



You can't spell Diffusion without U
Understanding one of the core building blocks of Stable Diffusion

This Week on Gradient Ascent:
Explain U-Nets like I'm 5 👶
Your friendly machine learning doodle 🎨
[Use] AI-powered writing assistant ✍️
[Think] Using AI to talk to your past self ⏳
[Consider reading] Generating coherent storyline visuals 📚
Understanding U-Nets:
Just last week, StabilityAI, the company behind stable diffusion released the newest version of their image generator. If generating unbelievably good images from plain text wasn't already enough, the model can now generate higher resolution images and can do really fancy stuff like use depth maps to produce novel images (look at the gif below to see what I mean).

In fact, since its release, no other piece of software has been adopted faster by developers.
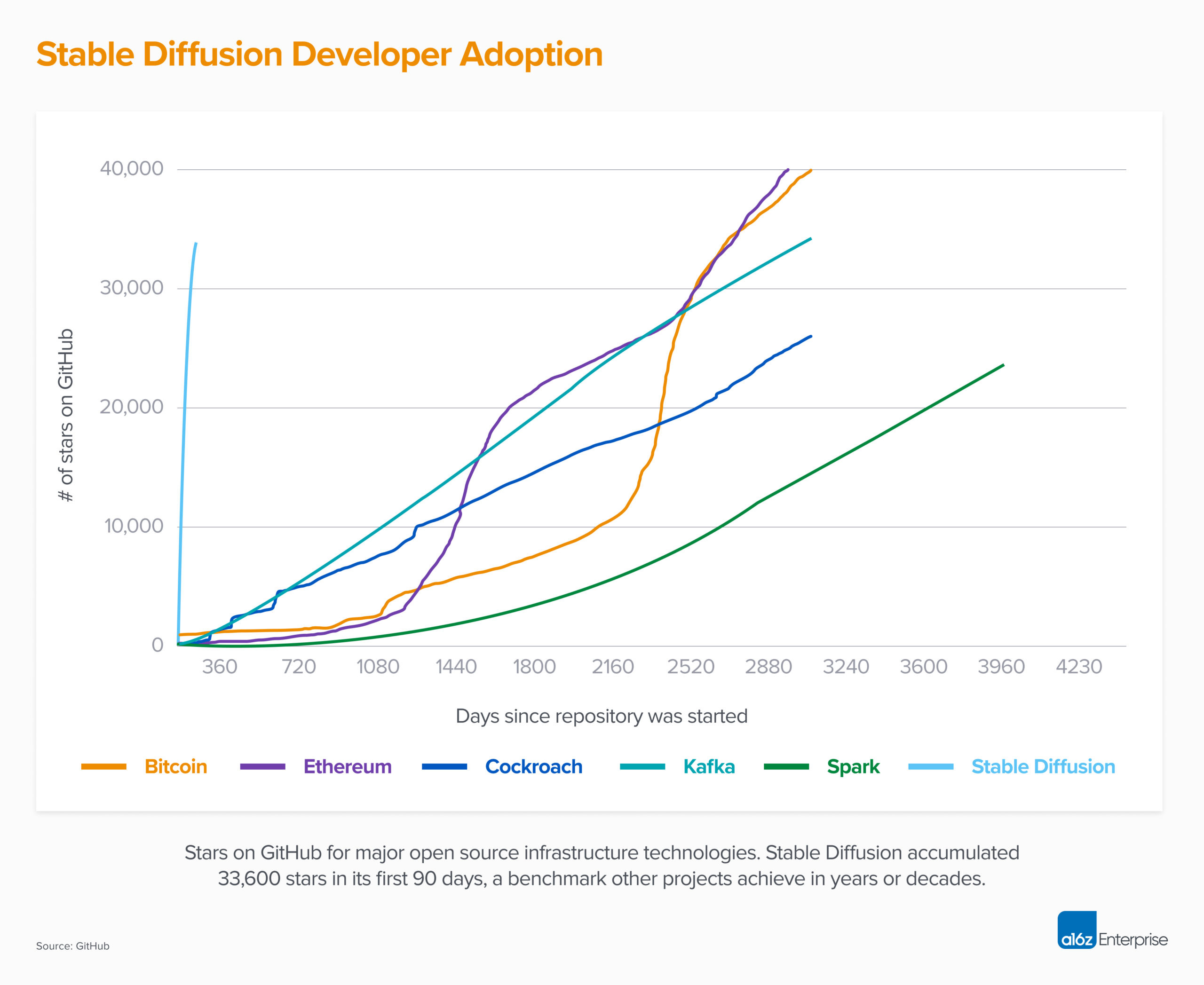
Look at the stable diffusion release notes. I want to draw your attention to one line in particular:
New stable diffusion model (Stable Diffusion 2.0-v) at 768x768 resolution. Same number of parameters in the U-Net as 1.5, but...
Same number of parameters in the U-Net. What is this U-Net all about? That's where our story starts today.
The U-Net is one of the core building blocks of this image generation model. Here's an oversimplified explanation. The U-Net in stable diffusion takes encoded text (plain text processed into a format it can understand) and a noisy array of numbers as inputs. Over many iterations, it produces an array containing imageable information from this noisy array it received. The output of the U-Net is then used by another network called a decoder to create the pictures we all see as output.
But this isn't what the U-Net was designed for at all. In fact, it was designed for medical imaging, all the way back in 2015! So how did it make its way here into a state-of-the-art image generation software? Let's deconstruct the U-Net and find out!
Understanding the U-Net
Why is it called U-Net? One look at its architecture will tell you the answer.

