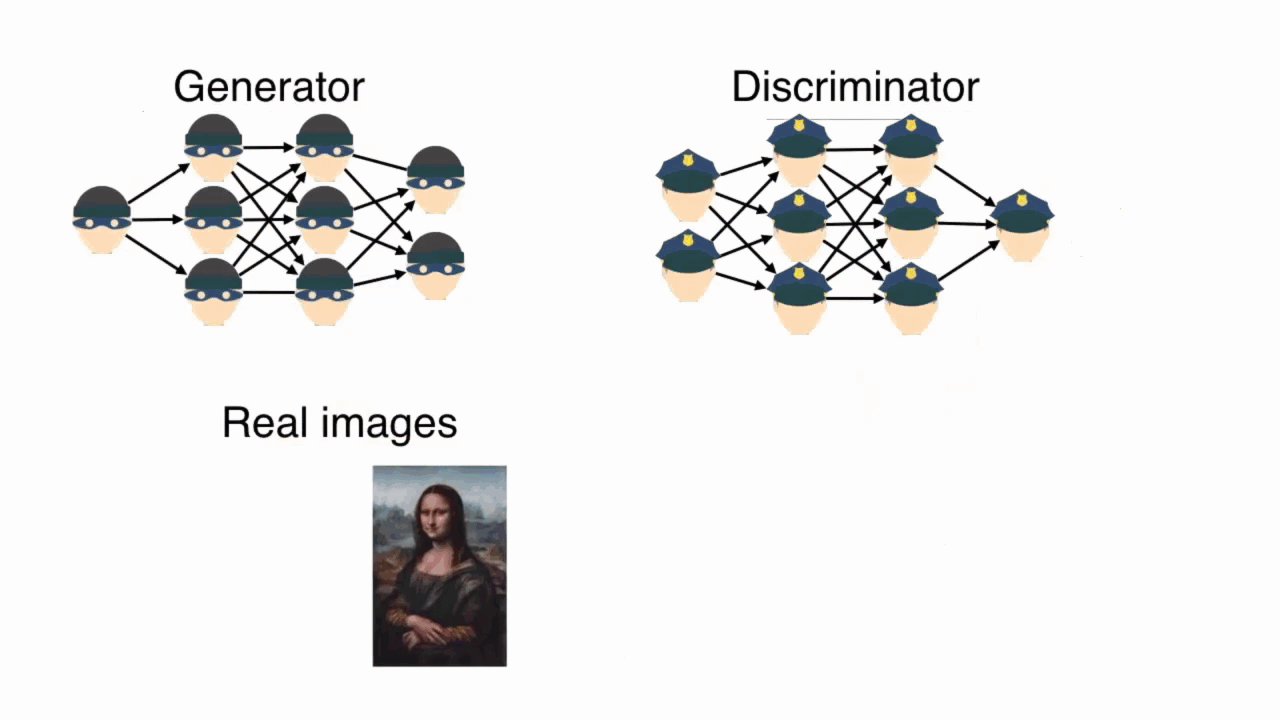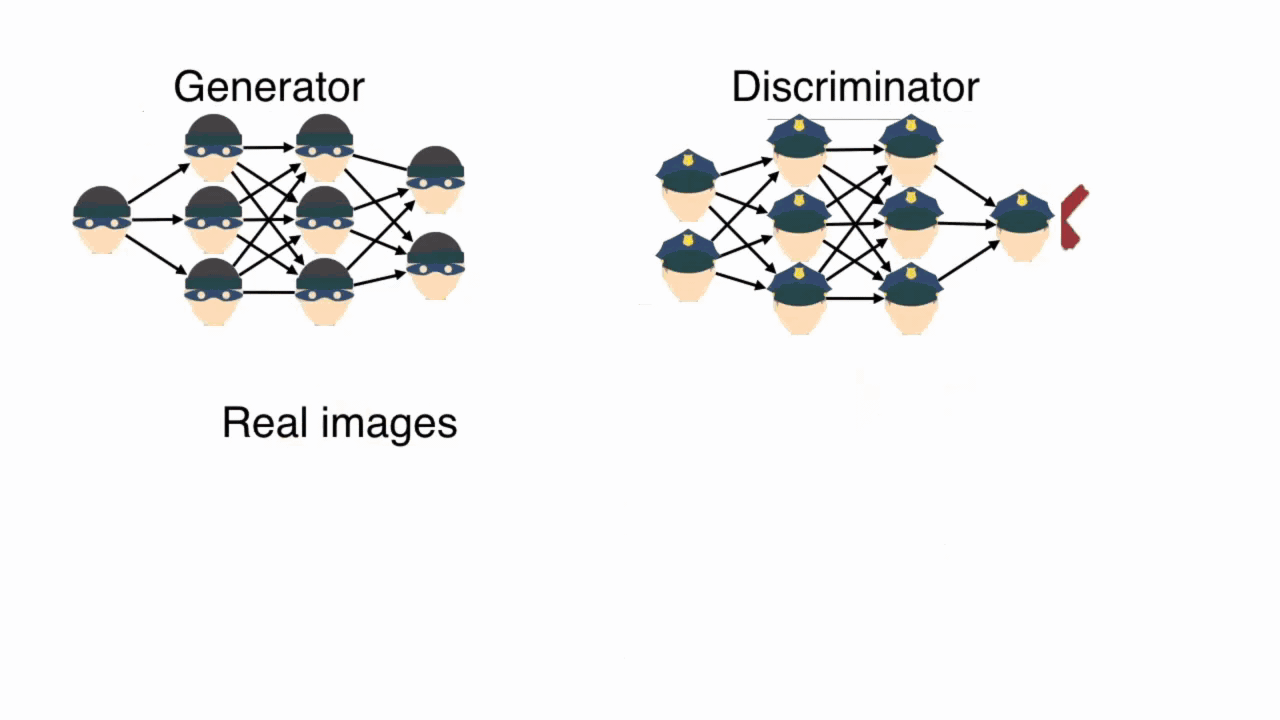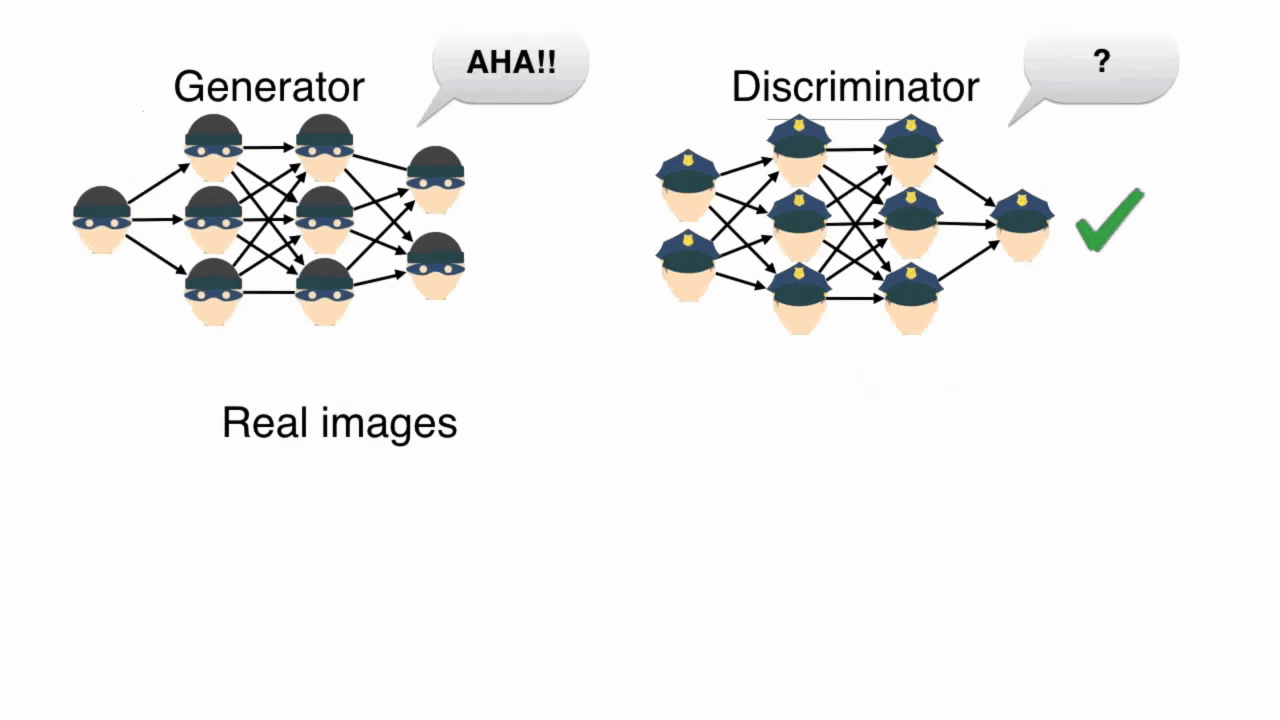
Generative Adversarial Networks, or GANs for short, are a pair of neural networks that are pitted against each other. These networks are called the generator and the discriminator. As the names imply, the generator creates samples while the discriminator evaluates them. The generator's goal is to create samples that fool the discriminator, while the discriminator's goal is to remain vigilant and call out the generator's fakes.
The discriminator learns from both real examples and fake examples to catch the cunning generator. The generator, on the other hand, learns from its mistakes, each time producing samples that become increasingly indistinguishable from the real examples. In a typical ending (and there is more than just one possible outcome), the generator learns to outsmart the discriminator.
The beautiful aspect of GANs is that both these networks are trained simultaneously. Each network gets better with feedback – The generator becomes a master forger, and the discriminator becomes an expert detective.
How do these networks learn? That's next.
The Players: The Thief & the Police
