

Vision Transformers: From Idea to Applications Part I
Exploring one of the most versatile deep learning architectures

In the previous issue, I promised to share two surprises in the next couple of editions. Here is the first of them!
I'm delighted to share with you that for the next three weeks, Cameron Wolfe and I will be collaborating to bring you a six-part series on the Vision transformer and its many applications. I will cover parts 1, 3, and 5, while Cameron will cover parts 2, 4, and 6.
Cameron writes one of the most comprehensive newsletters on Deep learning and covers cutting-edge research in this field like few can. I'm thrilled to partner with him on this series, and I hope this brings you as much fun reading it as we had writing it. Be sure to check out and subscribe to Cameron's newsletter, Deep (learning) focus here:

This Week on Gradient Ascent:
Pay attention to the Transformer 🤖
[Must read] The illustrated transformer 🎨
[Check out] A transformer course from 🤗
[Consider reading] A comprehensive catalog of transformers 📑
"Attention-grabbing" Transformers:
Before 2017, if someone asked you if you'd ever heard of Transformers, your response would probably be one of the following: a) The Optimus Prime stuff? b) Yeah, they help transfer electricity to my home, right? c) Umm.. no. Why?

If I venture to ask you now, you'd say, "Get with the times," and go all ChatGPT on me. It's an understatement to say that transformers have revolutionized deep learning and, in the process, modern technology as we know it. While sadly, they won't transform into a truck anytime soon, they will transform the applications you build, whether it be in language, vision, or any other domain.
Let's look at the Transformer's origin story and what makes it tick.
Don't you remember?
Before the existence of transformers, language models primarily consisted of Recurrent Neural Networks (RNNs), Gated Recurrent Units (GRUs), and Long Short Term Memory units (LSTMs). These architecture types (a.k.a Seq2Seq models) had a few limitations. For instance, RNNs had poor memory. If you gave them a long sentence, they'd forget the important information in the first part of the sentence. Kind of like the guy in Memento. They also suffered from vanishing/exploding gradients. During backpropagation, the weights wouldn't update properly because the gradient that worked its way back would either be insignificant or infinity. Thus, the model couldn't learn properly.
To alleviate this, GRUs and LSTMs were employed. They had gates to store and use past information. To their credit, they did a lot better than RNNs. But they too were not without flaws. First, they relied on sequential processing. Every sentence was processed word by word. You couldn't train them using parallel computing. Thus, they were slow to train and use. More importantly, though, they relied on what's called the Markov property when using past information. This states that the current state only depends on the previous state. So, after a few steps, earlier words in a sentence wouldn't have a significant impact on later words. Thus, they couldn't see the whole sentence in context.
Imagine you saw two sentences like the ones below. Only one word changes at the end. But, the meaning of the two sentences changes dramatically. Especially when it comes to the word "it".

