

What does an LLM look at?
Back from a hiatus with more LLM goodies...


This week’s newsletter is brought to you by an active community of 3,000+ members who learn together and help each other grow. The Small Bets community is the place to be if you’re looking to grow your creative endeavors and be inspired by some of the best builders on the internet. No recurring fees. Pay once, and you'll get lifetime access to everything.
I want to thank you for the overwhelming support and response to my book "AI for the Rest of Us." The feedback has been beyond my wildest dreams. I'm incredibly grateful for your kindness and readership. I'll share more details about the print version as time passes, but it's time to get back to regularly scheduled programming.
A couple of quick updates.
First, It's been two months since I posted the last edition. Why the break from a weekly cadence? The short answer is that I needed it. The long answer is that I burned the candle at both ends between managing work, a new tiny human (the first was already a handful), and writing. My tank was empty after writing and illustrating every day for the past eight months. An extended rest away from the keyboard has really helped. But I'm still easing my way back in, and I appreciate your understanding.
Second, Gradient Ascent crossed 4000 readers! I still can't believe it. I'm really grateful for your support and feedback. This growth would not have been possible without you.
So where did we leave things? In the last edition, we looked at the high-level intuition behind large language models and how they work. This week, we'll look at what these models look at in a body of text. The paper we'll be looking at was published four years ago as of this writing. About 150 papers1 get submitted to arxiv every day. Naturally, it's incredibly easy to miss an excellent piece of research. Yet, despite its oldness, I find this work extremely fascinating and fun to learn from. This just shows that there's always value in looking back and considering older work with fresh eyes.
In this paper, the authors open the BERT black box and examine its inner workings. There's been enough coverage on pretraining, finetuning, and other modern approaches to squeeze the last drop of LLM goodness. But what makes them so effective in the first place? Why do they work the way they do? What do these models look at when shown a body of text without context?
This paper tries to answer these questions, albeit with the knowledge available from four years earlier.
Let's get started!
This Week on Gradient Ascent:
What does BERT look at? 📝
[Check out] A new course on LLM applications 🧑🏫
[Consider reading] AI safety and risks 🛟
[Consider reading] A ViT for any aspect ratio and resolution 🖼️
BERT and High School Finals
I can still vividly recall the sleepless nights before my high school finals. In my case, they were bleary-eyed mornings since I wasn't a night owl. There was always a mountain of material to learn, and everything, including the marginalia, was fair game. My teachers made it a point to test us with the most challenging questions. After all, if you can crack those, the easy ones don't stand a chance, right?
Suffice it to say that it took me several revisions, repeated practice, and buckets of coffee to get good. With each pass through a concept or idea, I could recollect more. I could also connect the dots better. So much so that when revising the final time before the exam, I was paying attention to specific words in a sentence while "skimming" the rest. That's all I needed to recollect other ideas I had read before and put them all together in context.
Don't Large Language Models go through the same process during pretraining? Minus the coffee, of course. As I did in high school, they, too, take several passes through seemingly disparate pieces of text. Like me, they, too, have to recollect things from memory. Could it then be possible that they, too, pay special attention to certain parts of the text they read?
That's what the paper "What does BERT look at?" investigates.
BERT was among the first in a series of LLMs that heralded the ImageNet moment for NLP. It's an encoder-only model with multiple encoder layers, each with multiple attention heads. Each of these attention heads takes a sequence of words (vectors, to be precise) and derives context from them. In simple terms, these heads try to figure out how important every other word in a sentence is with respect to the current word the model is processing. Remember this idea because we'll often return to this concept in this article.
BERT is pretrained on 3.3 billion tokens on two types of tasks– Masked language modeling and next-sentence prediction. We've covered these in detail last time, so check that out here. Once pretrained, BERT can be finetuned on tasks of our choosing, like sentiment analysis or question answering.

Before we dive into the details of the paper, there's one more detail to discuss– Two special tokens are added to the text during preprocessing. The [CLS] token is added to the beginning of the text, and the [SEP] token is added at the end. The [SEP] token is also used to separate multiple pieces of text in situations like reading comprehension and so on. Remember these tokens as well. We'll be coming back to them later.
Now that we have a basic idea of what BERT is and how it's pretrained, let's look at how the authors figure out what it's looking at when it reads.
What does BERT look at?
To study what BERT looks at, we must pay attention to its attention heads (Sorry, I couldn't resist). The authors analyze BERT's attention heads behave through two means: Surface-level patterns and individual head probing.
Surface-Level Patterns in Attention
Using a set of 1000 random Wikipedia segments, the authors study the attention heads from three perspectives– Relative position, attention on separators, and how broad or narrow each head's focus is.
It turns out that most of BERT's heads put very little attention on the current token. However, some heads specialize in attending heavily on the previous or next token. This trend is especially true in earlier layers of the network. For example, look at the first head in the third layer (3-1) in the figure below. It attends strongly to the token that follows the current one.
