

DALL-E 3 Decoded: The End of Prompt Engineering
From Synthetic Captions to Creative Conundrums...

This week, we'll be getting into the weeds of DALL-E 3, OpenAI's new state-of-the-art image generator. There are some interesting techniques they've employed to make this model understand nuance and detail better. As always, if you have feedback, questions, or comments, let me know through the form below or use the comment section. Let's go!
DALL-E 3: A Picture IS Worth A Thousand Words
"I love muddy puddles," cried a pastel pig in glee. "Peppa loves muddy puddles," agreed the narrator. "I love muddy puddles," exclaimed my three-year-old. I nodded absent-mindedly. My brain was furiously hatching a plan to distract her.

But at that moment, a well-timed ad came to my rescue. "Ad! Ad! Ad!" squeaked the tiny human in anger. With the precision of a Fruit Ninja expert, I swished the remote in the air and hastily switched over to a video that I knew even I would enjoy.
On came Jazza, a phenomenal artist and entertainer. In the video, he was illustrating characters solely based on their textual descriptions1. He'd have no other hints or any visual cues. After each one, he'd pause and check who the actual character was. My word, it was magic. What surprised me was that Jazza was able to capture so much context from very, very limited textual guidance.
That got me thinking. Isn't this kind of like prompting a human to draw something?
Why can't current generative models work this well consistently? Why can't they instantly grasp the vision buried in our heads? More often than not, we Parseltongue our way into saying the right things in the right order to get something good2. Yes, I exaggerate slightly, but prompt whispering engineering still feels cryptic-y.
So when OpenAI came out and said, "DALL·E 3 understands significantly more nuance and detail than our previous systems, allowing you to easily translate your ideas into exceptionally accurate images," I decided to put it to the test.
I was pleasantly surprised by what I found:
DALL-E 3 reduces the need for careful prompting - I could “converse” with it.
It doesn't miss details I specify, including background information.
It usually produces "better" images than its predecessors for the same prompt.
So, what's the secret sauce?
It was trained with better captions. While this isn't the only change OpenAI made, it's a very important shift from prior work.
Over the rest of this piece, we'll cover my Jazza experiment, dissect the key contributions in DALL-E 3, how OpenAI evaluated this new model, and why this might mark a change in how we interact with generative models - for better and for worse.
Professional Artist vs DALL-E 3
To compare Jazza and DALL-E 3, I took three "prompts" from his video and fed them to DALL-E 3 word for word. I didn't provide any additional hints or context. Here are the results. The left half of each image is what Jazza came up with3. The right is DALL-E 3’s interpretation of the prompt. The caption underneath each is the prompt used (Note that Jazza was given a bulleted list, and that's the same format I used with DALL-E 3).



Not bad, right? It's got most of the details down in the three examples4. In case you're wondering, the three characters are Dolores Umbridge, Sherlock Holmes, and Edward Cullen.
However, I observed something funny once I entered prompts into the ChatGPT interface5. DALL-E 3 took about a minute to generate four pictures per prompt. When I zoomed in to spot the mistakes, I noticed that my prompt had been modified.

Jazza's prompts were sparse and to the point. For example, this is the prompt I entered for the Sherlock Holmes image:
Middle-aged man
Gaunt and tall
A "thin, eager face" with a long thin nose
Black hair, grey eyes
cloth cap and tweed suit
Heavy, dark, bushy eyebrows
Look at how the prompt was changed by ChatGPT:
"Illustration of a tall, middle-aged man with a gaunt appearance. He wears a tweed suit and a cloth cap. His black hair is complemented by his grey eyes, and he has a thin, eager face with a prominent long nose. His dark, bushy eyebrows stand out."
Doesn’t it feel much more conversational versus reading like a laundry list? The same thing was true for the other pictures. The wording was different for each result. It turns out that DALL-E 3 uses descriptive prompts.
Do you know what's even more interesting? It used GPT-4 to convert my barebone prompt into a descriptive paragraph6!
Why did this happen? This is OpenAI's solution for an issue that has plagued generative models for a while– Prompt following.
Lost in Translation
For the longest time, text-to-image models have suffered from a controllability issue. They overlook words, the order of the words, and sometimes even the meaning of a caption. Collectively, these issues are called "Prompt following."
Why does this problem exist, though? There are two major reasons.
The first is that most captions used to train these models are written by authors who focus on simple descriptions. Such descriptions just state the subject of the image and omit background details or other relationships like the presence of other objects, the positions of these objects, colors, sizes, and so on7.
The second is more egregious. Images scraped off the internet are often paired with alt-text that comes with them. These end up either being grossly incorrect or describing something tangential. For instance, have a look at the alt-text for the images below. These have been taken from DrawBench, a challenging benchmark dataset for text-to-image models.