Since GANs have typically been used to create images, let's run with that example. The generator starts with a blank canvas. Random noise, to be specific. Initially, it has absolutely no clue. It tries to create what it thinks is a real image. An image that it thinks would fool the generator.
How does it create an image, you ask? Remember our decoder from last week's auto encoder? Do you recall how it could generate new examples based on a distribution? The generator works in a very similar way. Only here, the generator doesn't have a well-defined latent space as the autoencoder had. It has to generate examples from random noise. So its job is much harder.
At first, its results are terrible. In fact, they're no match for the discriminator who instantly tosses them aside as fakes.
After every attempt, the generator gets feedback on how far off its creation was from a real image (We'll talk about how it gets this info next). It uses this difference to update its weights. The next time it generates images, the results are better. A little closer to what a real image would look like, but not quite there. The cycle repeats. Over time, the generator gets really good at producing realistic images.
The discriminator is made to look at both real images and fakes that the generator produces. It makes a guess on which images are real and which are fake. It gets feedback on how well it did on this task. It uses the feedback to update its weights and get better at spotting fakes. Over time, the discriminator gets really good at spotting fakes.
But if both the generator and discriminator get really good at what they do, who wins the game?
That's the beauty of training GANs. Since both networks try to outdo each other, the training process ideally becomes a zero-sum game. In the best-case scenario, both networks reach a state of equilibrium. When this state is reached, the generator produces near-perfect realistic images. The discriminator in this situation has to toss a coin to guess whether the image is real or fake. It's too close to call. Here's how the images a generator makes look over time (in the best case).
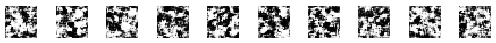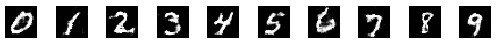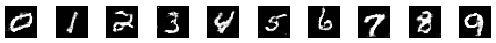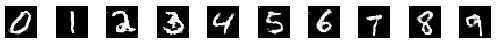
Before we see the challenges with achieving this state, let's look at the unique training process used for training these networks.