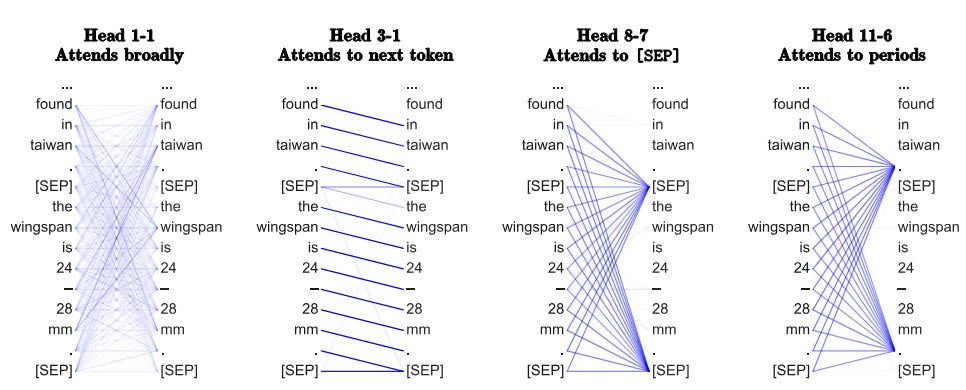
In fact, four heads in layers 2, 4, 7, and 8 put over 50% of their attention on the previous token, while five heads from layers 1, 2, 3, and 6 put a similar amount on the next token.
A substantial amount of BERT's attention focuses on a few tokens– [SEP], [CLS], the period, and the comma in particular. Over half of the heads in layers six through ten focus on the [SEP] token. This is somewhat expected because [SEP] and [CLS] are never masked out, and the period and comma tokens are the most common tokens in sentences.
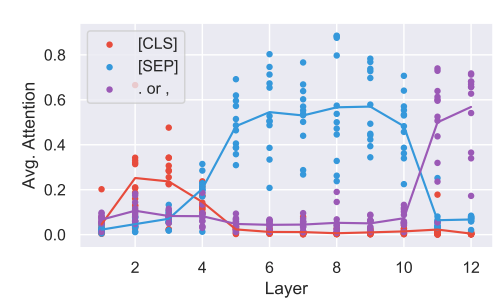
While you might think that the [SEP] token is used to aggregate segment-level information that other heads can read, this isn't the case. Wait, isn't the [SEP] token used to separate multiple segments? What other reason could there be for these heads to attend so much to it?
Well, it turns out that the heads use the [SEP] token as a no-op. That is, an attention head attends to the [SEP] token when its function is not applicable.
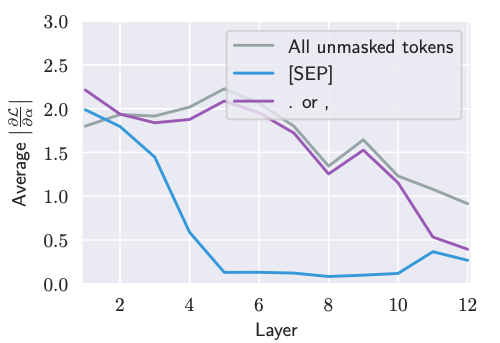
To verify this, the authors measure the magnitude of the loss gradient with respect to each attention weight (Note that they do this for the masked language modeling task). Think about it like this. This value measures how much changing the attention to a token will change BERT's outputs.
Right from layer 5 (where the attention to [SEP] becomes high), the gradients for attention to [SEP] become very small. This implies that attending to [SEP] doesn't substantially change BERT's output.
Next, the authors compute the average entropy of each head's attention distribution to determine whether attention heads focus on a few words or many. They found that some heads, especially in lower layers, have very broad attention. These heads spend at most 10% of their attention on any single word.
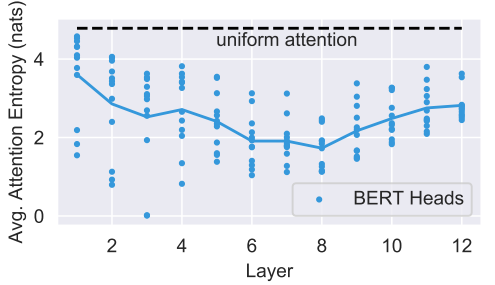
The authors also measure entropies for all attention heads from only the [CLS] token. The average entropy from [CLS] for most layers lines up with the figure above. However, the last layer has a high entropy from [CLS], indicating a very broad attention scope. This makes sense, given that the representation of the [CLS] token is used as input in the next sentence prediction task.
Thus, it attends broadly to aggregate a representation for the whole input in the last layer.
Probing Individual Heads
Now that we've seen the big picture, let's look at the individual heads next. As part of the text preprocessing, BERT uses byte-pair tokenization. This means that some words are split up into multiple tokens. The authors thus convert token-token attention maps into word-word attention maps before analyzing the heads.
To evaluate dependency syntax, they extract attention maps from BERT on the Wall Street Journal portion of the Penn Tree-bank. Dependencies are evaluated in both directions – The head word to the dependent and vice-versa.
The results are pretty interesting. While no individual head does well at syntax "overall," certain heads specialize in specific dependency relations, as seen in the figure below. What's more interesting here is that none of these heads were instructed to learn these dependencies. This syntax-sensitive behavior emerged from self-supervised training alone!