The U-Net takes just an image as input and produced another image as output. More specifically, given the image on the left below, the U-Net produces the image on the right.

This task is called semantic segmentation. Given an image, assign every pixel (smallest atomic unit of an image) to a class that it belongs to. For example, in the image below, assign each pixel to belong to either a horse, a jockey, a car, or the background.

So, as you can see, the structure of this neural network is in the shape of a U. There's a reason for this symmetry. The first half of the "U" shrinks the input image and extracts meaningful information (called features) from it at each stage. It does so through the use of the basic building blocks of convolutional neural networks - convolution layers, pooling layers, and, activation layers. The second half of the "U" reverses this process, expanding the intermediate results (called feature maps) to larger and larger sizes until the final output is the same size as the input image. To do so, it uses a layer known as a transposed convolution (don't say deconvolution) in addition to the pooling and activation layers.
Thus, Convolutional network + Mirror Image of Convolutional Network = U-Net. But, it has another special characteristic. Notice the gray arrows connecting parts of the first half of the network to the second? They help in the expansion process.
Let's use a childhood game to understand this further.
What did you say?
As a kid, I'm sure you'd have played the telephone game (a.k.a grapevine communication game). A group of children stand in a line. The first child whispers something in the second child's ear. The second child whispers it to the third child and so on. Eventually, the last child has to guess what was originally whispered. More often than not, the secret text changes so much from kid to kid that the final version barely resembles the original.
Now, let's take this game and add a twist. Instead of whispering a phrase, the first child has to ask a question. The last child has to answer that question. As the question is passed from child to child, it morphs, and eventually, the last child answers "42" to the question "What is the purpose of life?".

