

Understanding Visual Instruction Tuning
And why the multimodal floor is LLaVA

Imagine a smart assistant that could see in addition to listening, speaking, and reading1. If you were deep in the Amazon researching plants, wouldn't it be easier to open up your camera and chat with it about a specific species? For the longest time, we've not had systems that can interact with us using anything beyond text or speech. That is, until recently. This week, we'll look at a fascinating paper that proposes a fix for a part of this problem.
Let's get started.
Visual Instruction Tuning

Instruction tuning improves the zero and few-shot generalization abilities of Large Language Models (LLMs). The NLP community has successfully leveraged this idea to build LLMs like InstructGPT, FLAN-T5, and FLAN-PaLM, which can act as general-purpose assistants. The user provides task instructions and guides the model to solve it through conversation.
But we humans use more than just words. We use visuals to enrich our conversations, explain complex ideas, and understand the world. Recognizing this need, various language-augmented2 "foundation" vision models have emerged in the last two years. However, in these models, language was used primarily as a tool to describe the image content. The result was often a single large vision model with a fixed interface. It wasn't great at adapting to user preferences or interactivity.
But what if we could instruction-tune vision models? Would that pave the way to a general-purpose visual assistant?
Enter LLaVA - Large Language and Vision Assistant3.

Using "visual" instruction tuning, researchers have built a model that operates in the language-image multimodal space. It rivals GPT-4, excelling in chat capabilities and scientific question answering. What's even more impressive is that the dataset used to train the model, weights, and code have been open-sourced.
Over the next few sections, we'll examine how researchers built the instruction tuning dataset, LLaVA's architecture, the training process, results, and more.
Preliminaries
Before we jump into the details, let's quickly understand how instruction tuning works.
LLMs are trained in two stages– Pre-training and finetuning. Pre-training involves showing a model billions of examples to help it learn a language's semantics, structure, and grammar.
Finetuning adapts a pre-trained model to a downstream task by showing task-specific examples.
While pre-training dwarfs finetuning in both the compute costs and dataset size, finetuning still requires a large number of examples. Additionally, we require different model weights for each downstream task since finetuning is typically task-specific.
Instruction tuning resolves these limitations by finetuning a model to multiple language-oriented tasks. We simply collect an assorted set of instructions and finetune the model on these. As the variety of instructions improves, so does the model's performance.

For example, authors of the FLAN paper [1] transformed existing datasets into instructions using templated formats, creating an instruction tuning dataset.

Thus, for a visual instruction tuning process, we'd just have to introduce images into the mix. Right?
Building a Visual Instruction Dataset
On the surface, constructing pairs of images with related questions and answers sounds simple enough. After all, large multimodal datasets like CC and LAION have image-text pairs. However, these aren't explicitly oriented to instruction following tasks. We could crowd-source data, but that is both time-consuming and less well-defined.
The authors of LLaVA thus resort to using the language-only GPT-4 to create instruction-following data.
Yes, that's right.
A language-only model to create instructions for visual data. How?
For an image Xv and its associated caption Xc, it is natural to create a set of questions Xq with the intent to instruct the assistant to describe the image content. We prompt GPT-4 to curate such a list of questions (see details in Appendix). Therefore, a simple way to expand an image-text pair to its instruction-following version is Human : Xq Xv Assistant : Xc. Though cheap to construct, this simple expanded version lacks diversity and in-depth reasoning in both the instructions and responses.
To mitigate this issue, we leverage language-only GPT-4 or ChatGPT as the strong teacher (both accept only text as input), to create instruction-following data involving visual content. Specifically, in order to encode an image into its visual features to prompt a text-only GPT, we use two types of symbolic representations: (i) Captions typically describe the visual scene from various perspectives; (ii) Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location.
Simply put, image-text datasets have two rich sources of context. First, they have captions that describe the scene. Second, some of them have bounding boxes describing each object and its position in the scene.
Armed with these pieces of textual information, a model like GPT-4 can be prompted without using images to create three types of instruction following data:
Conversation: As the name implies, this is a conversation between the assistant and the user about a given image. The tone of the questions is as if the assistant can see the image.
Detailed description: GPT-4 curates a list of questions that ask for a comprehensive and rich description of the image. Then, one such question is randomly sampled, and GPT-4 generates the detailed description.
Complex reasoning: These questions involve a step-by-step reasoning process following rigorous logic.
Here's an example of how these would look:

At the end of this process, the authors collect 158K unique samples, of which 58K are conversations, 23K are detailed descriptions, and 77K are complex reasoning.
The LLaVA Model
Let's look at the model next. LLaVA has three components:
Visual Encoder: This converts the image into visual features. The encoder itself is a pre-trained CLIP ViT-L/14.
Language Model: A pre-trained Vicuna, known for its instruction-following capabilities, converts text into embeddings.
Projection: This is a simple linear layer that "projects" the visual features from the encoder into the word embedding space.

