

Vision Transformers: From Idea to Applications Part V
Can a transformer paint a pretty picture?

This is part five of a six-part series that Cameron Wolfe and I will write on the Vision transformer and its many applications. I will cover parts 1, 3, and 5, while Cameron will cover parts 2, 4, and 6.
If you just got here and missed the earlier parts, here they are:
Cameron writes an incredible newsletter on deep learning and covers cutting-edge research. Be sure to check out and subscribe to Cameron's newsletter, Deep (learning) focus, here:

This Week on Gradient Ascent:
The digital Picasso 🤖
Vision Transformers: From Words to Worlds

Do you remember your art lessons from middle school? At least in the subcontinent where I'm from, it used to be a welcome respite from the monotonous schedule of science and social studies, the latter precisely placed right after a lunch break. But, try as we did to remain awake and recount the stories of our ancestors, our eyelids always came down with the force of a baling press.
Then came art. Oof!
Just as the aroma of a freshly brewed cup of coffee wafts into your nostrils awakening every last neuron, walking into the art room resuscitated my senses from their hibernation.
I remember three exercises in particular from many that our art teacher gave us. The first of these was painting with numbers. The second was show-and-hide. The third was painting from guided imagination. Allow me to explain. As kids, our ambitions were significantly loftier than our artistic abilities. So we needed to work (a lot) on the latter if we were going to get close to the former.
Painting with numbers honed our skills to associate specific colors with specific objects. Our teacher would give us each a sheet of paper prepopulated with a sketch. The sketch itself would have numbers in various sections. We'd also get paint bottles with numbers on them. Our job was to match the numbers on the paper and the bottle. This practice built up a color-object vocabulary.
Show-and-hide was a simple exercise. First, we'd be shown something like a bowl of fruit for a few minutes. This would then be hidden from us. Next, we would have to paint it from memory. This built up recall and shape vocabulary.
Painting with guided imagination took this to the next level. This time, we were given a blank sheet of paper and asked to draw and paint from scratch. However, our teacher gave us cues like "Draw a bird on a tree" or "Show me a soccer game." But, having already practiced painting with numbers and show-and-hide, we were able to create these illustrations easily. This taught us how to create shapes and put them next to each other and appropriately color them.
Sometimes we didn't know how to draw something because we'd never heard of an object before (say, a wicker basket, for example). But, the more we were exposed to new objects, colors, and concepts, the larger our artistic vocabulary grew.
Where am I going with this?
Modern generative models (the diffusion kind) sort of learn in the same way. We give them a giant dataset of images and captions. While training them, we show them what a word "looks" like. We show them a wide variety of words and their associated images. Often multiple objects are juxtaposed in these images.
But we don't stop there.
We hide parts of these images (usually with noise) and ask them to reconstruct the missing pieces from memory. This process repeats at an increasing level of difficulty. First, a small part of the image is hidden. This is easy-peasy for the model. Then, we hide some more. Then, some more. As more and more of the image is hidden, the model needs to figure out how to paint the missing parts back. Eventually, the model learns to reimagine a completely obscured image.
This practice enables these models to learn their artistic vocabulary, also known as the latent space.
Once these models are trained in this manner, they, too, can create art from the cues we give them. These cues are what we call prompts.
Just as we kids who had never seen an object before might struggle painting one, these models have difficulty generating objects they've never seen. But with exposure to more and more diverse data, these models learn how to create images from sentence fragments.
Diffusion models have taken text-to-image generation to the next level in terms of quality and flexibility. But they still take some time to produce these results. In this week's edition, we'll be looking at a transformer model that does incredibly high-quality text-to-image generation but is also fast at the same time.
Let's look at Muse, Google's latest image generation model.
AMuse bouche:
Muse is a fast text-to-image transformer model. It's not just significantly faster than other comparable models but also incredibly good at the generation bit! Here are some sample images that Muse generated. The caption for each image is the prompt that was given to the model. Impressive huh?