In the figure above, the darkness of a line indicates the strength of the attention weight. All attention to/from red words is colored red. This is done to highlight certain behaviors.
Next, the authors study how the heads perform on a more challenging task, namely, coreference resolution. Coreference links are usually longer than syntax dependencies. Many SOTA methods generally perform much worse at this than at dependency parsing.
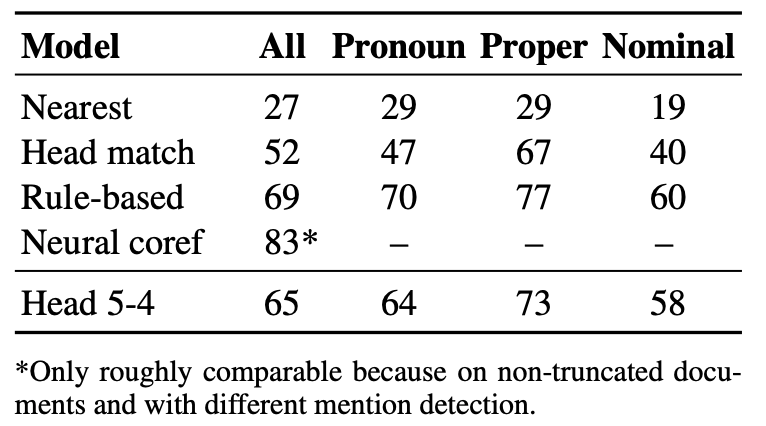
To evaluate BERT’s heads, the authors compute antecedent selection accuracy. That is, what percent of the time does the head word of a coreferent mention most attend to the head of one that mentions antecedents?
They compare results against three baselines for selecting an antecedent– Picking the nearest other mention, picking the nearest other mention with the same head word, and using a simple rule-based sieve system.
One of BERT's heads achieved decent coreference resolution performance, improving by over 10 points on the string-matching baseline and coming very close to the rule-based system, as seen in the table below.
On probing combinations of attention heads, the authors find that BERT's attention maps have a thorough representation of English syntax. Overall, it appears that BERT learns some aspects of syntax purely as a by-product of self-supervised training. How cool is that?
Finally, the authors cluster the heads to see if heads in the same layer are similar to each other. They also check if the heads can be grouped by behavior. It turns out that both of these are somewhat true! Heads in the same layer have similar attention distributions. This also holds for heads that have similar behaviors. The apparent redundancy in attention heads could be due to attention dropout, which causes some attention weights to be zeroed out during training. Have a look at the clusters below.
I hope you enjoyed reading this one. Wouldn't it be great if a similar analysis was done on more recent LLMs to see if anything has changed? By the way, the official code for this paper can be found here: https://github.com/clarkkev/attention-analysis.
Sidebar: How to Start Writing Online Workshop
My good friends at the online writing school, Write of Passage2, are hosting a free workshop to kickstart your online writing journey.
During the one-hour session happening on Tuesday, September 12th, David Perell will teach you new frameworks with live exercises to bring your writing alive. Learn how you can use conversations as creative fuel, how your existing knowledge can help others, and how sharing your ideas can make you a magnet for life-changing opportunities.
If this resonates with you, consider registering for the workshop on Tuesday, September 12th at 7 pm ET.
Resources To Consider:
A New Course on LLM Applications
Code: https://github.com/databricks-academy/large-language-models
Databricks has a neat course on LLMs aimed at developers and engineers. It walks you through building LLM applications with the latest frameworks and goes from an introduction to LLMs to taking them to production. Check out the playlist below and the code in the link above.
https://youtube.com/playlist?list=PLTPXxbhUt-YWSR8wtILixhZLF9qB_1yZm&si=orXaacav3l4FBrQ9
AI Safety and the Age of Dislightenment
Paper: https://www.fast.ai/posts/2023-11-07-dislightenment.html
Co-creator of fast.ai and educator Jeremy Howard has written an excellent piece on the pitfalls of stringent AI model licensing and surveillance. He calls for the community to be open and advocates for exercising caution while regulating the technology. Definitely read this piece to understand the issues around the licensing and surveillance of AI.
A Vision Transformer for any Aspect Ratio and Resolution
Paper: https://arxiv.org/abs/2307.06304
In this paper, the authors propose a way to move away from the standard CNN-designed input and modeling pipeline used in computer vision. Specifically, they take advantage of the fact that Transformers are flexible sequence-based models and thus can handle varying sequence lengths. Using sequence packing, they process inputs of varying resolutions and aspect ratios. The resulting model, NaViT, can be efficiently transferred to classification, detection, and segmentation tasks. At inference time, the input resolution flexibility can be leveraged to handle cost-performance tradeoffs. Check out the paper for more.
I'm pretty sure it's way more at this point.
Affiliate link: I may receive a commission if you make a purchase after clicking on one of these links (at no additional cost to you). Note: I’ve taken Write of Passage myself and endorse that it’s one of the best places to learn how to write for the Internet.