Can you imagine the embedding space resulting from training a model on these "captions"?
My pick of the bunch from the dataset though is this gem (not pictured above):
"A smafml vessef epropoeilled on watvewr by ors, sauls, or han engie."
This was probably typed one-handed by a good samaritan while driving an Uber during rush hour8.
Even Jazza, when asked to draw a "smafml vessef epropoeilled on watvewr by ors, sauls, or han engie", would be just as puzzled as you or me.
To get around these challenges, prior research has tried conditioning on pretrained language models or scaling autoregressive image generators. Expert prompters have spent countless hours figuring out specific phrases or formats to make these models dance to their tunes. Unfortunately, the average user has had to learn these secrets from them for a hefty fee or be content with a mixed bag.
Preferring to try something different, OpenAI trained its generative model with better captions instead. On face value, I like that approach a lot. But how do you create captions for millions of images? Also, what do you mean by "better"? Let's address these questions next.
Caption Crunch: Now, with 95% Artificial Text
Recaptioning a large set of images is hard enough. Recaptioning 1 billion of them with descriptive text might span one's entire lifetime in front of a keyboard. Thus, the authors build an image captioning model.
Using a pretrained CLIP image embedder, they produce embeddings for each image. This, along with a language modeling objective, allows them to train the captioning model to produce good captions9.
So, given an image, the model can now provide a caption describing it. Problem solved, right? Not quite.
This caption generator still produces very succinct captions. While it solves one of the problems (read horrendous alt-text), it doesn't solve the other– A need for descriptive context.
The authors further fine-tune10 this model in two ways. First, they build a small dataset of captions that only describe the main subject of the image. Once fine-tuned with this data, the captioning model (a.k.a captioner) produces captions biased toward describing the main subject of each image. These are called "short synthetic captions (SSC)."
They repeat this process a second time, creating a dataset of long, highly descriptive captions that describe the contents of each image in the fine-tuning dataset. These not only describe the subject but also its surroundings, background, text found in the image, colors, etc. The captioner resulting from finetuning on these longer captions produces what the authors call "descriptive synthetic captions (DSC)."
Now, I have no idea what the size of the small dataset is, how it was curated, or other details, as these were absent from the paper. Let's now look at the same three images from before, but this time with their SSCs and DSCs.