The Training Process: Refining the Craft
Since both the generator and discriminator are trained simultaneously, the training process happens in two steps.
In the first step, the discriminator is shown a set of images. Half of these are real. Half are fake (created by the generator). The images are shuffled, so the discriminator can’t cheat. We also provide the discriminator with labels for each image. Perhaps the label "1" for real and "0" for fake. The discriminator looks at the images it’s been given and guesses if they are real or fake. We then compare its predictions to the true labels for each image. This allows us to measure how well the discriminator did. Ideally, the discriminator was able to separate the wheat from the chaff. But, as is true with reality, it doesn't always do that. We backpropagate this error and update the weights of the discriminator. Do better next time, will ya?
Importantly, in the first step, only the weights of the discriminator are updated.
In the second step, the discriminator's weights are kept fixed. It's the generator's turn to learn. We ask it to produce a set of images which we then show our discriminator. The discriminator looks at these images and guesses whether they are real or fake. We use the results from the discriminator to evaluate how well the generator did. We want the generator to be able to fool the discriminator. So, we measure how successful it was in fooling its keen-eyed competitor. The more it fooled the discriminator, the better it did.
We backpropagate this feedback and update the weights of the generator. Remember, only the generator's weights are updated in this step. Those of the discriminator remain fixed.
This process continues until we hopefully reach the state of equilibrium I talked about earlier. But stranger things have happened…
Challenges & Limitations: Twists and Turns
Training GANs is hard. Training a single neural network is often challenging. Imagine training two of them at once. What could go wrong? A lot of things in this delicate dance, it turns out.
Mode Collapse
If we're honest with ourselves, we seldom step outside our comfort zone. If we can do something really well, we tend to only do that a lot and avoid things we aren't good at. This actually happens in GANs too!
The generator can sometimes focus on producing only the specific images that successfully fool the discriminator. Technically, it's doing its job, right? But, this leads to a lack of diversity in the images that it produces. Let's say that the generator gets really good at producing realistic images of flowers. It fools the discriminator every time it produces flower images. But we want it to produce images of alpacas or platypuses. Unfortunately for us, the generator sucks at this. So it keeps producing flower images. Gradually, it forgets how to produce anything else. This situation is called mode collapse.
Training Instability
Since both networks try to stay ahead of each other in this game, their weights end up oscillating a bunch during training. Thus, both networks are very susceptible to the choice of hyperparameters (knobs we can tweak in the training process). A lot of times, the training process diverges with neither network learning anything useful. A big chunk of research has focused on making these networks train stably without pulling each other’s hair out.
Closing Thoughts & Trivia: The End Game
GANs are an incredible idea come to life, and the story of how they came to be is even more fascinating. Ian Goodfellow, the creator of GANs, thought of the idea while attending the graduation party of one of his friends. The full story is covered here. GANs have been used for creating video game art, image and video editing, creating people who don't exist (not cool!), and even producing masterpieces that sold for millions.
In the next edition, we'll look at how to implement a GAN ourselves, look through the math, and also the evolution of the GAN to where it is today.
Resources To Consider:
Comprehensive Prompt Engineering Guide!
Link: https://github.com/dair-ai/Prompt-Engineering-Guide
Elvis Saravia has put together what I think is the most comprehensive guide on prompt engineering. From video lectures to code examples and papers, this repository is your one-stop shop for all things prompting. Definitely check this out.
Adam Instability & LLMs
Paper: https://arxiv.org/abs/2304.09871
The Adam optimizer is a default choice for most practitioners when training neural networks. However, there are some cases of unexplained behavior when using this optimizer to train large language models. This paper explores why this happens.
More Open-Source LLMs - StableLM
Link:
https://twitter.com/StabilityAI/status/1648706156330876928
Stability AI has announced the release of a new LLM called StableLM. Check out their announcement tweet above to access the model and more.
Love White Collar! I was hoping that was the metaphor you were going to use when I saw the headline