Now, what if we change the rules to help the kids out? (I mean, they are kids after all) Per the new rules, A kid much earlier in the chain can communicate with a kid later in the chain. But, they can only ask the question as they heard it. Wouldn't that make it easier for the last child to answer the original question?
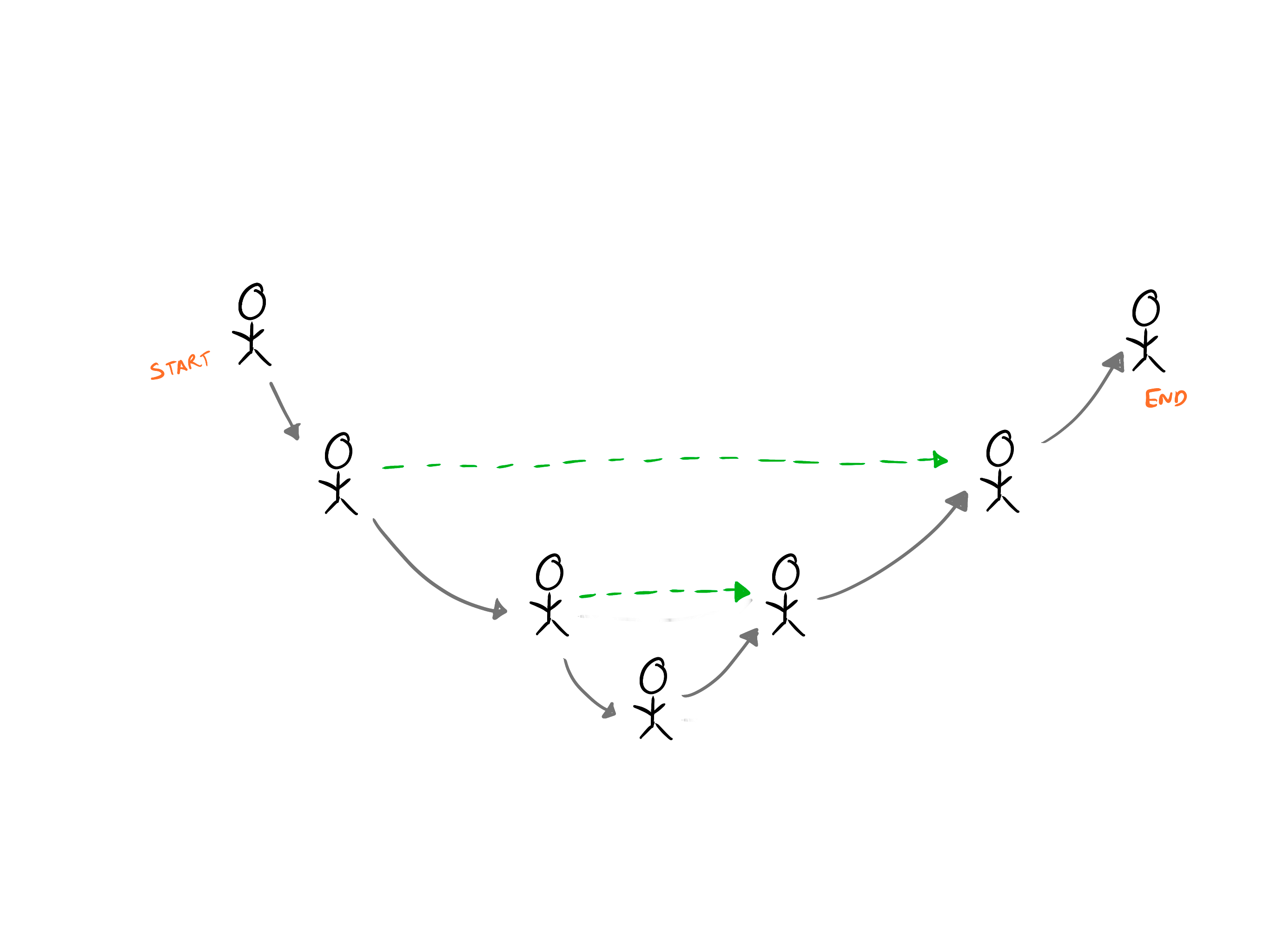
That is the intuition behind the gray connectors in the U-Net architecture.
They help the latter half of the model guess what the missing pixels can be. Why do I say missing pixels? In the first half of the U-Net, the model has the full picture (pun intended). Each layer shrinks the picture and effectively removes raw information that was available to it before passing it on to the next layer.
The second half of the network has the difficult task of expanding a small picture (feature map) back to the same size as the original picture that the network received. But how do you expand something without knowing what to fill into the expanded areas? While this is a topic that deserves its own post, it's safe to say that it's easier to do this if you have context. That context comes from the gray connectors (Kids earlier in the chain in our game).
The Reverse Journey
Traditionally, unique neural networks were proposed for image-related problems first in the computer vision community and then made their way to other domains like medical imaging, etc.
The U-Net is one of the exceptions to this rule. It was intended to solve medical imaging problems but was so versatile and useful that it made its way into a number of computer vision problems - From winning Kaggle competitions to extracting roads or buildings from satellite imagery.
Today, it sits in the core of stable diffusion.
Poorly Drawn Machine Learning:

Resources To Consider:
AI-powered reading and writing assistant
Link: https://bearly.ai/
Here's an exciting application of large language models. Bearly claims to save you hundreds of hours in your reading and writing efforts - Whether it's summarizing content, correcting grammar, or even generating an essay outline all with the click of a button. I plan to test it out and thought you'd like to try it too. Watch the video below for more information.
Conversing with your past self - The AI version
We've all wanted to time travel at some point. Of course, AI still isn't close to solving that. What if you could speak to your younger self without traveling back in time? Here's an interesting (albeit slightly scary) thought experiment that Michelle Huang did. She had meticulously journaled for over a decade and used parts of that text to train a chatbot. This would act as her younger self. In the Twitter thread below, she shares some of the insights and conversations she had with this chatbot. While this might not be for everyone, it's interesting to see left-field applications of machine learning.

Generate coherent story visuals
Paper: https://arxiv.org/abs/2211.13319
Diffusion models have made great strides in generating images from text, but generating coherent visuals for a storyline remains challenging. In this paper, the authors use a technique called "memory-attention" which can store important context and past information. This enables them to capture relevance between parts of the story that have already been generated and the current frame that is being generated. When you can do this, you have a higher chance of creating a cogent story. Check out the paper for more details.
I love your illustrations--they made the concepts come alive!
i played with lensa from prismAI over the weekend. Not sure if they use StableDiffusion but it's really cool what they did