These models would struggle with sentences like this. The solution?
Paying more attention
To allow these models to deal with long sentences, a technique called "Attention" was introduced. Equipped with attention, these same models could now focus on whatever was relevant, and thus their performance dramatically improved. In other words, attention increased the memory of these models. While going into the details of all kinds of attention mechanisms is beyond the scope of this piece, we'll look at one particular form of it.
But before that, there's a lingering question that's been left unanswered. If attention was really all you needed and using it with Seq2Seq models fixed their memory limitations, why was the transformer even necessary?
The answer lies in speed. Despite the fact that attention rejuvenated these relics like a 2014 Mac Pro whose RAM has just been significantly upgraded, these models had a gravity problem. Nothing can be done to change gravity pulling us down. In the same way, these models couldn't be parallelized. They were way too slow.
That's precisely the biggest impediment that the Transformer addressed (besides being awesome at what it did).
Attention is all you need
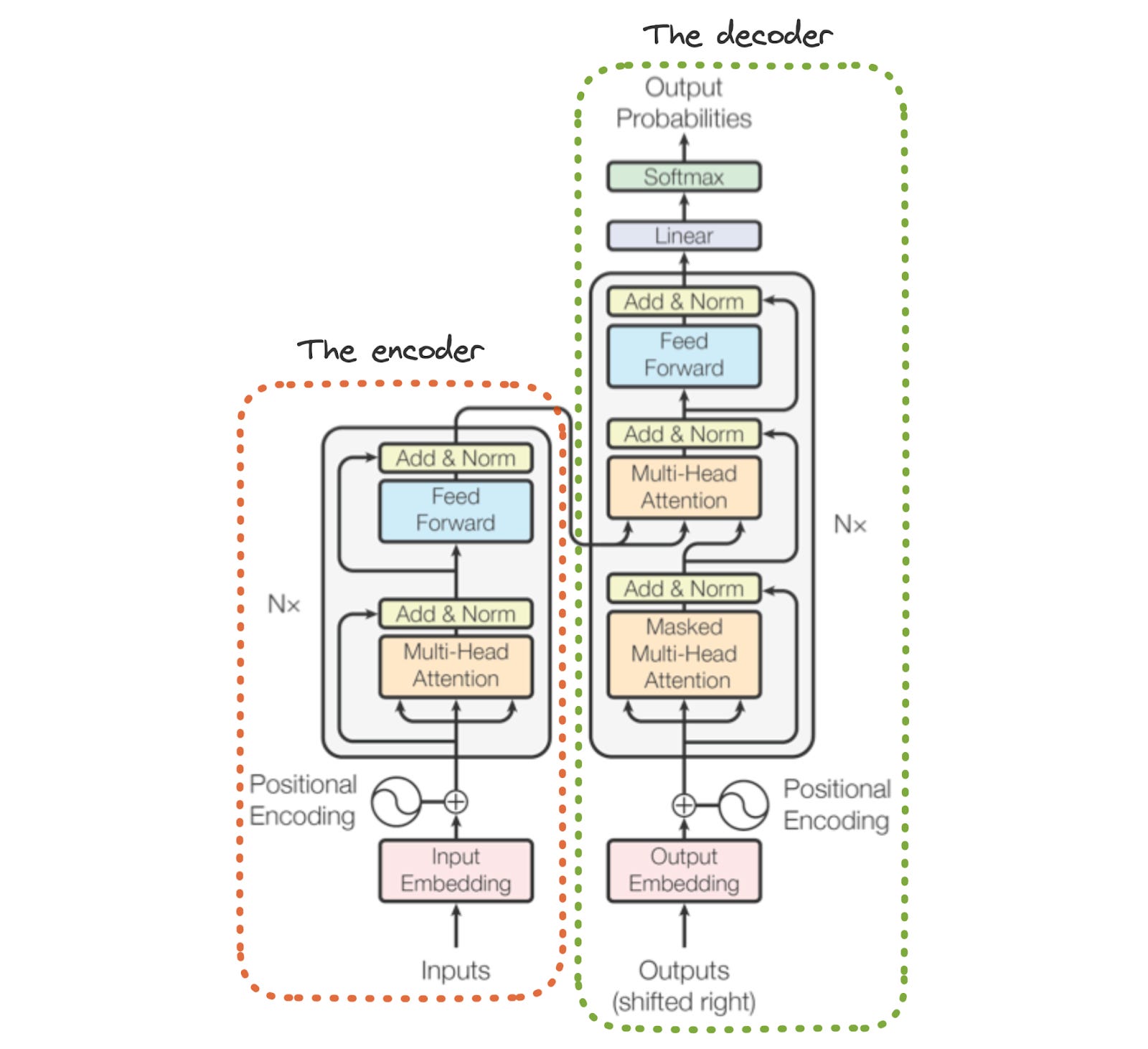
In 2017, researchers from Google published this paper. As of this writing, it's been cited over 66,000 times. The transformer architecture was born. If you peel open the transformer, you'll see that it consists of an encoder and a decoder. Both of these use attention mechanisms heavily. In its original form (pun unintended), it was designed to translate sentences from one language to another (Sequence to sequence translation). Today, it's capable of much more than its humble beginnings.
At a high level, the encoder extracts features from the input sentence in one particular language, and the decoder uses this to generate outputs in the desired output language. This is what the transformer looks like.
To motivate just how good the transformer is, here is what it focuses on in the two sentences I shared above.

In the first sentence, the Transformer knows that "it" refers to the animal (The darker the shade of blue, the stronger the connection between two words). Similarly, in the second sentence, it knows that the "it" refers to the street. Thus, it translates the sequence from English to French easily, as shown below.

Since this series will deal with the Vision transformer (and it has no decoder), I'll skip the details of the decoder in this piece. Let's now look at each component of the encoder in detail.
Input embeddings
In the previous issue, I covered embeddings in detail, so I'll keep this brief. Given a word, the embedding layer converts it into a vector of numbers that represent the word. The embeddings themselves are learned during the training process.
Positional encoding
Since transformers aren't recurrent in nature like RNNs, they have no positional information about the words themselves. That is, they don't know the order of the words in the sentence. Thus, the positional encoding layer "encodes" this information, allowing the transformer to learn the position of each word and where it lies relative to other words in the sentence. In the paper, the authors used sine and cosine function1 to encode positions (although they claimed that learned positional encodings performed just as well).
Multi-head attention
So far, we’ve seen how the transformer converts words to numbers and maps their positions in a sentence. At this juncture, it has word vectors with positions encoded. We now come to the heart of the transformer. Attention layers allow the transformer to map each word in the input to every other word to learn relationships. Don't be intimidated by all the fancy terms in the diagram. Let's break each one down piece by piece.