The captioner does a great job describing these images. In particular, the DSC captioner puts Wordsworth to shame.
With these artificial minions in hand, the authors generate synthetic captions for every image in the original fine-tuning dataset.
Conditions Apply*
Text-to-image models have a tendency to memorize quirks in the training data. In fancy speak, this is called "overfitting to distributional regularities in the dataset." For example, if the model is trained on captions that always start with a space, they won't work properly if the user provides a caption that doesn't start with one.
Why is this important?
The captioners (SSC and DSC) produce synthetic or artificial data. This data has its own quirks and biases. For instance, they could always end captions with a period or always start them with "A" or "An." Now imagine training something like DALL-E 3 on this and releasing it to a sea of users. What's the guarantee that the way you or I prompt exactly matches the style of these synthetic captions?
To address this gap, OpenAI blended "real" captions (the captions that originally existed for each image) with the "artificial" captions they generated. The blending itself happens when an image is picked for training the model. The ground truth or synthetic caption is chosen randomly (with a fixed percent chance).
This process adds some regularization, preventing DALLE-3 from overfitting to the quirks in the synthetic captions.
The next question you might ask is, "What is the right balance between real and artificial?". If you're asking me about food and drink, the answer is 100% real and 0% artificial. If you're asking me about captions, then OpenAI says that using 95% synthetic captions gave them the best results, as shown below.
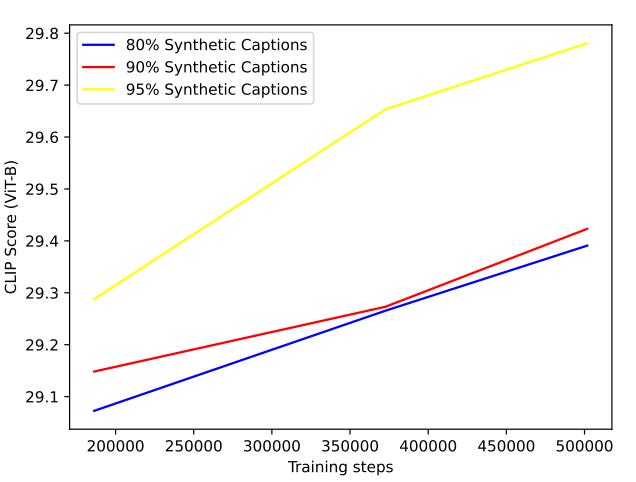
DALL-E 3
It might feel weird being introduced to the new model this deep in the article, but honestly, there's very little information that OpenAI has shared about the model. They state that the improvements in its generative abilities don't come purely from training on synthetic captions but are also due to improvements in training and the size of the model itself. There are some hints about the architecture in the appendix, but I encourage you to check the paper out for yourself.
In this section, I'll dissect how DALL-E 3 stacks up against its competitors, the evaluation methodologies, and a nifty trick that I think is already being used in production.
How Good Is It at Generation?
The authors used the CLIP score to measure generation quality. In simple terms, it does the following. First, it passes the caption through CLIP's text encoder to get a text embedding. Next, it passes the generated image through CLIP's image encoder to get an image embedding. Finally, it compares their similarity using the cosine distance11. The higher this score, the better the model.

In the left image above, we have three models evaluated on "real" captions. We have the same three models evaluated on descriptive synthetic captions on the right. As can be seen, models trained using synthetic captions, and descriptive ones in particular, have better generative quality regardless of which type of captions they are evaluated on.
How Well Does DALLE-3 Follow Prompts?
Over a number of benchmarks, DALLE-3 outperforms its predecessor, DALLE-2, and Stable Diffusion XL. Some of these results were evaluated by the recently announced GPT-V model, so take them with a grain of salt.

What Do Humans Think?
After all, if a model is quantitatively dope but qualitatively sucks, what good is that? For this, human raters score DALL-E 3 and its competitors on three axes:
Prompt Following: Given two images and a caption, "choose which image better corresponds to the caption."

Style: Which image would you prefer if you were using a computer tool to produce images from text?

Coherence: Which image contains objects that plausibly exist? We all have nightmares from seeing warped fingers, faces, and objects floating in unusual places, don't we?



Overall, DALLE-3 beats its competition hands down on all three fronts. The numbers you see in the table below are the ELO scores, which are a way to measure how many times one model beats another12.

What About Non-Flowery Language Writing Humans?
So far, all the evidence we've seen indicates that DALL-E 3 works well with descriptive captions. We also know that DALL-E 3 can overfit to quirks in the synthetic captions it's seen during training, which mainly consists of descriptive text. So it’s bound to expect descriptive captions, right? But real-world humans don't always prompt that way.
What's the solution?
Well, what has no thumbs yet types paragraphs and paragraphs of flowery text without shutting up?
That's right! GPT-4.
So, OpenAI uses models like GPT-4 to "upsample" captions into a format that DALL-E 3 is familiar with.