But just how fast is Muse? It takes 1.3 seconds to generate a 512 x 512 image and a third of that time to generate a 256 x 256 image1. Per the authors' benchmarks, other models take several seconds more. See the table below2.

How does it work this well? To find out, we need to peel open the layers of the onion.
Discretely transforming text into images
Unlike other diffusion models, which use a continuous pixel space to generate images, Muse uses discrete tokens instead. This is the first reason why it's faster. The second reason why it's faster is because of a technique called parallel decoding. We'll look at both of these below. But first, what does Muse look like, and how is it trained?
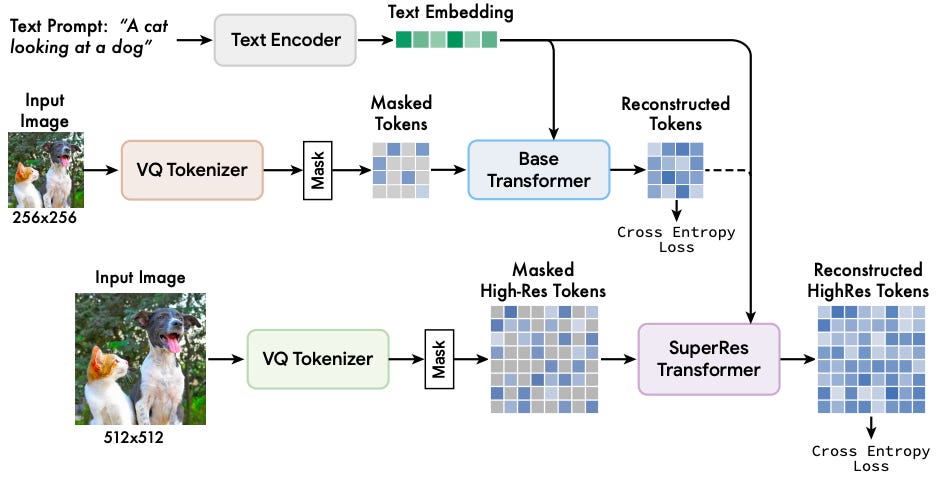
At a high level, here is what happens. First, a caption is fed to a text encoder (up top) to extract text embeddings. The text encoder is a pretrained large language model called T5-XXL (T5 stands for Text-To-Text Transfer Transformer. Step aside, Peter piper picked a peck of pickled peppers).
The benefit of using this large language model is that it can model rich context about objects, actions, visual properties, and spatial relationships. As shown in the figure, these embeddings are projected onto the Base transformer.
The Base transformer's job is to reconstruct a masked image, i.e., fill in the blank spaces in an incomplete image based on the remaining parts of the image and the text embeddings.
Once the Base transformer has been trained, the reconstructions it produces and the text embeddings are fed to a SuperRes transformer (Super-resolution for 0.000001% of you wondering what SuperRes is). The SuperRes transformer plays the same reconstruction game as the Base transformer but at higher stakes. It has to produce a higher-resolution reconstruction as output.
There are some things we've skipped thus far. For example, how do we mask the images? How do we train the transformers for reconstruction? What is the VQ Tokenizer?
Yes V(Q) GAN
Let's look at an autoencoder first. This network consists of two networks, an encoder, and a decoder. The encoder takes an image and compresses it into a smaller representation. Essentially, this representation is a set of numbers. The decoder takes this set of numbers and tries to reconstruct the original image. In a sense, the compressed representation contains the most important features of the image and discards the less important ones.
A variational autoencoder learns a probability distribution from the input data, which allows it to generate new samples. But there is a problem. The latent space here is continuous, meaning that this model can learn a ridiculously large number of possible latent vectors.
This is where Vector Quantized Variational Auto Encoder (VQ-VAE) comes in. This model converts a continuous latent space into a discrete latent space representation. Let's say that the VQ-VAE takes an image, and its encoder produces a vector. Instead of using this vector directly to represent the image, the VQ-VAE compares it to a codebook of vectors. A codebook is just a finite collection of vectors that are learned. The "VQ" part of the VQ-VAE replaces the original vector from the encoder with the nearest or closest vector in this codebook to represent the image.
This allows the VAE to focus on learning a few vectors (the ones in the codebook) well versus learning an enormous number of vectors in the latent space.
Where does the GAN come in here? The VQ-GAN takes a VQ-VAE and adds a discriminator network into the mix. The discriminator takes the original image fed to the encoder and the reconstructed image from the decoder and predicts which is real and which is reconstructed. This feedback signal allows the encoder and decoder to improve the quality of the vectors and reconstructions, respectively.
The real goal, though, is to generate new images. For this, a transformer is used in the VQ-GAN. The transformer determines which codebook vectors fit together and can combine them to create new ones. So if you want to generate a picture of a blue car on the road with green hills in the background, you just need the codebook vectors for the blue car, the green hills, and the road. While this is an oversimplification, it helps get the main point across.
For a detailed explanation of the VQ-GAN, check out this amazing video:
Returning to the Muse model, the VQGAN is used to get semantic tokens that can be fed to the Base transformer and the SuperRes transformer. The authors train two VQGANs, one for each transformer.
So now we have a way to convert the caption into embeddings and a way to convert images into tokens. The next step is to train the transformers!
Taming transformers
The authors use masked image modeling to train the transformers. Given an image, they simply obscure parts of it and ask the transformer what could possibly be hiding behind those regions.
Since we have discrete tokens from the VQ-GAN encoder instead of the image, masking involves replacing some tokens with a special [MASK] token instead. The transformer has to guess what the replaced tokens are. The tokens are then mapped into embeddings that the transformer can use and combined with 2D positional embeddings. Since this method uses discrete tokens (yay!), the authors can use a standard cross-entropy loss function to evaluate the reconstruction. The specs of the Base transformer are shown below.