Self-attention
The terms self-attention and scaled dot-product attention are used interchangeably here. If there's one thing you take away from this piece, let it be this— Self-attention measures how much focus a word should put on other words in the sentence. To compute this, it does the following steps.
Create 3 new vectors from each input word vector called Query, Key, and Value vectors. These are denoted by the Q, K, and V symbols in the diagram. They are obtained by multiplying the input word vector with three sets of weights learned during training.
Use the query and key vectors to compute a score. This score determines how much focus to place on other words in the sentence for a given word.
Scale the score by a constant so that its value is under check (stabilizes training)
Normalize the score using a softmax function so that each score is positive and the sum of the scores of all the words in the sentence adds up to 1.
Multiply this score with the value vector to calculate the attention value.
Mathematically, this is represented as follows:

Intuitively, this keeps the words we want to focus on and diminishes the importance of all the irrelevant ones. Remember the image with the blue shades above? The intensity of the blue shade represents the attention value. The more intense the blue, the higher the attention value.
But what are the query, key, and value vectors for in the first place? Think of it like this. The query represents the current word. The key represents all the words in the sentence. The value represents the content of each word. The score in step 4 represents the strength of interaction between the current word and other words in the sentence. This score, when multiplied by the value vector, determines how much a word contributes to the final result.
To drive this point home even further, here's an analogy. Imagine you have a file cabinet containing dossiers of different animals. Let's say that these animals are the elephant, lion, chipmunk, platypus, and whale. If I ask you to find information on African mammals, you'll retrieve the elephant and lion and keep the rest where they are. Here the query is "African mammal". The keys are the animals. The values are the contents of the dossier. The attention score measures how much the contents of each dossier contribute to the final result, which in this case primarily consists of elephant and lion photographs (yay!).
Let's return to the multi-headed notion of attention. What does that mean? Simple. Instead of using just one self-attention layer, the encoder consists of several such layers stacked together. Why? This enhances the model's ability to focus on different positions within the sentence. It also enables the model to learn richer representations of language.
In fact, a paper studied what the self-attention heads looked at and found some fascinating results. Some attention heads looked at periods, others at commas, some others at every second word, and so on. The model learned to do this on its own! Clearly, multiple attention heads are to the transformer what spinach is to Popeye.
Other parts of the encoder
Let's quickly look at the remaining parts of the transformer encoder.
Residual connections & normalization layers
Residual or skip connections (borrowed from computer vision) and the layer normalization layers (add & norm in the diagram above) improve training stability and prevent the vanishing gradient issue referenced above. Layer normalization also speeds up training.
Feed-forward layers
These are just two linear transformations separated by a ReLU activation function. In simple terms, they help model complex representations and extract rich features from the input.
The encoder tower
What we discussed above is the contents of a single encoder block! The actual encoder itself has many of these blocks connected together. After all, we're in the age of large language models. These wouldn't be large if they didn't have many layers. In the original paper, the encoder had 6 of these layers connected together. In most modern architectures, that number is significantly larger.
Since they primarily consist of attention layers, transformers are incredibly parallelizable. Thus, they run blazing fast when compared to traditional Seq2Seq models while delivering top-notch performance.
A picture is worth a thousand words
In this piece, we've restricted ourselves to studying the transformer as it was designed for language processing. But, the transformers had ulterior motives. They wanted to rule the world. In fact, they knocked off convolutional networks, which were the kings of the hill for images. How and why?
Over to you, Cameron.
Resources To Consider:
The Illustrated Transformer
Link: https://jalammar.github.io/illustrated-transformer/
Goes without saying that this is *the* guide for learning about transformers. Jay also has a video that walks through the transformer architecture in a very intuitive way. Definitely check this out to learn the working of the full transformer model.
A Transformers Course from 🤗
Link: https://huggingface.co/course/chapter1/1
To supplement your learning, check out this free course from HuggingFace, which teaches you how to use their transformer library. This is the defacto industry standard for anything related to transformers. By the end of the course, you'll be able to build models and applications using this library.
A comprehensive catalog of transformers
Paper: https://arxiv.org/abs/2302.07730
Xavier Amatriain, VP of AI product strategy at LinkedIn, created this excellent transformers catalog. These models have grown and expanded ridiculously fast, so this encyclopedia is extremely valuable as a reference to keep track of the evolution and variants of this model.
The details are interesting as to why they used this, but I’ll skip that for now.