In fact, I suspect that this is why my prompts in the Jazza experiment were being automatically modified. Upsampling a prompt not only adds missing details but also helps disambiguate complex relationships. This is a cool trick that OpenAI may have used to help out DALL-E 3 in production.
Limitations and Implications
Now, DALL-E 3 isn't perfect. It struggles with spatial awareness. Phrases like "to the left of," "underneath," and so on don't work well because the synthetic captioner isn't reliable at placing objects in an image. While it is somewhat better at rendering text, it still is unreliable on occasion. It also can hallucinate important details about an image. For example, the synthetic caption might contain hallucinated names for the genus or species of a flower or plant. These are issues coupled with the text encoder and hopefully will be addressed in the future.
The good news is that DALL-E 3 is a step towards removing specialized prompts. This can open up a wealth of applications. Imagine a couple going to an interior designer and using a generative tool to explain their ideas. Imagine an Indie game developer creating all the artwork she needs from mere conversations with a chatbot. Imagine how an average Joe could unlock his artistic capabilities without formal training. Imagine how seasoned artists can get out of a creative block by sparring with a bot. The possibilities are endless.
The bad news is that DALL-E 3 makes it easier for large corporations and individuals alike to replace artists. After all, it's easier and cheaper for them to use generative AI. To add salt to the wounds, these models were trained on the artists' work in the first place. While DALL-E 3 has an opt-out form where creatives can ask for their work to be removed from training data, this shouldn't even have to be the case in the first place. In the short term, we'll see situations like the recent Hollywood strike play out more frequently. In the long term, we'll have to see what happens.
Models like DALL-E 3 offer a glimpse of a future filled with unlimited possibilities but also cast a dark shadow of ethical complexity we shouldn't ignore. Pandora's box has already been opened. It's up to us to ensure it doesn't close on the values we hold dear.
Resources To Consider:
AI Tool Searcher
I recommend checking out AIModels.fyi. It's a free tool that lets you discover, select, and integrate the perfect AI tool for your project. They also have a newsletter with a summary of the top new models, research summaries, and helpful how-to guides. Click here to see for yourself.
What Does the AI Revolution Mean for Our Future?
This debate between Yuval Noah Harari and Mustafa Suleyman on AI's implications is very interesting to watch. I recommend checking it out when you have some spare time.
References from the Deep Dive
Prior Work:
DALLE-2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Pretraining the Captioning Model: CoCa: Contrastive Captioners are Image-Text Foundation Models
Evaluation Metrics:
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
(Elo Score) Glide: Towards photorealistic image generation and editing with text-guided diffusion models.
DALL-E 3 Papers:
Main paper: https://cdn.openai.com/papers/dall-e-3.pdf
System Card: https://cdn.openai.com/papers/DALL_E_3_System_Card.pdf
Footnotes
His team compiled the prompts so that he wouldn't know which book the character was from.
Don't tell me you haven't used "8k resolution, trending on artstation, 50mm lens" at least once!
These are his "quick" sketch versions screenshotted from the video to compare with Dalle-3. You don't want to see my quick sketch versions, believe me.
It got the velvet bow right but colored it green instead of black, for example. At the same time, it nailed the eye color, length, and shape of the hair.
Yes, DALL-E 3 is integrated into ChatGPT, so prompting it is as easy as typing something into the chatbot. Also, for each prompt, it produces four images. I picked the one that looked like an "illustration" versus others that were more photographic.
It appears that this happens regardless of whether you give it fragmented phrases or entire paragraphs. GPT-4 massages the prompt before giving it to DALL-E 3.
In fact, one of the main reasons text-to-image models suck at drawing text is because the captions in the training data often omit them.
Don't text and drive, especially if this is what you text.
The image embedding provides a compressed representation of the image, and the language modeling objective ensures that the model predicts the next word in the caption correctly. This isn't a novel approach and was proposed by this paper: https://arxiv.org/abs/2205.01917
Finetuning here refers to the captioner. Not to be confused with fine-tuning the text-to-image model. There are two models at play. A captioner that generates synthetic captions for a large image dataset, and a DALLE-3, which is trained on the synthetic captions generated by the former.
The final value is rescaled by 100 in the paper.
Not to be confused with the ELO rating from Chess 😀. The ELO score computation for image generation models is a bit more nuanced, but I wanted to give you a broad idea
Oh my these memes are so good woven in with your words. Delightful and insightful as always my friend! Going to try this after cohort is over.