Training
Like most transformer models, LLaVA is trained in two stages.
Stage 1: Pretraining for Feature Alignment
In this phase, both the vision encoder (CLIP) and the language model (Vicuna) are frozen. Only the weights of the projection layer are updated using a filtered CC3M dataset (595K image-text pairs). Doing so helps align the image features from the vision encoder with the pretrained LLM's embeddings.
Each data sample is treated like a single-turn conversation. For an image, a question is randomly sampled. The questions are just requests to describe the image briefly or in detail, as shown below:

The ground truth response is the actual description/caption of the image. The goal of this stage is just to build a compatible visual tokenizer for the LLM.
Stage 2: Finetuning End-to-End
In this stage, the visual encoder remains frozen, but the weights of the projection layer and the LLM are updated. Finetuning is done for two specific use cases:
Multimodal Chatbot: This is a chatbot finetuned on the 158K language-image instruction dataset we saw earlier. Of the three types of responses, conversations are multi-turn while the other two are single-turn. All three responses are uniformly sampled during training.
Science QA: The ScienceQA benchmark consists of multimodal science questions with the answers annotated using detailed lectures or explanations. For each question, the model provides the reasoning process in natural language and selects the answer among multiple choices. This is set up as a single-turn conversation.
The conversations themselves have a structure, as shown below. The human "asks" the question to the model (labeled the assistant below), and it responds. Depending on the number of turns, the structure repeats. Importantly, only the tokens highlighted in green are used to compute the loss.

Results and Upgrades
Now for the interesting stuff. How does this model stack up against other vision-language multimodal models– GPT-4 (the multimodal version), BLIP-2, and OpenFlamingo? First up, we'll look at LLaVA as a multimodal chatbot.
Although LLaVA is trained on a smaller instruction-following dataset, it performs surprisingly well compared to GPT-4. For example, these are the results on two images that are out-of-domain for LLaVa. It still understands the scenes well and follows the questions. BLIP-2 and OpenFlamingo focus on just describing the image.

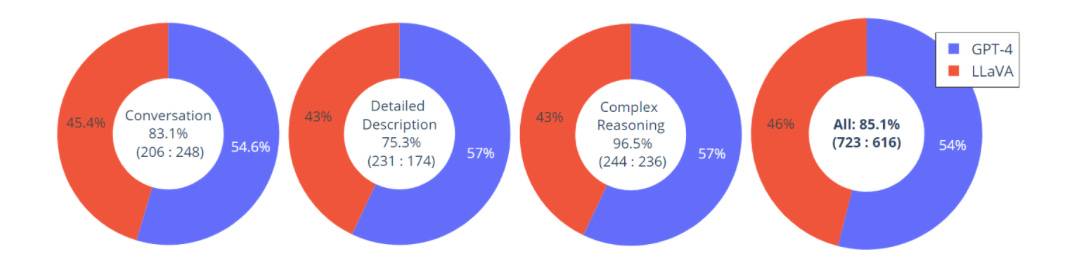
To get a quantitative measure of how good LLaVa is, the authors use GPT-4 to evaluate the quality of the generated responses. The process is described in the paper as follows:
Specifically, we create triplets consisting of image, ground-truth textual descriptions, and question. The candidate models (e.g., LLaVA) predict the answers based on the question and the image. To provide an approximate theoretical upper bound, we create a reference prediction based on the question and the ground-truth textual descriptions, using the text-only GPT-4. After obtaining the responses from both models, we feed the question, visual information (in the format of textual descriptions), and the generated responses from both assistants, to the judge (i.e., text-only GPT-4). It evaluates the helpfulness, relevance, accuracy, and level of detail of the responses from the assistants, and gives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance.
On a set of 30 unseen images, each with three types of instructions, LLaVA achieves a score of 85.1% relative to GPT-4.
LLaVA performs remarkably well on the ScienceQA task, too. By itself, it achieves an accuracy of 90.92%, close to the state-of-the-art score of 91.68%. Interestingly, when LLaVA and GPT-4 are ensembled, the pair achieves a new state-of-the-art of 92.53%. Notice how these models outperform humans on this benchmark.

Emergent Behavior
LLaVA also exhibits a couple of interesting emergent behaviors. For example, it can understand visual content that isn't covered in training. In the image below it recognizes Elon Musk even though his picture wasn't used in any part of the training4.

It also demonstrates excellent OCR capabilities. For example, In the images below, LLaVA can provide interesting details using just the logos or handwriting.