The SuperRes transformer also follows a similar training process. It is also trained with text conditioning and leverages cross-attention. The SuperRes transformer aims to upscale the reconstruction of the Base transformer. In other words, it needs to take the 16 x 16 latent map that the Base transformer generates and translates it to a 64 x 64 map, as shown in the figure below.

Since the SuperRes model takes in the output of the Base transformer, it is trained after the Base transformer has been trained. Then, the output of the SuperRes transformer is passed through the higher-resolution VQGAN decoder to get the final image.
Tricks to make Muse sing
The authors use a few tricks to squeeze out the last drop of generative goodness, which we'll look at next.
Decoder Finetuning
After the initial training process, the authors add a few more residual layers to the VQGAN decoder. However, they keep the rest of the setup - the encoder, the codebook, and the transformers frozen and fixed. Then, they finetune the decoder, and this results in sharper details.
Variable Masking Rate
This helps in out-of-the-box editing capabilities and parallel decoding to speed up inference speeds.
Classifier Free Guidance
During training time, 10% of the samples are chosen randomly, and the text conditioning associated with these samples is removed. This forces the model to rely purely on image-based self-attention. This improves the model's diversity at the cost of fidelity. It also unlocks the negative prompting mechanism.
Iterative Parallel Decoding
The authors use parallel decoding during inference time to predict multiple output tokens in a single pass. This increases the model's efficiency and is one of the key reasons why Muse is fast. The model chooses a fraction of the most confidently predicted tokens and makes them unmasked for the remainder of the inference process. This significantly reduces the number of steps needed to decode the tokens, leading to faster inference.
Editing Images with Muse
In addition to generating amazing images, Muse can also be used for editing applications like inpainting, outpainting, and zero-shot mask-free editing, as shown below.

Overall, Muse performs really well both from a quality and speed perspective. What will be interesting to see is if this idea can be extended to generating videos.
On a TPUv4
LDM denotes stable diffusion (and this was not benchmarked by the authors)
The art lesson "methodologies" (painting with numbers, show and hide, etc.) you described really fascinate me. I was never taught that way where I grew up in Canada. Maybe that's why I'm so terrible at art!