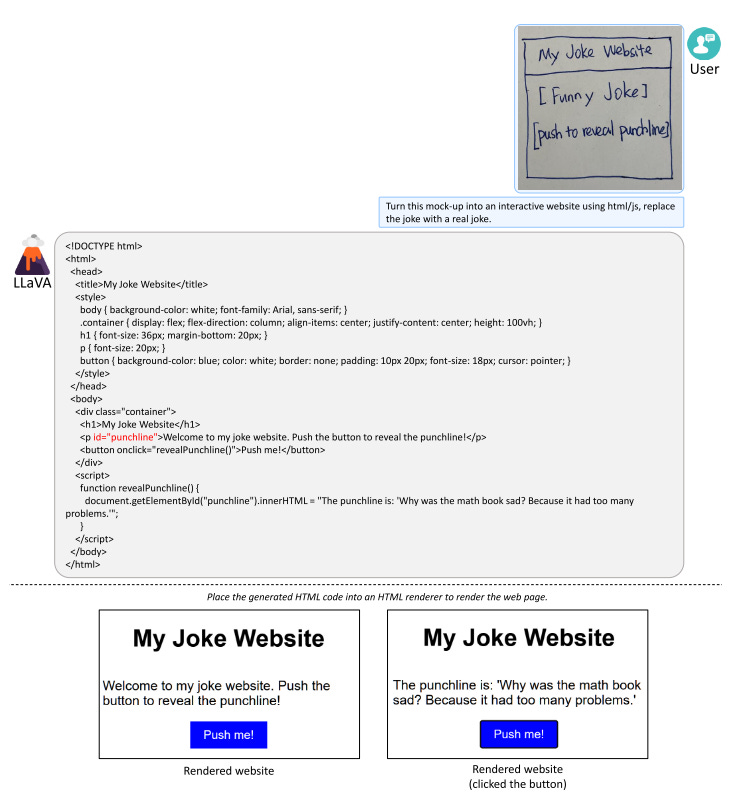
Like GPT-4, LLaVA also appears capable of generating HTML/JS/CSS code for a joke website based on a simple user sketch (there is a minor error that needs to be fixed shown in red).
LLaVA 1.5
The authors enhanced the model's capabilities with simple modifications to LLaVA, like using an MLP instead of a single linear layer, a CLIP ViT-L with a resolution of 336 pixels, and academic task-oriented data. The result? State-of-the-art results across 11 benchmarks.

It's interesting to note that the model finishes training on a single A-100 node with 8 GPUs in one day.
Limitations
Despite these amazing results, there are still a couple of shortcomings to address. First, LLaVA uses full image patches, prolonging each training iteration. Second, it can't process multiple images due to a lack of instruction-following data and context length limits. Third, it's still limited in problem-solving in certain domains. Hopefully, higher-quality data can help with this. Finally, it can hallucinate and thus must be used with caution.
Overall, LLaVA is an amazing step forward in Large Multimodal Model research. There's already work underway to extend this idea to other domains. LLaVA-Med, for example, serves as a multimodal assistant in the healthcare sector. It helps address open-ended questions related to biomedical images. I'm excited to see how these models evolve this year. One thing's for sure: multimodal will be a buzzword in no time.
Takeaways
The LLaVA paper's most significant contribution is leveraging a language-only GPT-4 to create a "visual" instruction-tuning dataset.
It has a simple architecture that connects a vision encoder and LLM for general-purpose visual and language understanding.
An updated version of the model, LLaVA v1.5, achieves SoTA5 on 11 benchmarks with just simple modifications to the original and surpasses methods using billion-scale data.
The dataset, model weights, and code are publicly available.
References
Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
Liu, Haotian, et al. "Visual instruction tuning." arXiv preprint arXiv:2304.08485 (2023).
Liu, Haotian, et al. "Improved baselines with visual instruction tuning." arXiv preprint arXiv:2310.03744 (2023).
Li, Chunyuan, et al. "Llava-med: Training a large language-and-vision assistant for biomedicine in one day." arXiv preprint arXiv:2306.00890 (2023).
The Alexas and Google Homes of the world can listen and "speak", while ChatGPT et. al can read and type back.
For an exploration of this space, consider checking out this curated repository: https://github.com/Computer-Vision-in-the-Wild/CVinW_Readings
The AI community continues its stellar tradition of squeezing technical terms into common words of the English language. By the way, I don't recommend entering LLaVA's hot homonym. One does not simply enter… But I digress.
The authors admit that Elon Musk's images might have been used to pretrain the CLIP encoder which they took "as-is". Even so, it's amazing that the model is able to "generalize" to unseen examples.
State of The Art